Scaling Laws of Synthetic Data for Language Models
最近蛮少见scaling law的工作了,可能是都被公司挖走默默搞去了。作者研究的问题是,模型在合成数据上训练,效果什么时候会收敛?大致结论是,合成数据的效果收益来源于另一个scaling 曲线,看起来更平缓。然后越大的模型,需要越多的合成数据
一年多前,大家还觉得合成数据训练会“疯牛病”,后来发现是数据质量太差,现在又开始研究起scaling law了。所以,认知都是会随着时间的发展而改变的呀
Gemma 3 Technical Report
gemma3带着他10行的作者名单来了,是的,还有400M的vision encoder……能不能把前几天那个1B的原生双模态合版进来
话说现在的端侧模型已经涨到27B了吗。
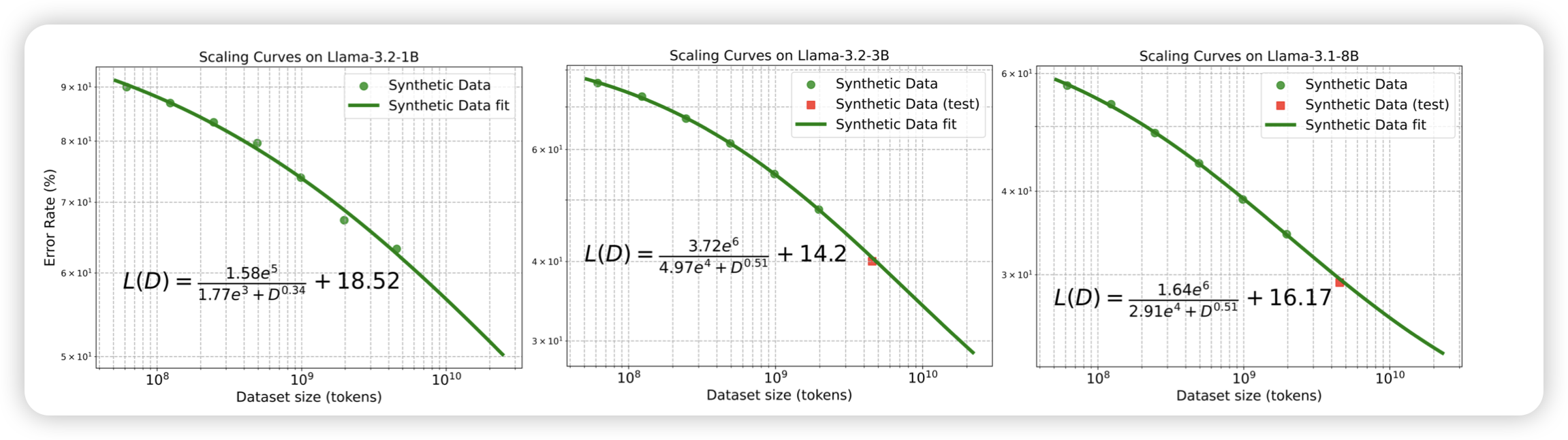
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
最近有一些做o1 + deep-research的工作,这篇算是看着比较顺眼的。作者行文有点致敬老前辈r1,然后就是在grpo里添加了一个search的action,揉在一起训练。把分摁上去了
话说deep research 里其实还能写代码来着……大家好像对这个都视而不见了