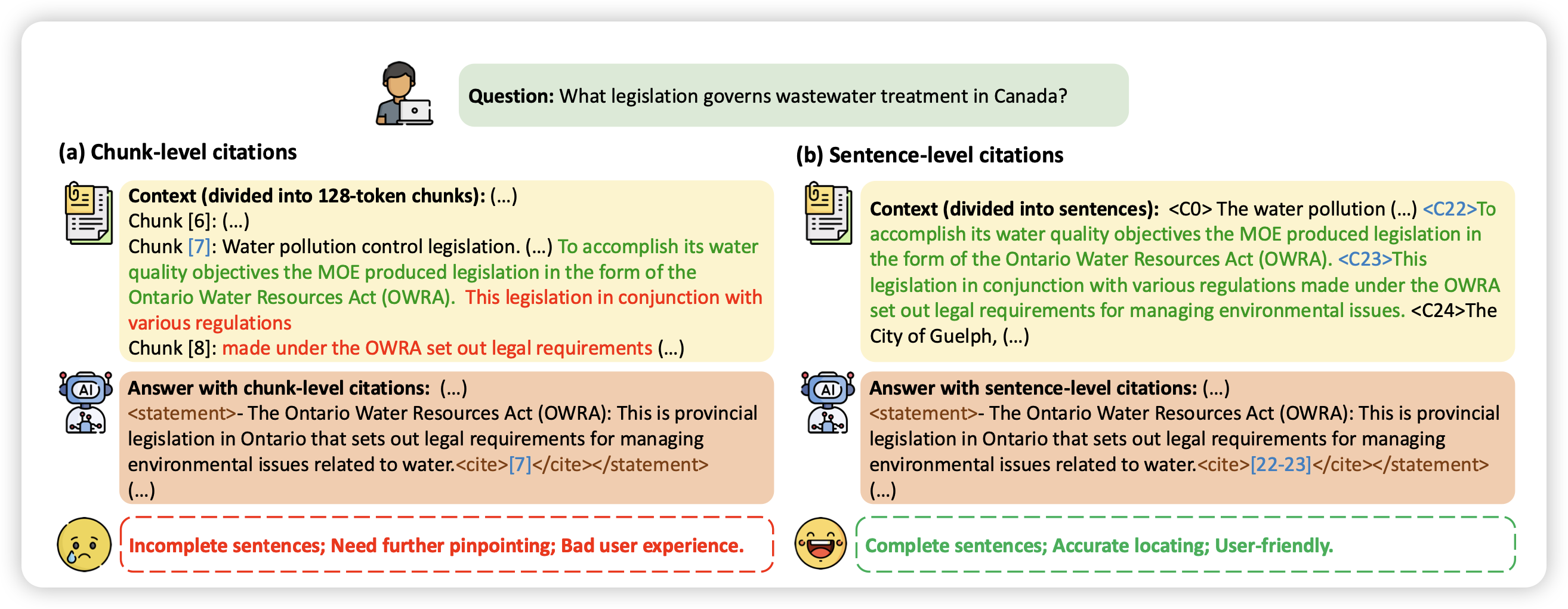
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
neubig官方出面,更新mmmu了:这次的主要是把只靠text就能回答的问题刨除掉了
只能说,该强的还是强
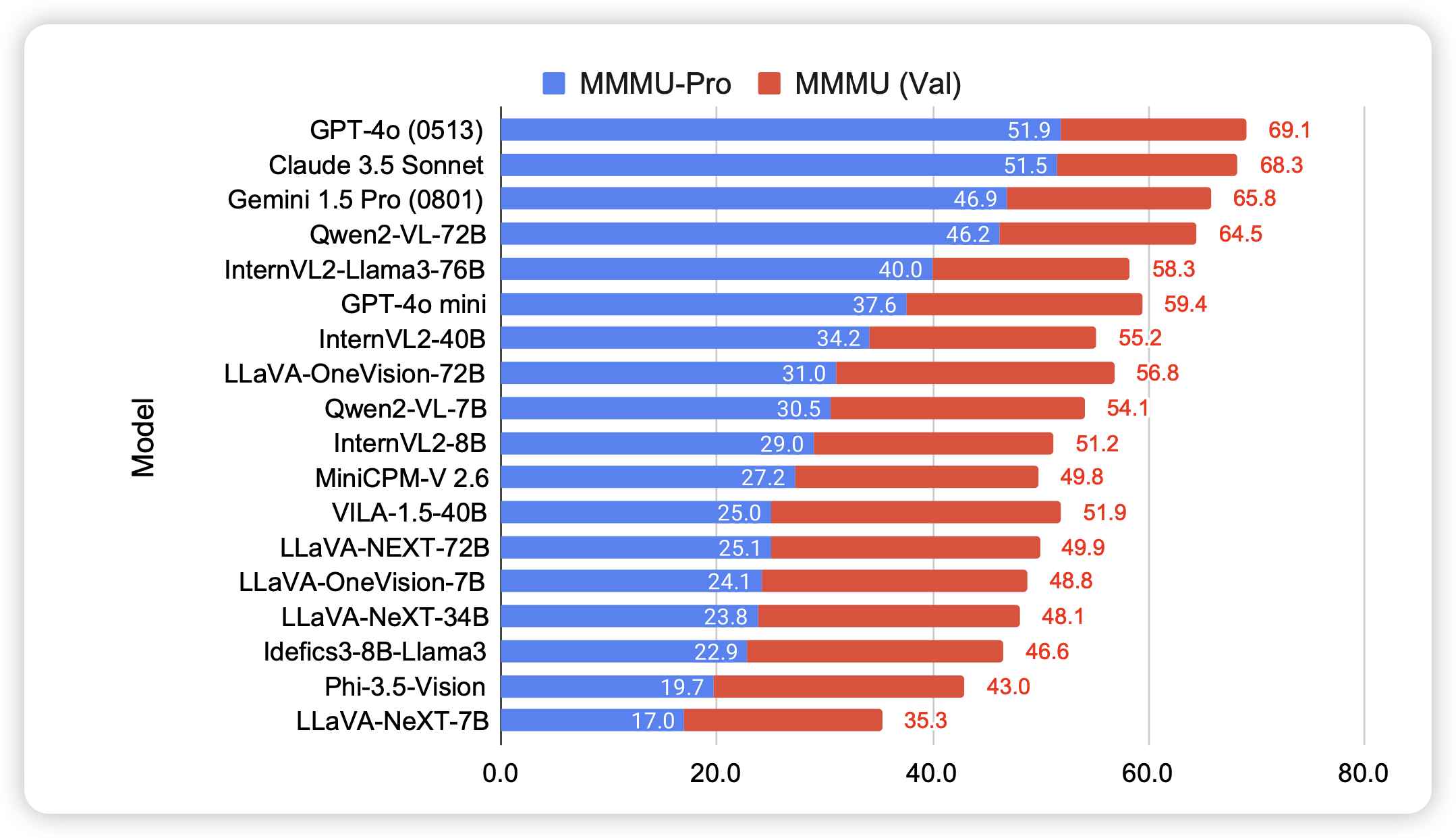
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
注意,这个工作叫looongllava,因为之前有另一个叫longllava的工作……作者搞了个transformer和mamba混合结构,把单卡显存的vlm推到了1000照片。
