Investigating Memorization in Video Diffusion Models
Text2video model是否只是在背诵训练数据?作者发现,还真是。作者搞了一些阴间prompt,差不多能定位到训练数据集的某些video,然后让模型去生成。发现模型就是在抄袭对应的训练数据,而且13个被测模型都是这样

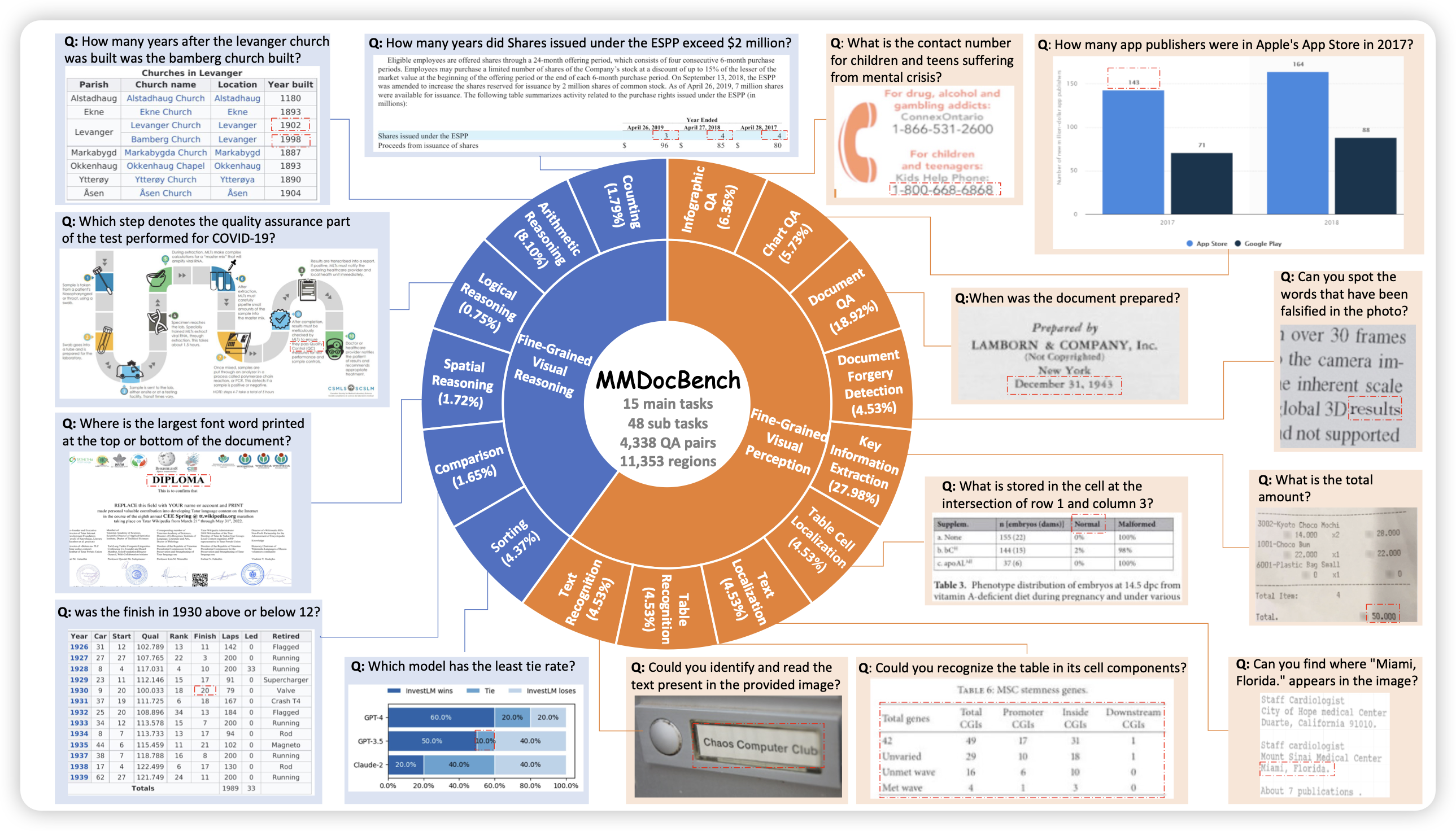
MMDocBench: Benchmarking Large Vision-Language Models for Fine-Grained Visual Document Understanding
作者提了一个点:目前的doc qa基本上都是high-level的,关注整个页面、或者一大段文字的内容。