今天佳作频出呀
Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
很有趣的工作,感觉里面蕴含着深刻的道理:作者发现,在domain上finetune的模型往往会丢失泛化性。但是,这会不会是因为非知识性的原因呢?一个response的各种paraphrase都是一个意思,但ppl差的很多,如果让模型自己给训练集做一个paraphrase,让所有样本ppl都比较低了,是不是就不会让模型“扭转分布”了?作者发现还真是
但是,如果这个domain和预训练domain差的实在太远,导致paraphrase也无效咋办?是不是只能在预训练阶段掺数据了

Improving Pretraining Data Using Perplexity Correlations
这篇工作有点难评,不知道大家还记不记得之前分享过的observable scaling law,会根据不同LLM在leaderboard上的表现做协同过滤,算出来leaderboard的特征向量。这篇工作类似,找到一堆llm,一堆training corpus subset,根据每个LLM在每个training subset的ppl,和leader board上的表现作为训练数据,然后搞一个类似于regression的过程,算出来每个subset的权重,来做预训练数据配比调整
有点测试集泄露的嫌疑……但好像又没有。仔细想想doremi大概也是这么个路子,快进了

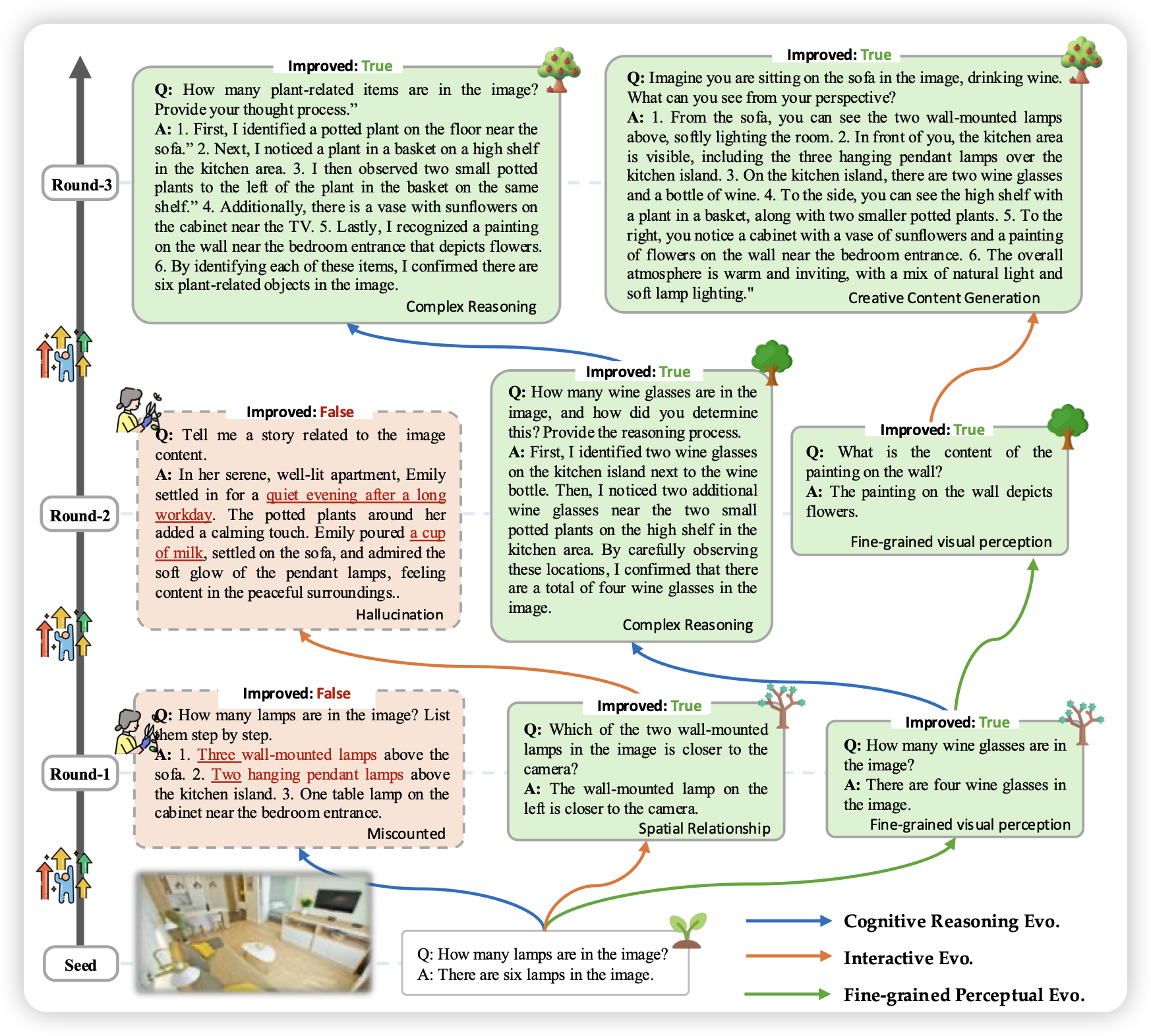
MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct
如果大家还记得Wizard LM,就是用一堆种子sft数据,多次迭代,每轮变难一点点。有人复刻了一个VLM版本的,开源了一个seed-163k SFT数据,效果还不错