最近赶上了CVPR截稿,挺多CV track的工作挂出来了
Everything is a Video: Unifying Modalities through Next-Frame Prediction
挺有趣的思路:作者发现,其实文字也可以用图片表示。能不能就搞一个词表,把text-only训练数据里面的文字画在图片里,然后统一用图片词表去编码解码。然后模型的训练任务只是单纯的next frame prediction呢?

AnimateAnything: Consistent and Controllable Animation for Video Generation
一篇视频生成的工作,作者主打了一个可控性的概念,可以控制物体运动方向、镜头运镜方向、文字控制内容样式等等

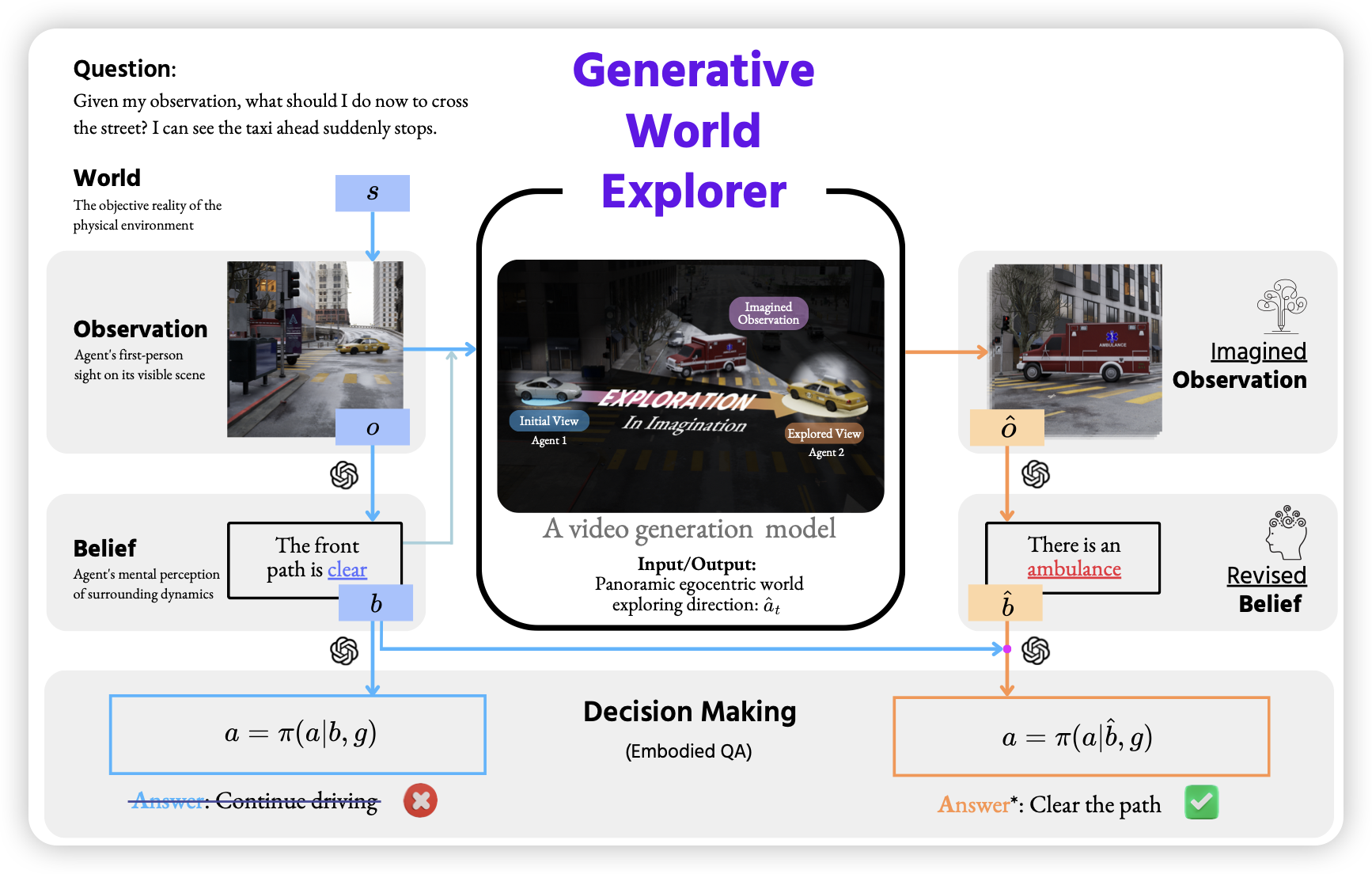