没有benchmark去关注页面很局部的信息,作者由此搞了个fine-grained doc qa,基本都是信息在页面里很小很不起眼。
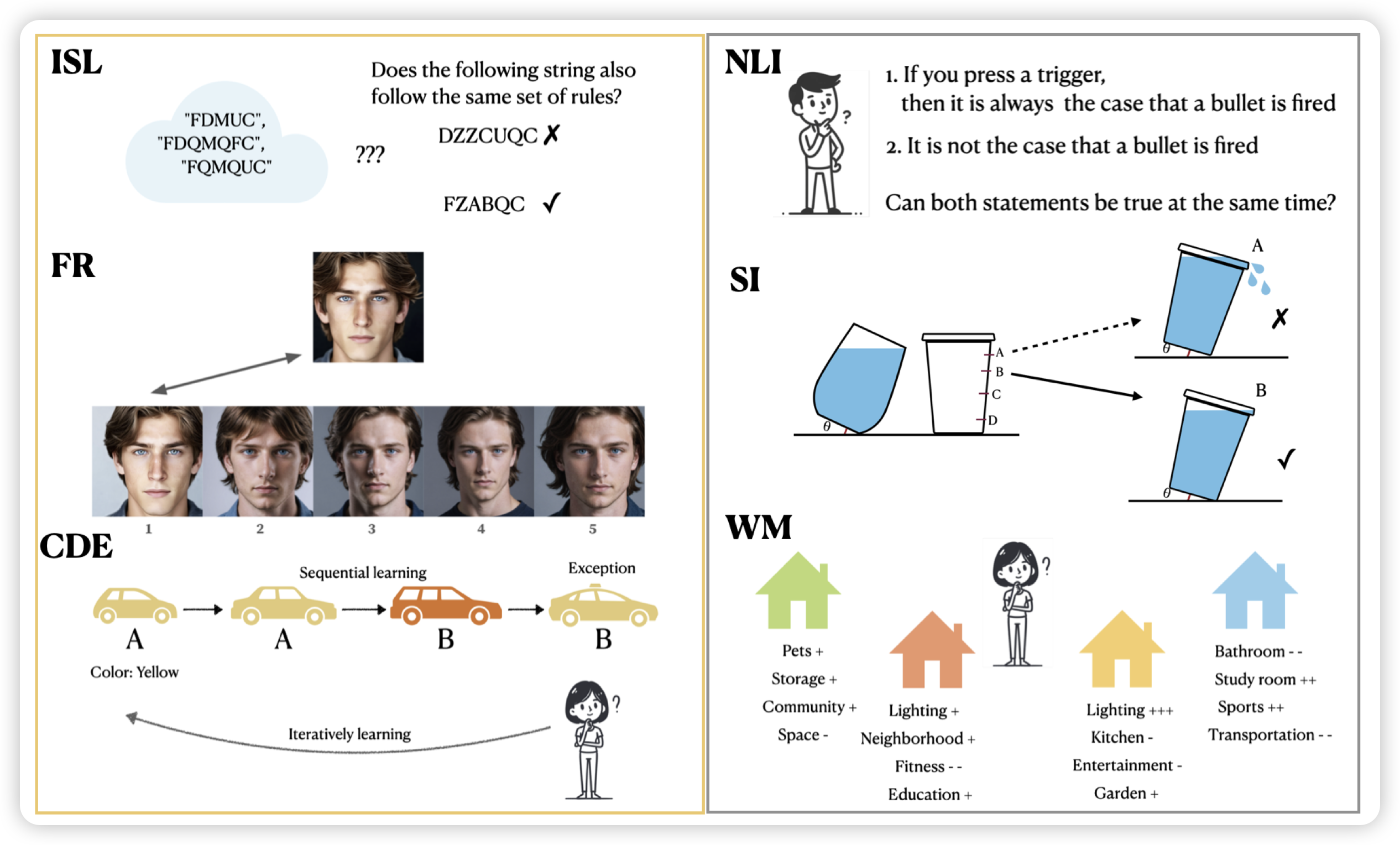
Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse
之前有个方向叫inverse scaling law:找到一些参数更大的模型反而表现更差的任务。作者搞了个inverse的CoT版本:找到用了CoT反而效果更差的任务。作者更近一步,先去找对人来说“用了CoT反而效果更差的任务”,再去看模型表现和人是否是一致的。核心发现是:
- 能找到不少这样的任务,让o1比4o掉35%
- 模型和人的表现不完全一致,但大体是类似的。
