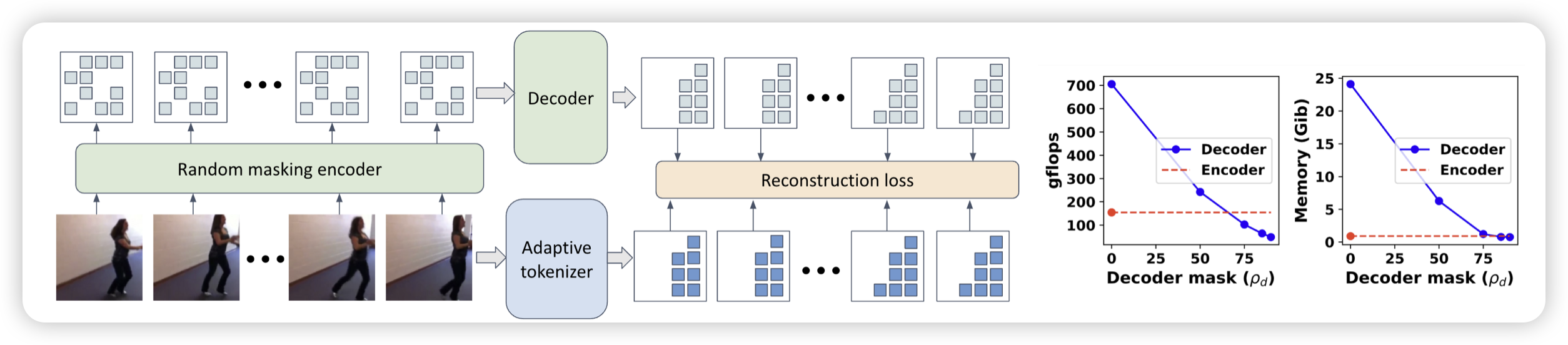
Extending Video Masked Autoencoders to 128 frames
作者提到,视频VAE Encoder这个领域一直最多做到16帧,作者的目的是拓展到更长视频的编码上。通过联立使用reconstruction loss和两种模态的加噪,还真搞出了点东西
Multimodal Autoregressive Pre-training of Large Vision Encoders
苹果出的一个joint training VLM的方法,模型结构和传统VLM差不多,都是几个模块式的。但是作者在VLM token上也加了loss,让他去直接预测图片的后面patch。但这个也不算生成理解统一模型,因为还是需要一个prefix vison encoder预先看到原始图片生成一堆visual token embedding。

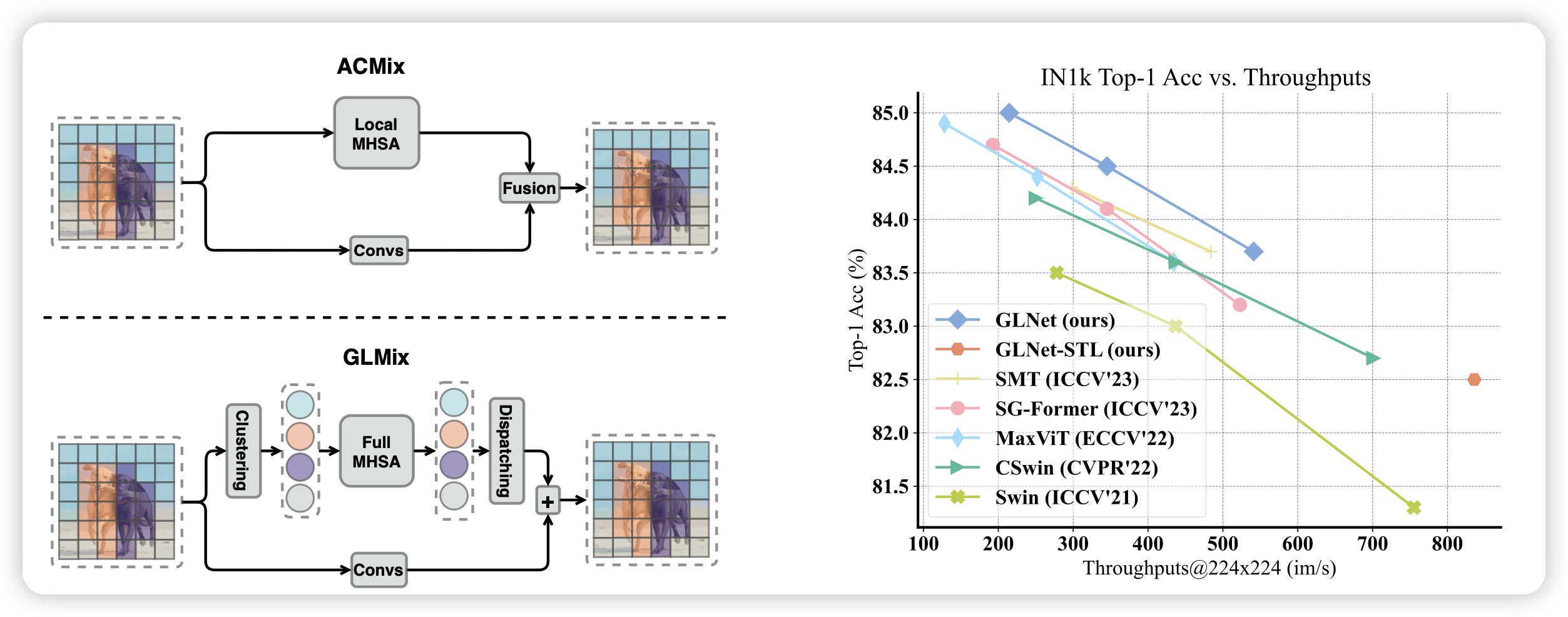
Revisiting the Integration of Convolution and Attention for Vision Backbone
一篇研究VLM结构的工作,在今天不太多见,有点kaiming遗风。作者发现,传统VLM中对于conv和attention层基本都是二选一,即使都用,也是在某些地方做二路并行。作者提出一个观点:conv快,attention慢,其实应该在不同颗粒度使用。能不能在pixel level大量使用conv,在更高颗粒度使用attention呢?
作者做了一些实验,发现这样出来的cv模型效果确实好不少。
scalability的问题不知道解决没有