Generative World Explorer
这名字起得大气。作者认为,已有的agent工作基本都要把agent放置在真实环境里去交互学习。如果模型和人一样,具有想象能力,能不能让模型放置在一个类似于禅房、练功房的地方,自己去想象并学习呢?作者进行了一些尝试,用一个video generation model去模型世界,进而让模型学习,发现效果还可以
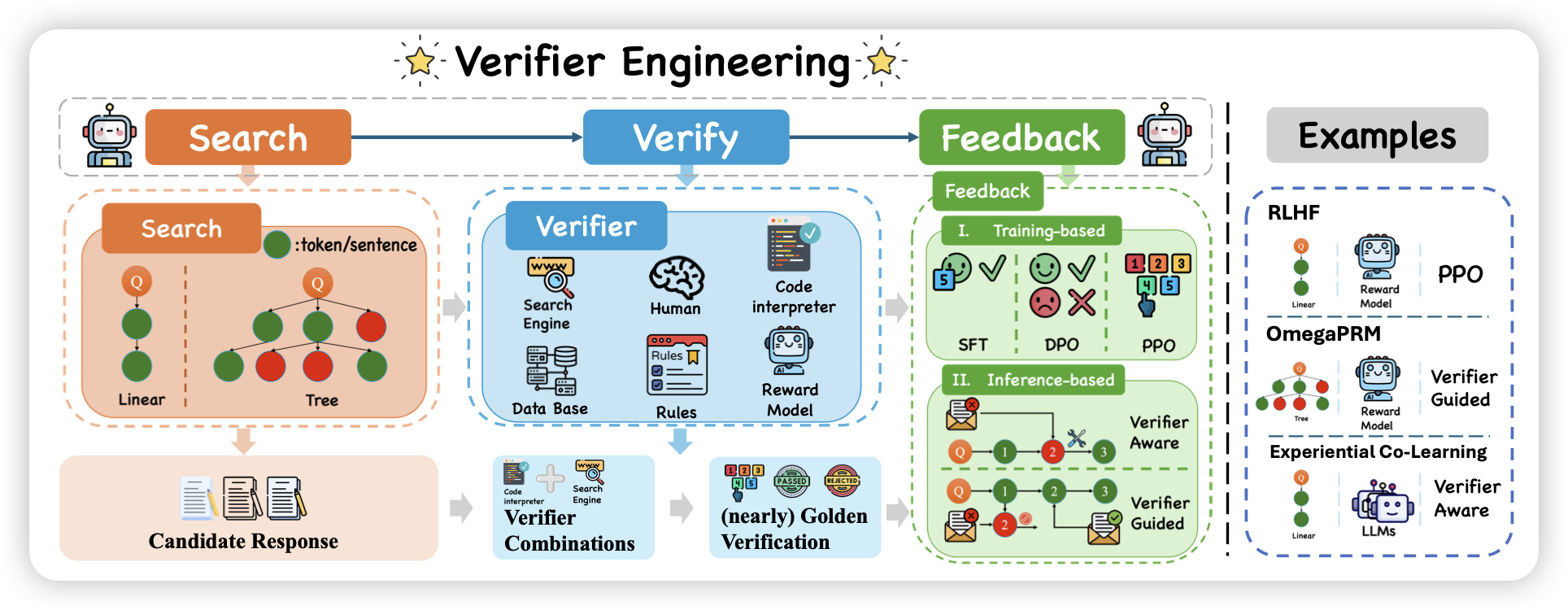
Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering
是一篇类似于survey的工作,作者提了一个叫做verifier engineering的概念,梳理了很多基于这种 search、verify、feedback三原子的、在各个领域的应用的工作。