Goku: Flow Based Video Generative Foundation Models
字节新出的工作,可以同时生成图片和视频,这里面用到了rectified flow Transformers。这篇工作,还要追溯到Scaling Rectified Flow Transformers for High-Resolution Image Synthesis, stable diffusion 3用到的技术。大概意思是,正常diffusion里面,每个timestep的加噪都是独立的(把图片添加一个随机噪声,不同step重新随机,只是绝对值不同)。但是,如果使得不同time step里面的加噪是一个线性的过程呢?这就是flow的意思。
话说这个东西好像是现在diffusion的新趋势,我已经很久没看diffusion的论文了……落伍了呀

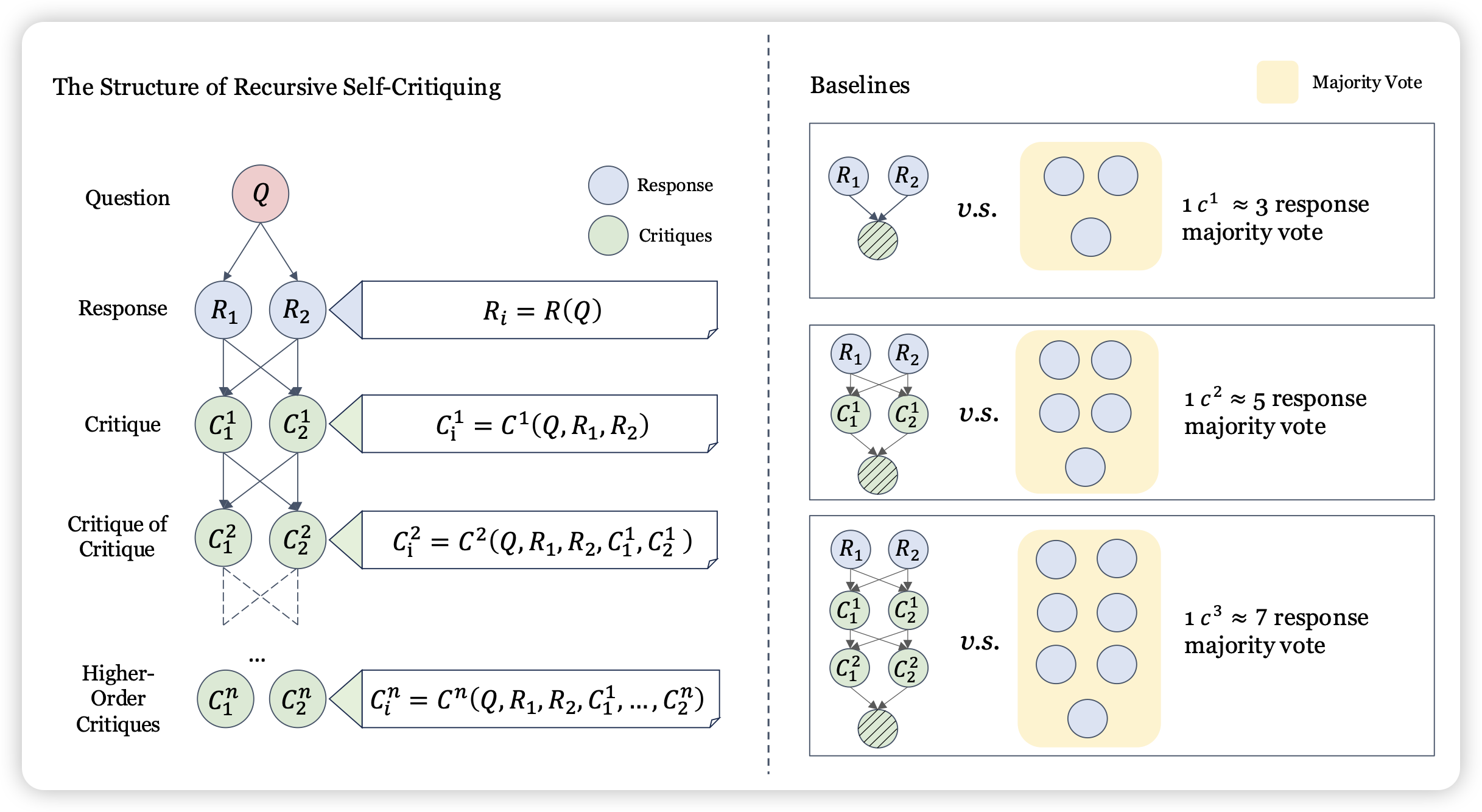
Scalable Oversight for Superhuman AI via Recursive Self-Critiquing
这篇工作名字起得很大气,内容和之前OpenAI一篇叫"LLM Critics Help Catch LLM Bugs"的工作很类似:如果模型水平超越人类了,那么人就无法给模型生成的结果进行反馈。但是,如果人去改另一个模型给目标模型的反馈,这个任务是否会更容易呢,这个setting就是critique of critique?作者还尝试了递归的场景(critique of critique of critique of ...)
如果大家对这类scalable oversight 领域的工作感兴趣,推荐先去读一下OpenAI的那个工作,写的真的挺好的……