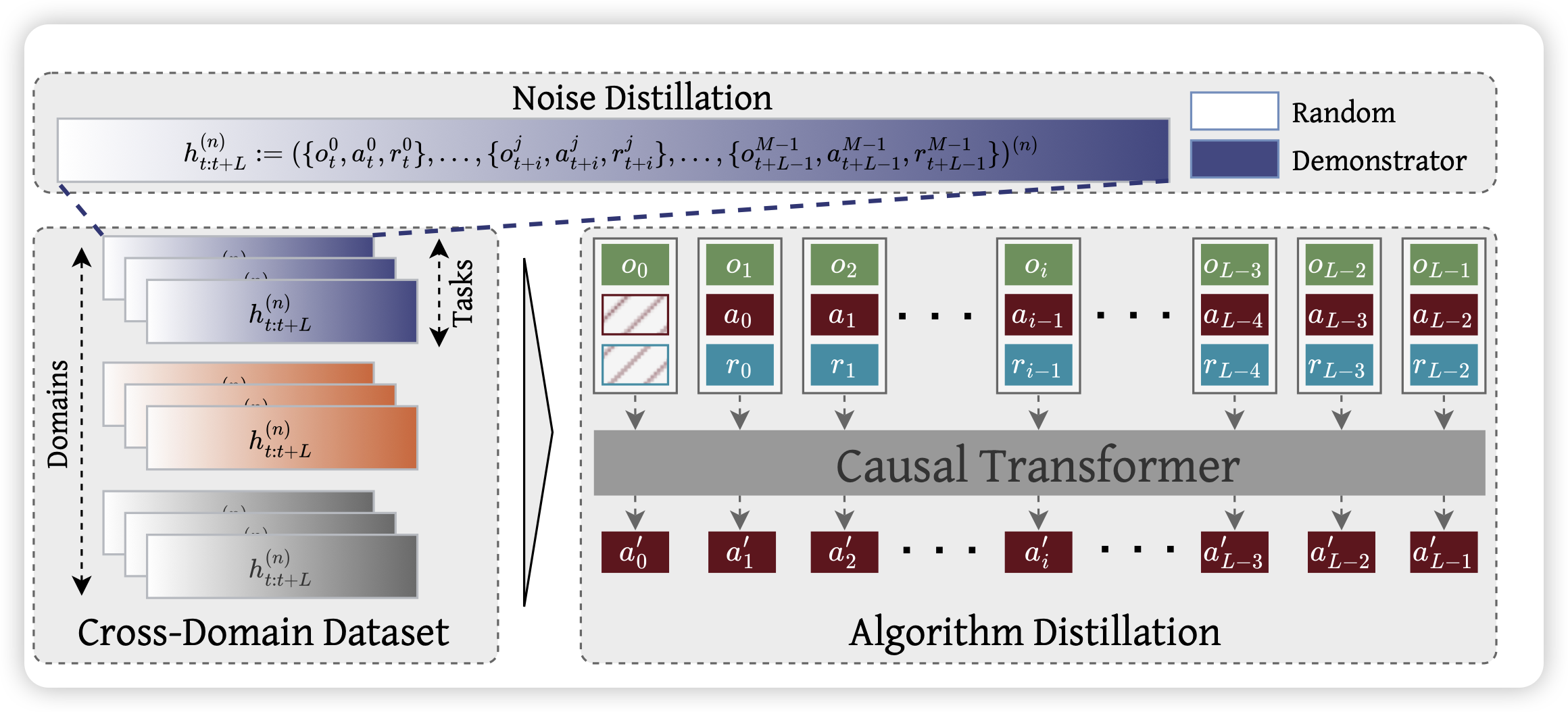
Vintix: Action Model via In-Context Reinforcement Learning
不知道大家有没有听说过in-context rl这个方向,他们是想要把rl的训练过程建模在一个context下,让模型可以在一个context里多次尝试、自我增强。这篇工作follow了之前一个很有名的叫algorithm distillation的工作,把他scaling到了多任务场景下,可以用一个模型同时in-context rl多种任务
我个人很喜欢这个方向,因为它本质上是把ppo等算法里,人工设计的探索和反馈的方式建模到了参数里,让模型学习自己去"重新发现"强化学习算法。感觉这个领域可能是未来从gpt到o1,再进一步的关键:人的参与再少一些……
