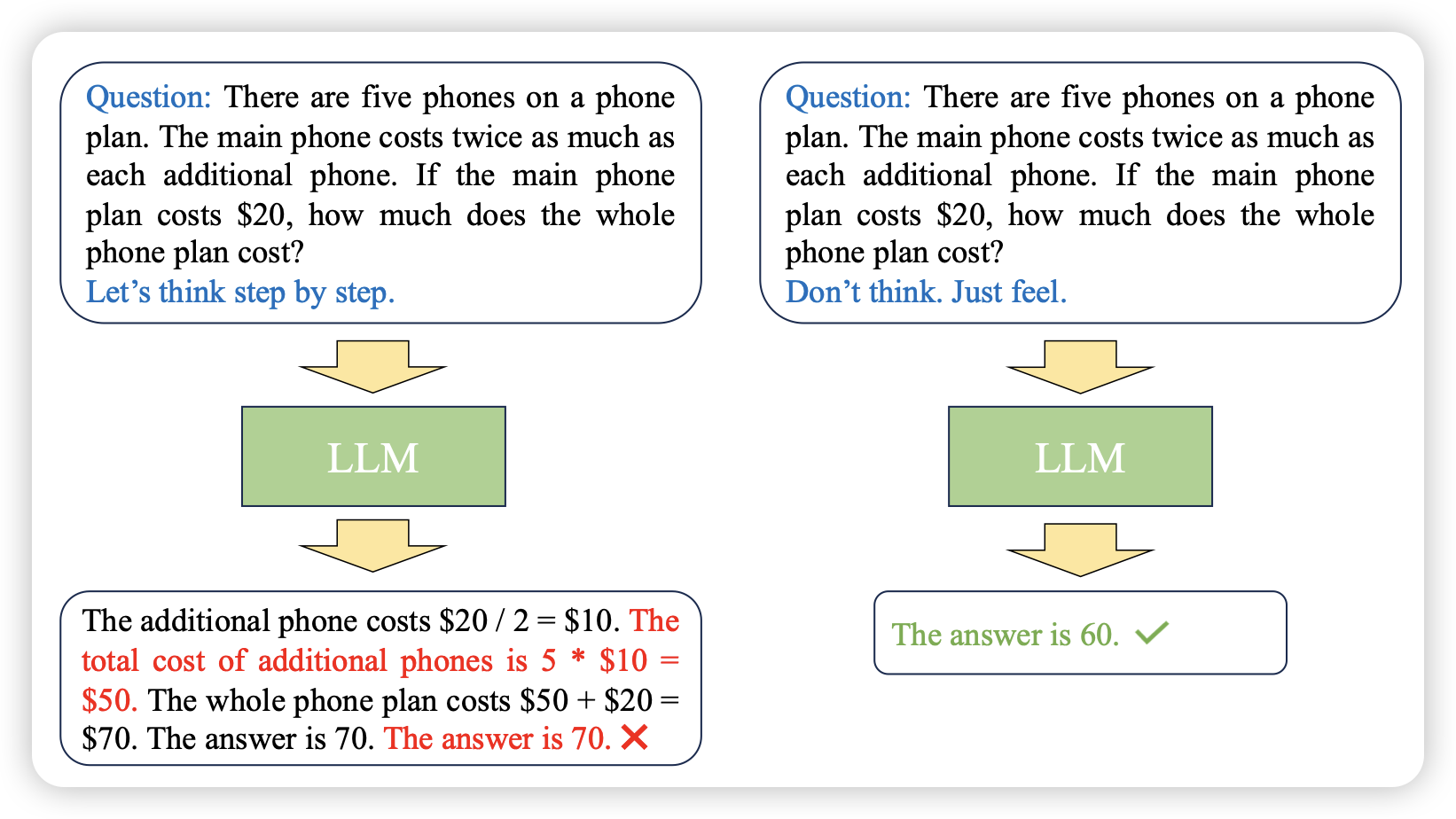
国庆节出来172篇工作
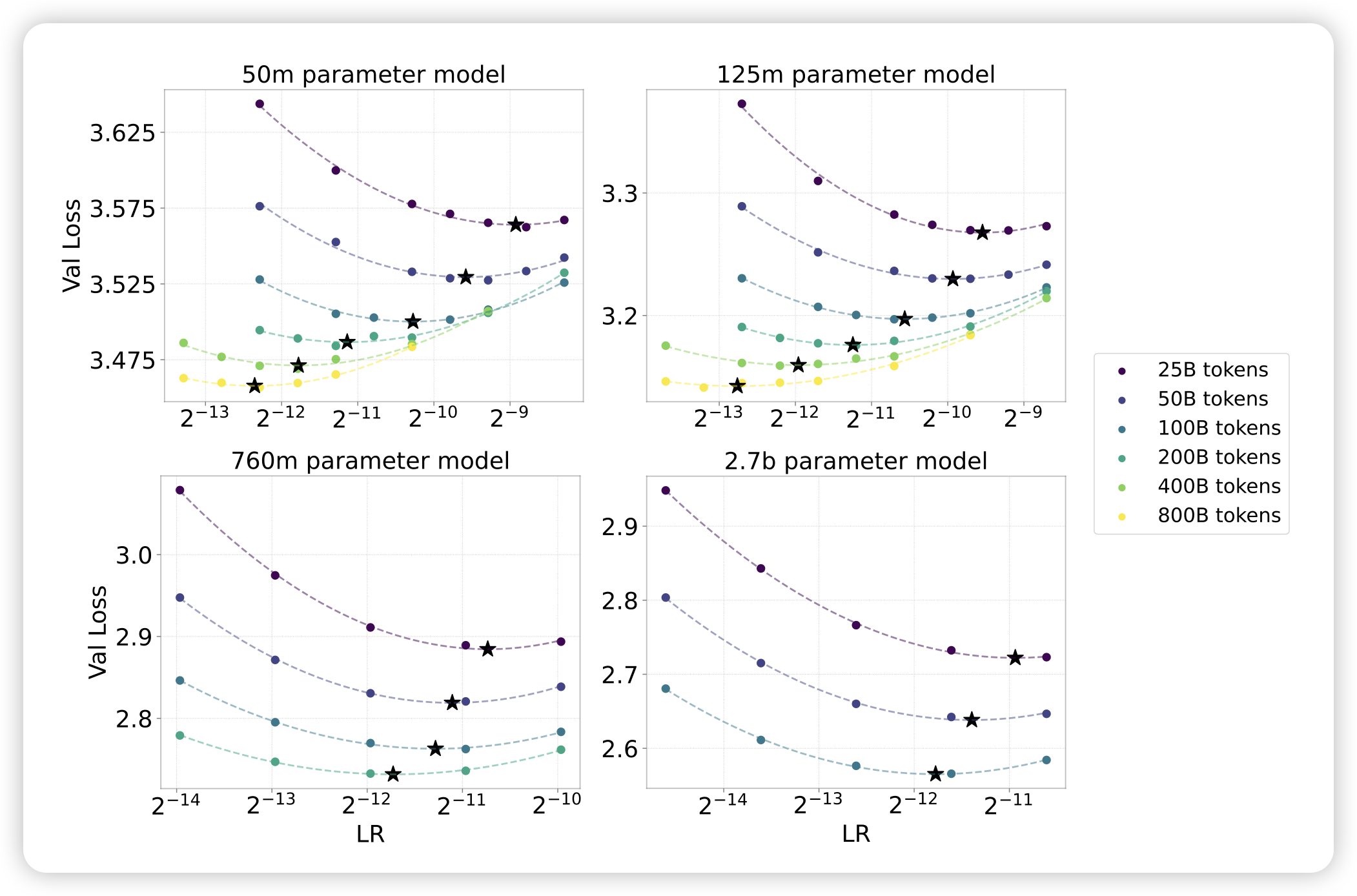
Scaling Optimal LR Across Token Horizons
Microsoft的工作,但是行文很有openAI的风范。作者想要探索训练大模型时的learning rate选择,能否从小模型试验中predict到大模型最优值呢?下面这张图基本说明了核心结论:
- 在不同的训练token数量下,最优lr都不一样。预计训练的token量越大,最优lr越小