还挺好玩的……以后来个"Inverse CoT scaling-law can be U-shaped" [doge]
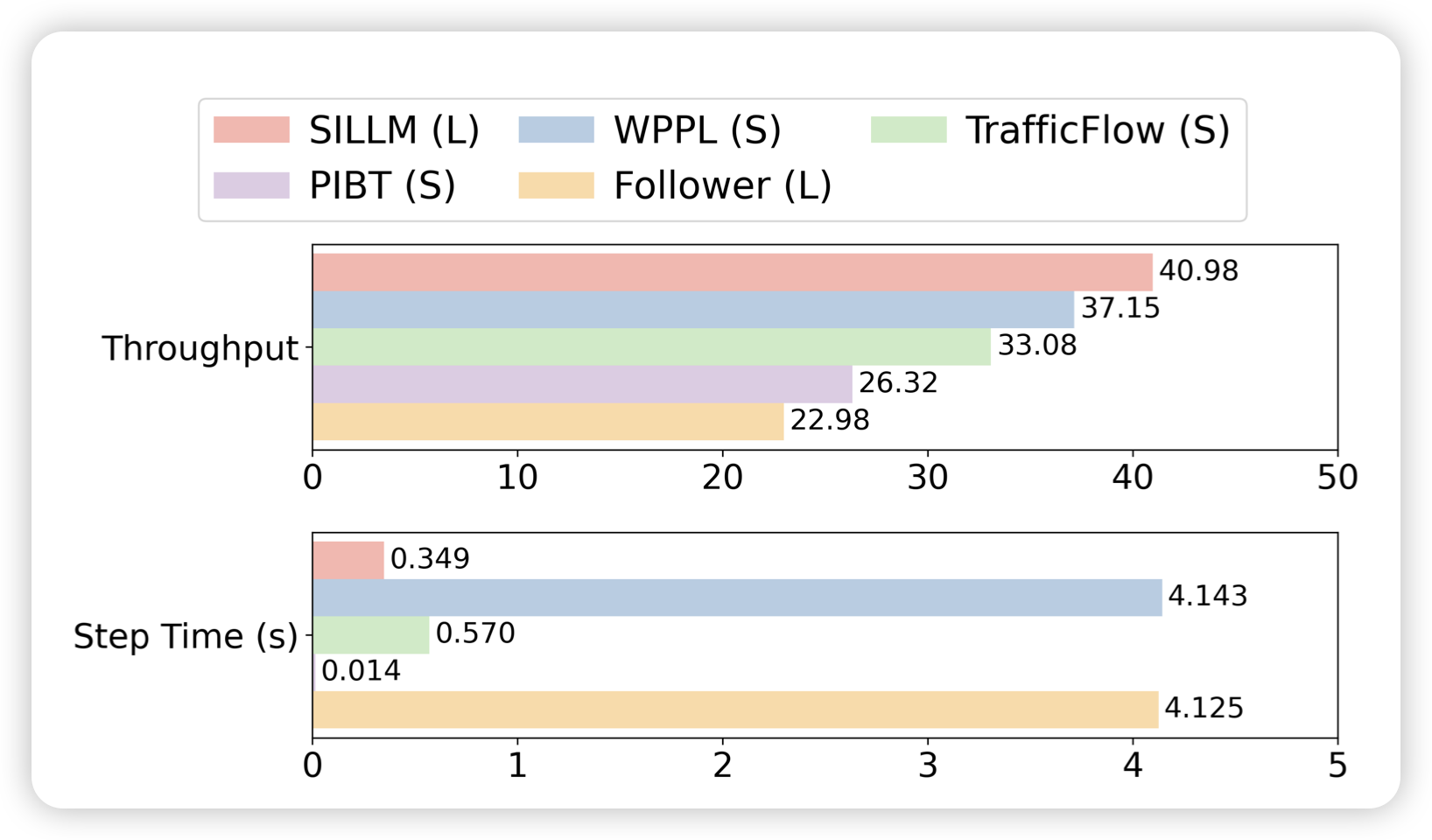
Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding
一篇比较传统AI的工作:作者研究了MAPF问题,如何同时规划多个agent的路径,使得互相不会卡位置死锁,同时移动很高效。作者探索的是life long场景,也就是说位置要求会发生多次。在这个领域中,非AI的search 方法跑得很慢,但是效果比AI方法好。作者试图把search方法的trace作为数据,蒸馏到AI里,发现还真可以。不过,前提是scale,之前也有类似的工作,但scale的不够好
话说这套方法论还挺好玩的,挺有AAAI风格的