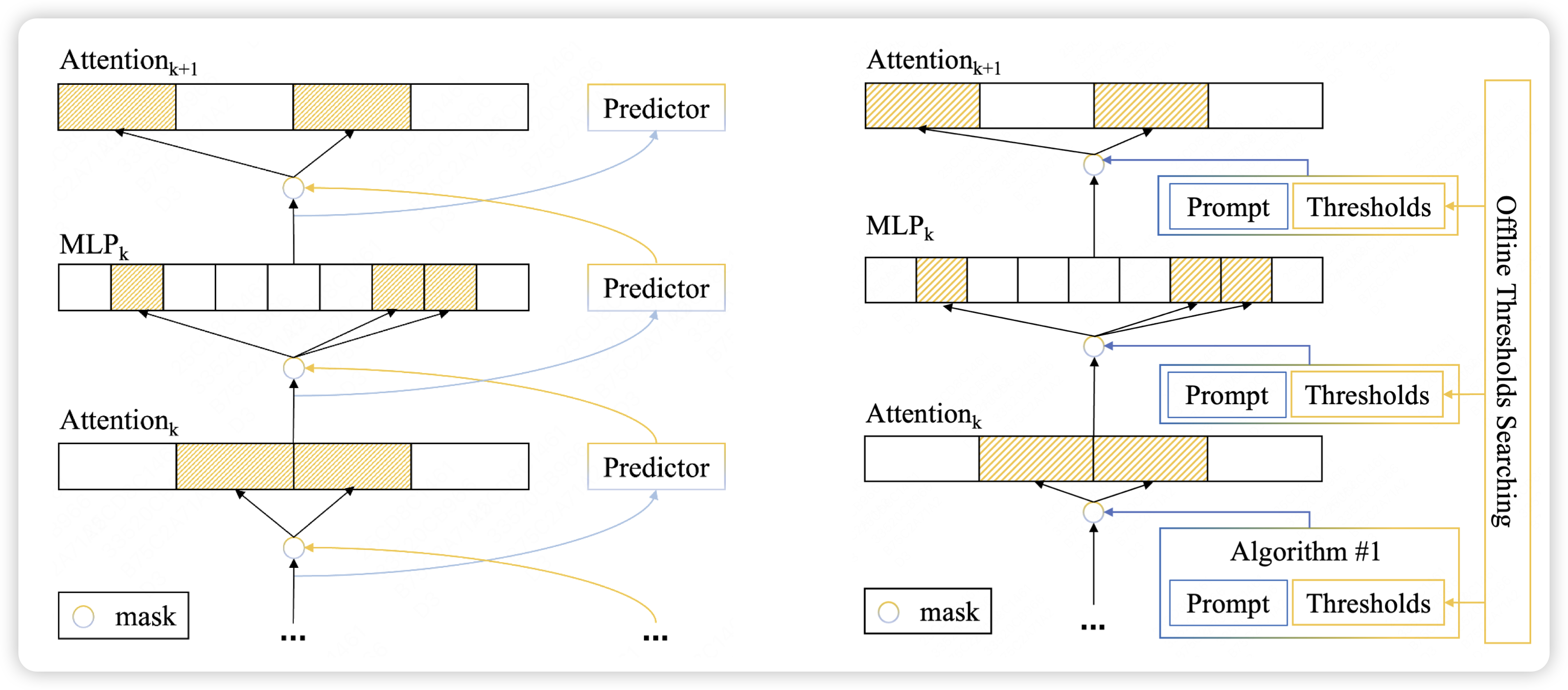
First Activations Matter: Training-Free Methods for Dynamic Activation in Large Language Models
这篇工作瞄准的时dynamic activation这个领域,这是一个和MoE对偶的场景:MoE认为我把FFN复制好多份,每次让模型竞争选出来谁是最合适的去激活。这个场景则不复制参数,而是认为正常的参数激活的过程中也是稀疏的,能不能提前预测这个稀疏性,进而干脆不计算可能贡献不大的部分。注意,不计算和不激活是俩概念,不激活还是得算了才知道,所以本质上没有加速;而不计算是真的没有算。
这篇工作更近一步,尝试了能不能干脆不去训练所谓的"sparse predictor",而是换成一个预先定义的、参数搜索的算法,竟然效果还不错
我也是新知道这个领域,感觉有点像是折叠屏手机里面的大折叠屏和小折叠屏……