只能说,vlm迈出的一小步,videoLLM迈出的一大步
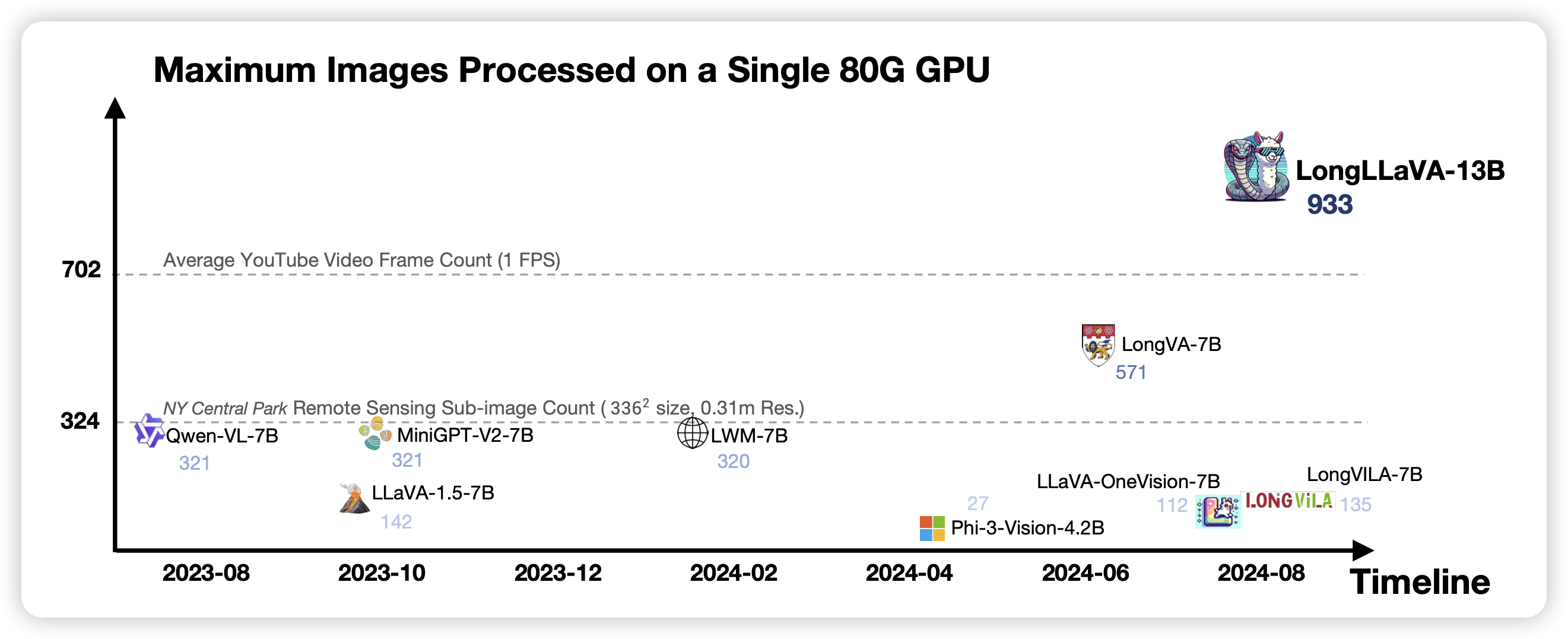
LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA
李娟子老师的工作,讨论的是long term citation:这个领域有点像是vlm里面的grounding,要求模型在输出的时候可以cite一下上下文里面的其他地方。作者的处理方式就是正常的构造数据+sft,达到了4o水平,估计又要为glm添砖加瓦了。但是这个方向我觉得挺有意思的
人类大概也很难做到long-term citation吧