今天grok3发布了,今天的别的paper会有热度吗
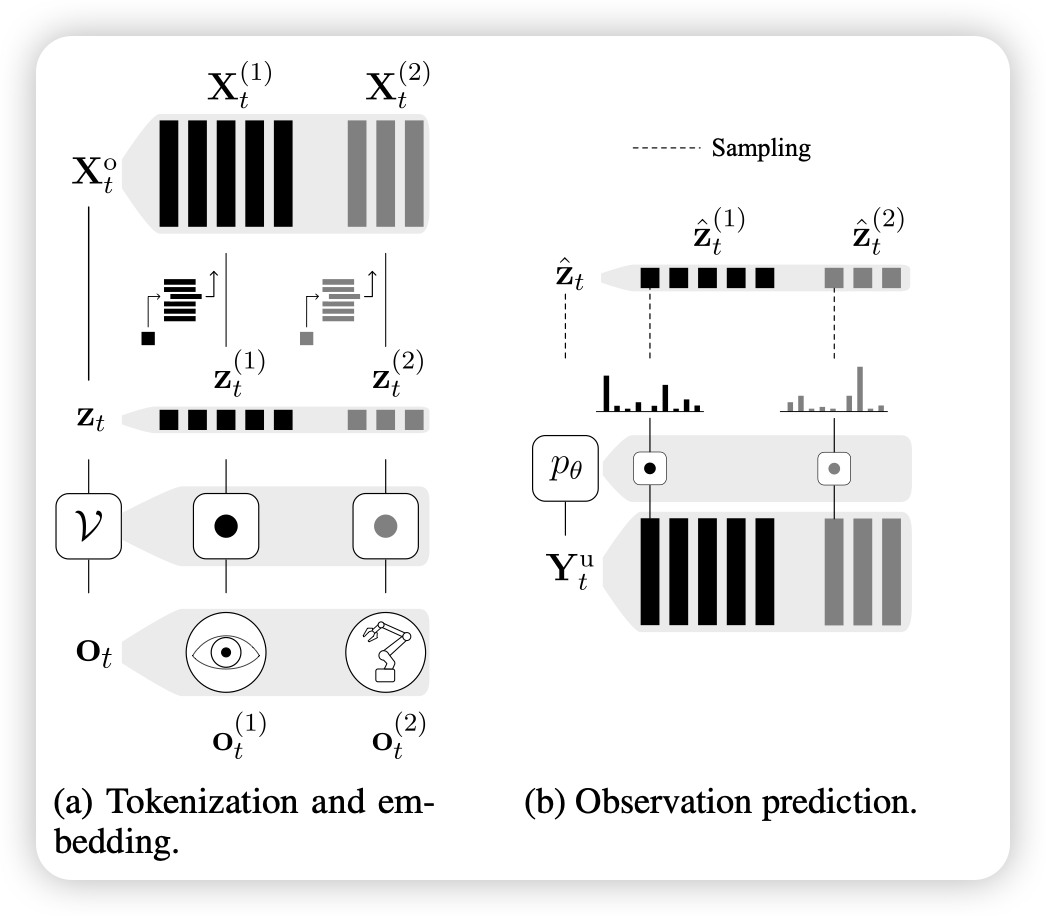
M3: A Modular World Model over Streams of Tokens
一篇做游戏agent的工作,作者把不同的小游戏merge在一起,用一套统一的tokenize方法进行编码,最后在下游任务上发现:可以通过同一个模型,在多个任务上都达到human level performance
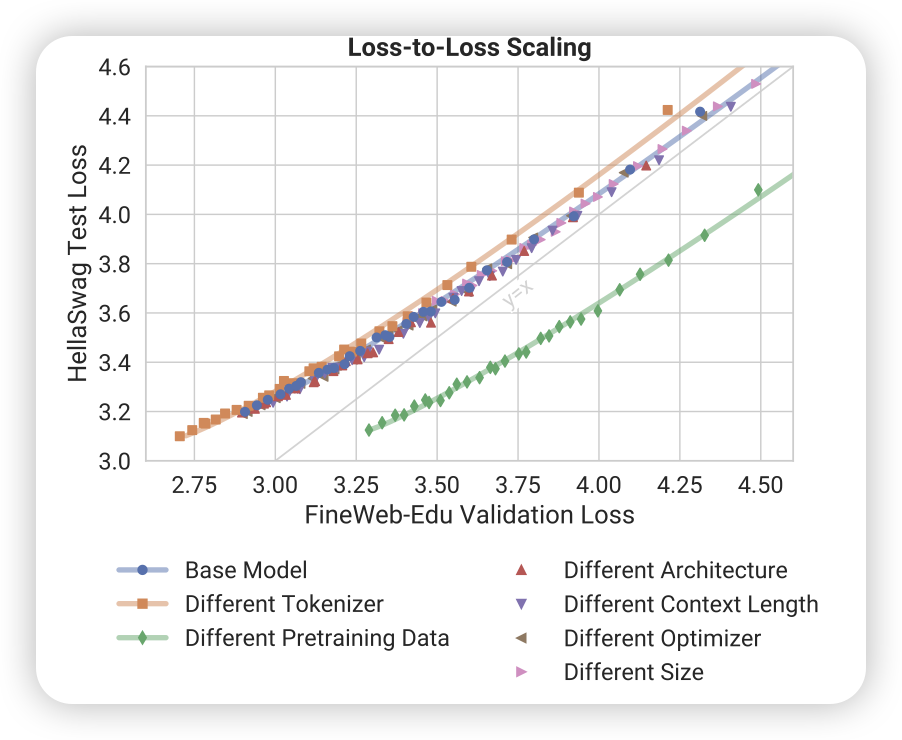
LLMs on the Line: Data Determines Loss-to-Loss Scaling Laws