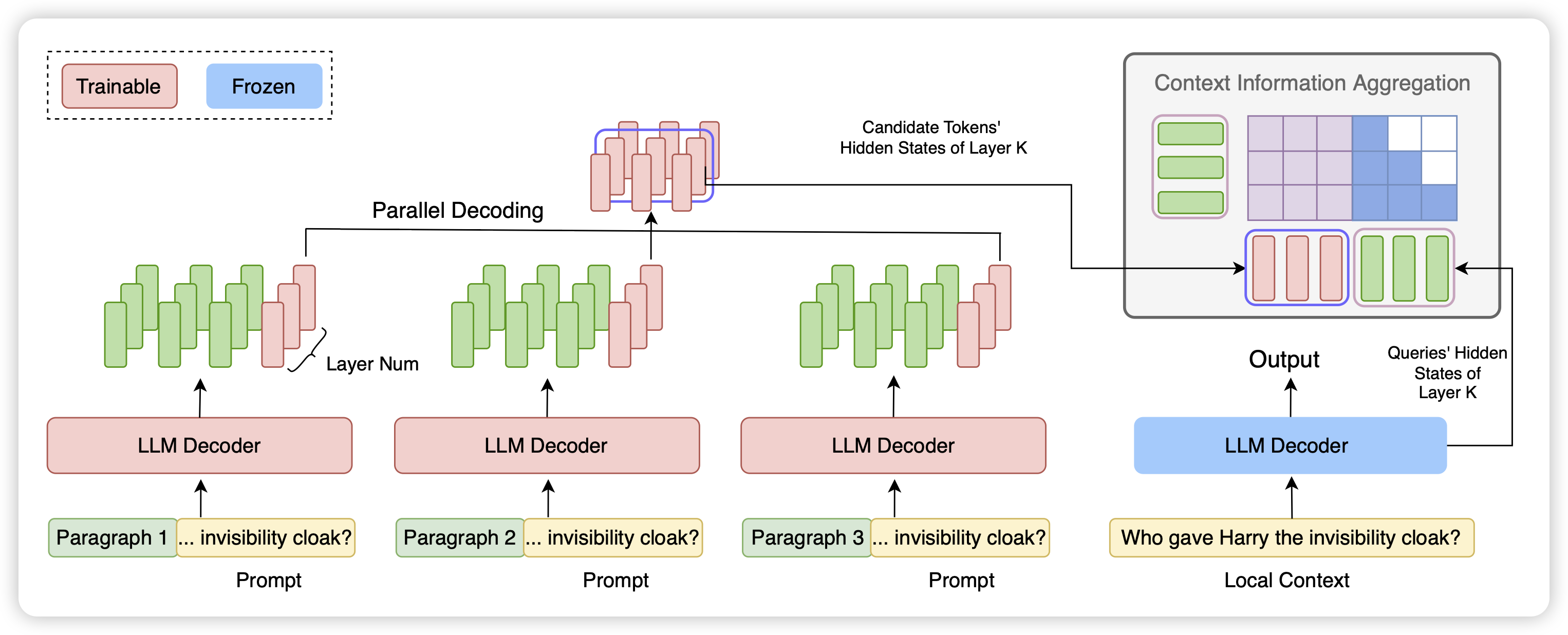
FocusLLM: Scaling LLM’s Context by Parallel Decoding
朋友的工作,挺有趣的long context思路:有点类似之前有篇Activation Beacon的工作。如果很长的context对于后文的decoding分别有作用,那么能不能把context分解成多个chunk,然后并行扫描给出hidden state中间结果。并最终让模型参考中间结果做最终的生成。作者发现这是可行的,并且在实际上可以把一个chunk压缩成几个token。
这里和之前做sentence embedding的核心区别是,在对chunk进行编码时是可以看到之前解码的上下文的,因此模型知道如何保留对local context有用的信息。其实对于很多类似于perplexity的场景,long context的来源就是一些语义无关的chunk