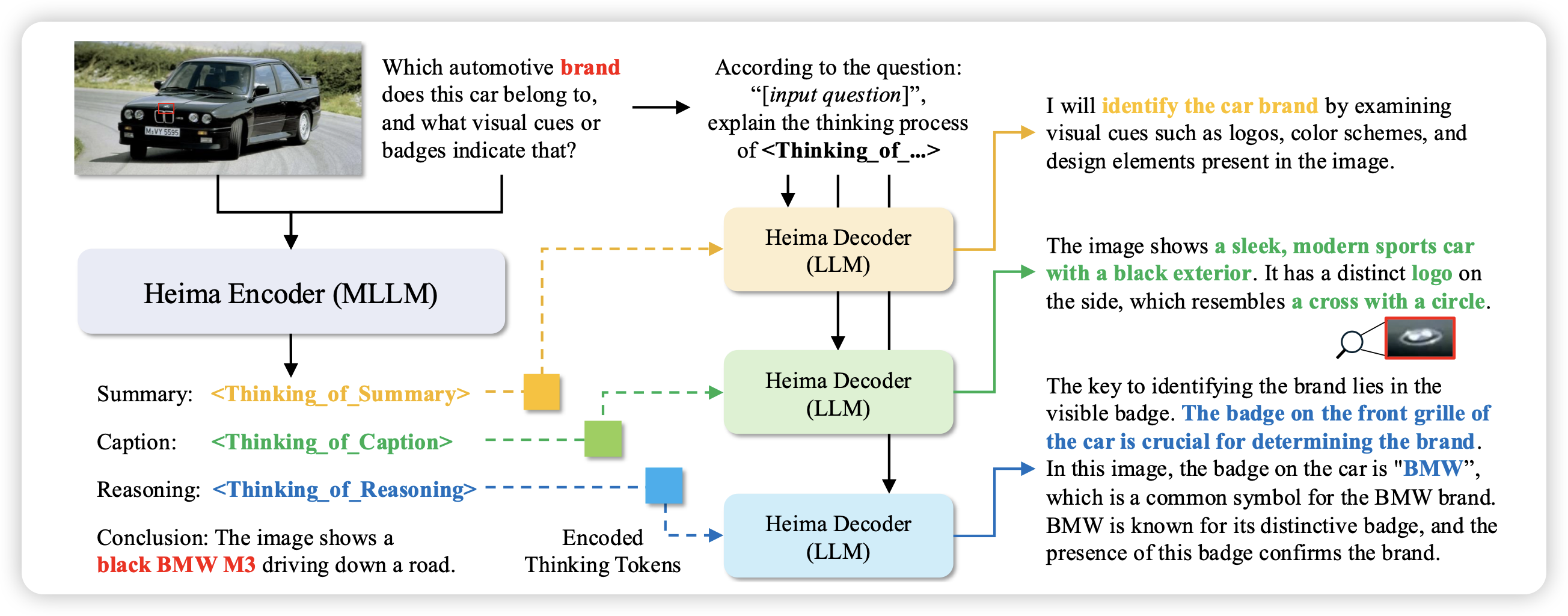
Efficient Reasoning with Hidden Thinking
这篇工作研究的方向可能有点争议:作者探索的是,模型能否在hidden state空间做推理(而不是在文本空间),让模型直接把output-state拼接到下一次的输入里,而不是走tokenizer离散成最接近的单词再转换成对应的词向量。之前有个叫stop-token的工作,还有个叫quiet-star的,做过类似的事情。不过这篇工作中,作者额外设计了decoder,可以把扁平化的hidden cot解码到文本空间
我之前follow过stop-token的工作,但是先不讨论这样做的效果会不会更好、推理效率会不会更高:我个人感觉这个很不安全呀,毕竟这个是真的hidden在了隐层表示里