这篇文章的标题差不多把文章内容讲完了。作者测试了不同的模型结构,发现几乎不影响从一个测试集到另一个测试集的loss曲线换算。真正影响曲线换算的,只有数据。或者说,训练数据类型,决定了换算关系里99%的成分
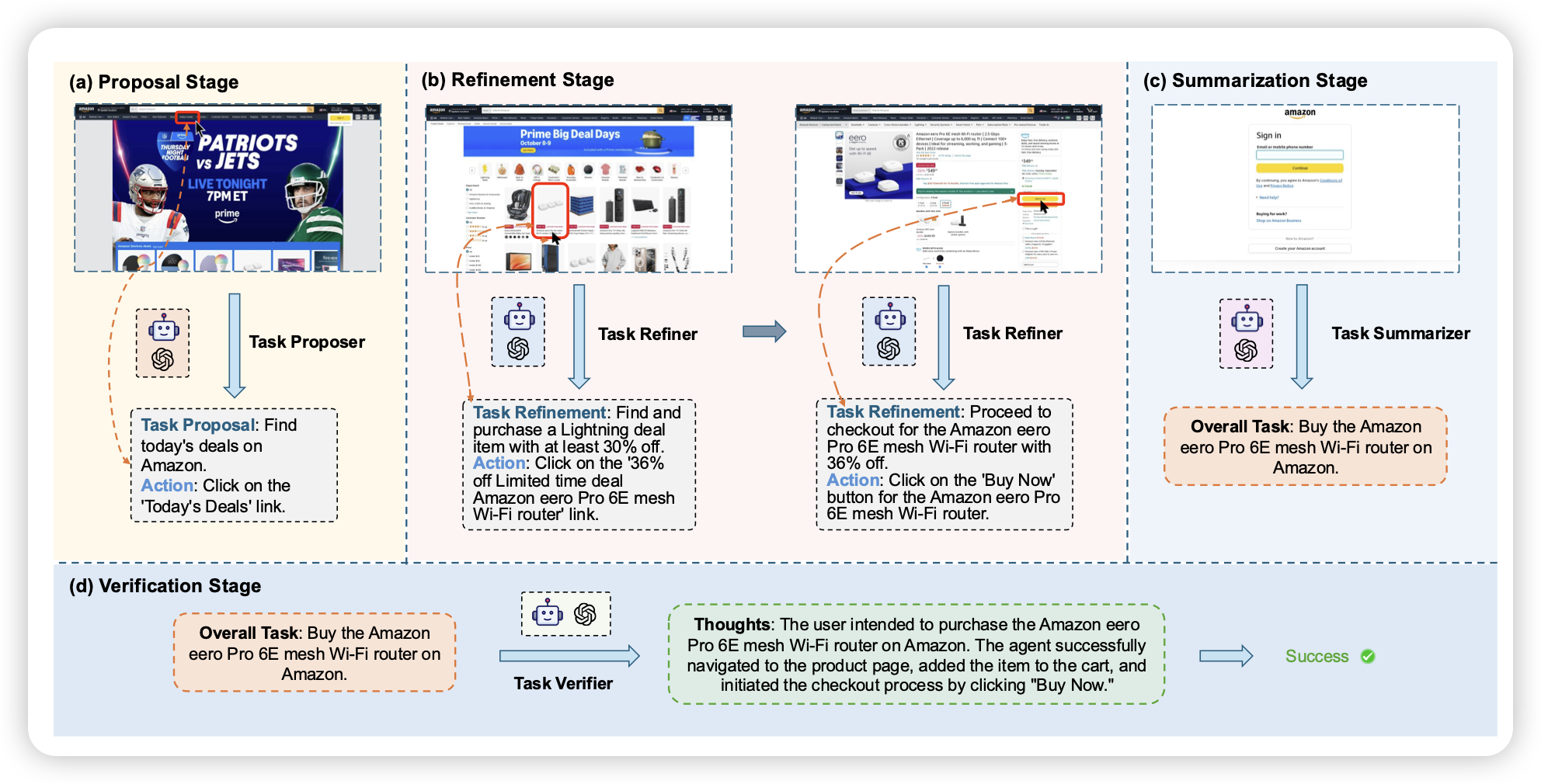
Explorer: Scaling Exploration-driven Web Trajectory Synthesis for Multimodal Web Agents
yu su老师的新作,是一个gui agent合成数据的工作,作者搞了大约10万个trace,并且记录了中间过程的各种grounding target,训练出来的模型效果也很不错。
最近很多靠VLM自己合成gui trace的工作,从agenttrek到os-genesis到前两天的Internet Scaling Training for Agent,会是下一个agent大增长点吗?