- 在确定目标模型大小的情况下,最优lr随着token量的变化可以通过小模型的曲线,和大模型在少token的最优lr寻找上做拟合
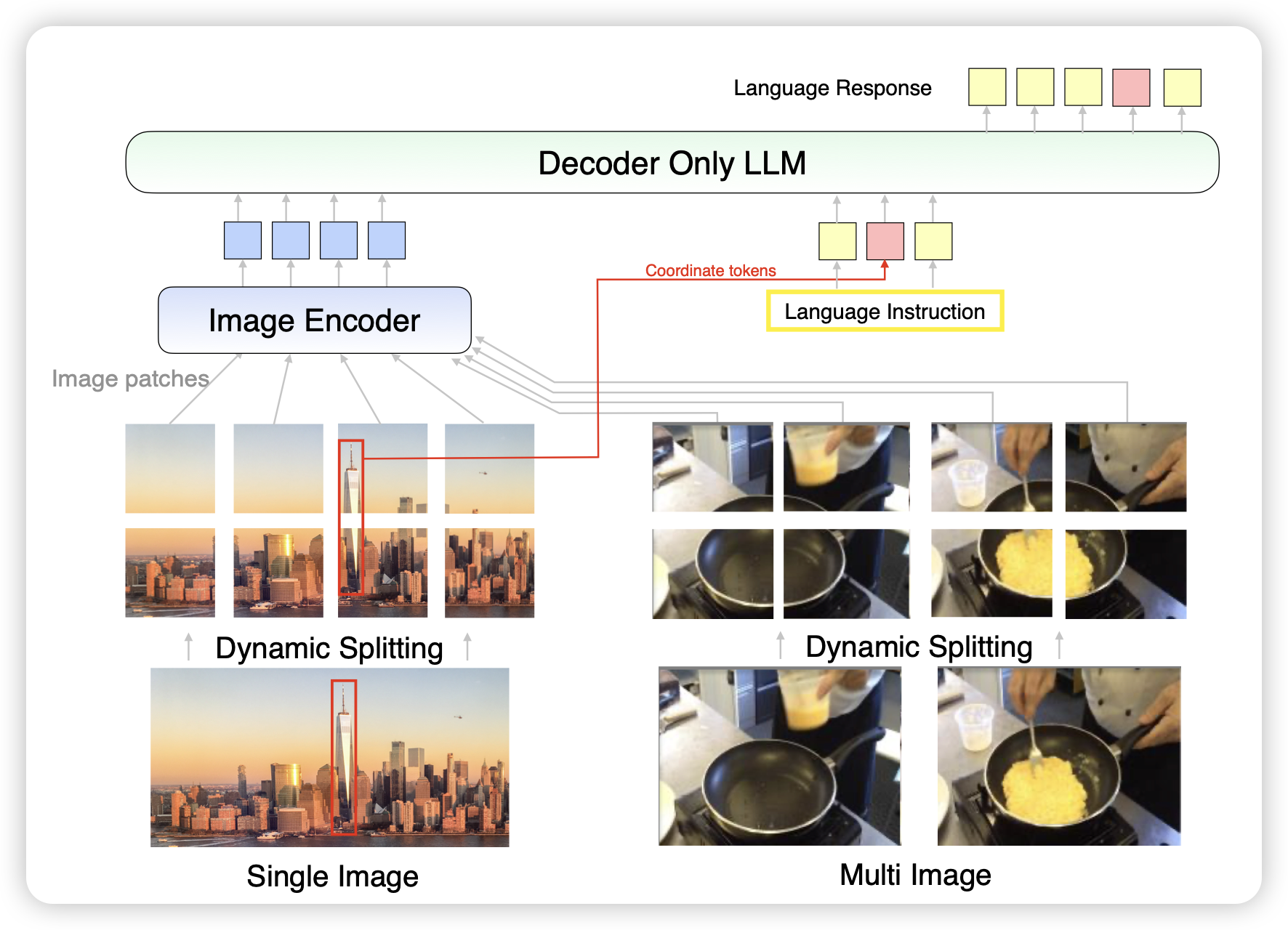
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
之前我出过一篇mm1的论文阅读笔记,今天更新了mm1.5,这次在常规升级的基础上,添加了mm1.5-video视频理解和mm1.5-UI,继承了ferret-ui的手机界面理解能力
Do Influence Functions Work on Large Language Models?
这篇工作瞄准的是前几年的明星方向influence function。这个方向是想要找到对参数改变影响最小的一些训练数据,然后剔除掉给模型涨分。作者在大模型里重新实验了这个方向,发现定义里存在一个谬误:对于LLM来说,参数改变的多少和性能的提升相关性不大。所以,这个领域在大模型时代可能需要做出改变
Instance-adaptive Zero-shot Chain-of-Thought Prompting
作者发现,不同的reasoning prompt有他适合的场景,然后作者想要找到一个很好的映射方法给不同的question找到适合的prompt。
这篇的思路很像我很喜欢的那篇"self-discover"论文