Training-Free Activation Sparsity in Large Language Models
infer稀疏性是LLM的固有形式:在预测时,绝大多数的attention、FFN参数激活值都很低。能不能让激活比较低的参数干脆不激活,置0呢?已有工作,参考MoE,都需要让模型通过额外的训练来学会这件事。这篇工作探索了training-free的办法,通过对激活时的激活分布做微调,使得砍掉比较低的也不影响分布。发现可以在效果不咋降的前提下加速1.5x
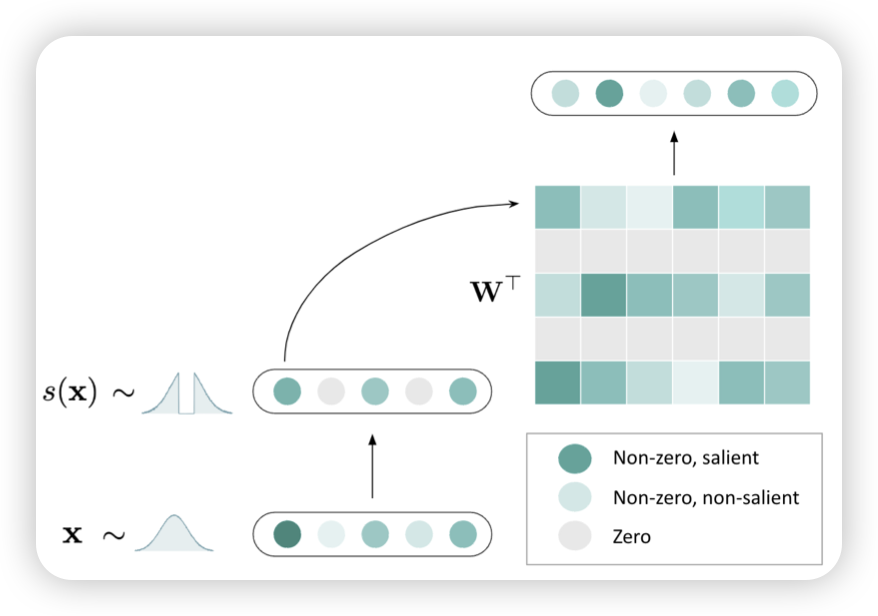
infer稀疏性是LLM的固有形式:在预测时,绝大多数的attention、FFN参数激活值都很低。能不能让激活比较低的参数干脆不激活,置0呢?已有工作,参考MoE,都需要让模型通过额外的训练来学会这件事。这篇工作探索了training-free的办法,通过对激活时的激活分布做微调,使得砍掉比较低的也不影响分布。发现可以在效果不咋降的前提下加速1.5x