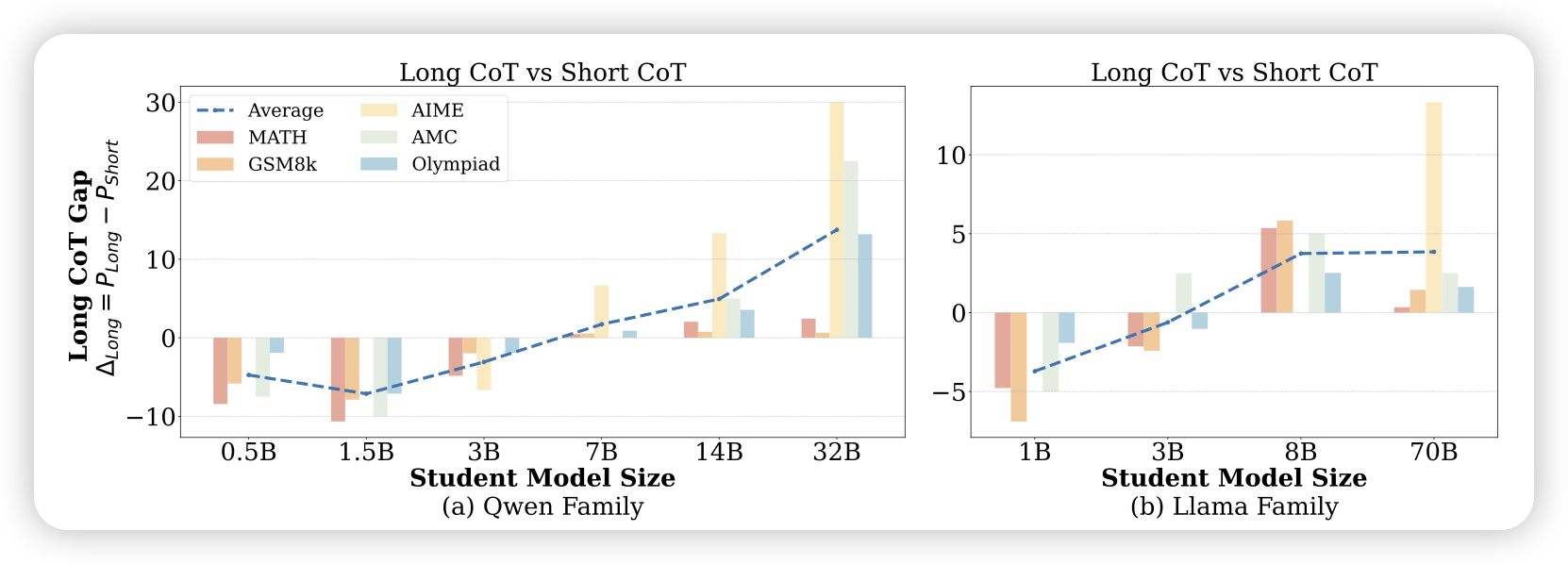
Small Models Struggle to Learn from Strong Reasoners
对于小的模型,如果使用大o1 model的long-cot蒸馏会怎么样呢?作者发现,如果蒸馏一个3B的模型,不仅效果不会好,甚至会更差。这是因为小模型看起来没有潜质去理解更难的思考方式,反而是用短cot蒸馏,效果会更好。由此,作者试了一下短cot和长cot混合蒸馏,发现可以缓解这个问题
难道真有threshold intelligence.?