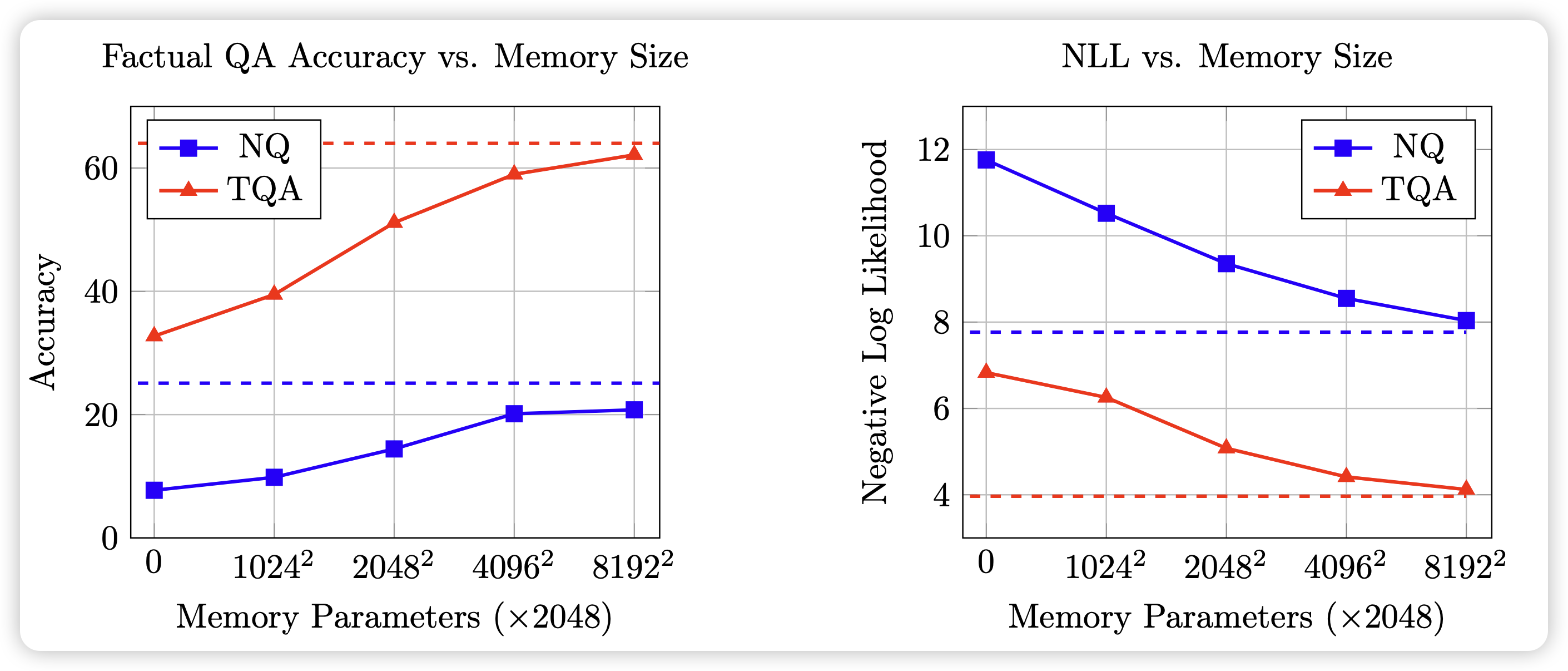
Memory Layers at Scale
Meta一篇很牛的工作,研究的是Memory layer。memory layer的核心逻辑是,在模型中添加额外的kv lookup,这个实现不会增加前向时的flops。但是会增加空间占用。作者足足给了128B的kv lookup,然后训了1TB token,发现在这个scaling规模性,做memory layer的正收益非常明显。
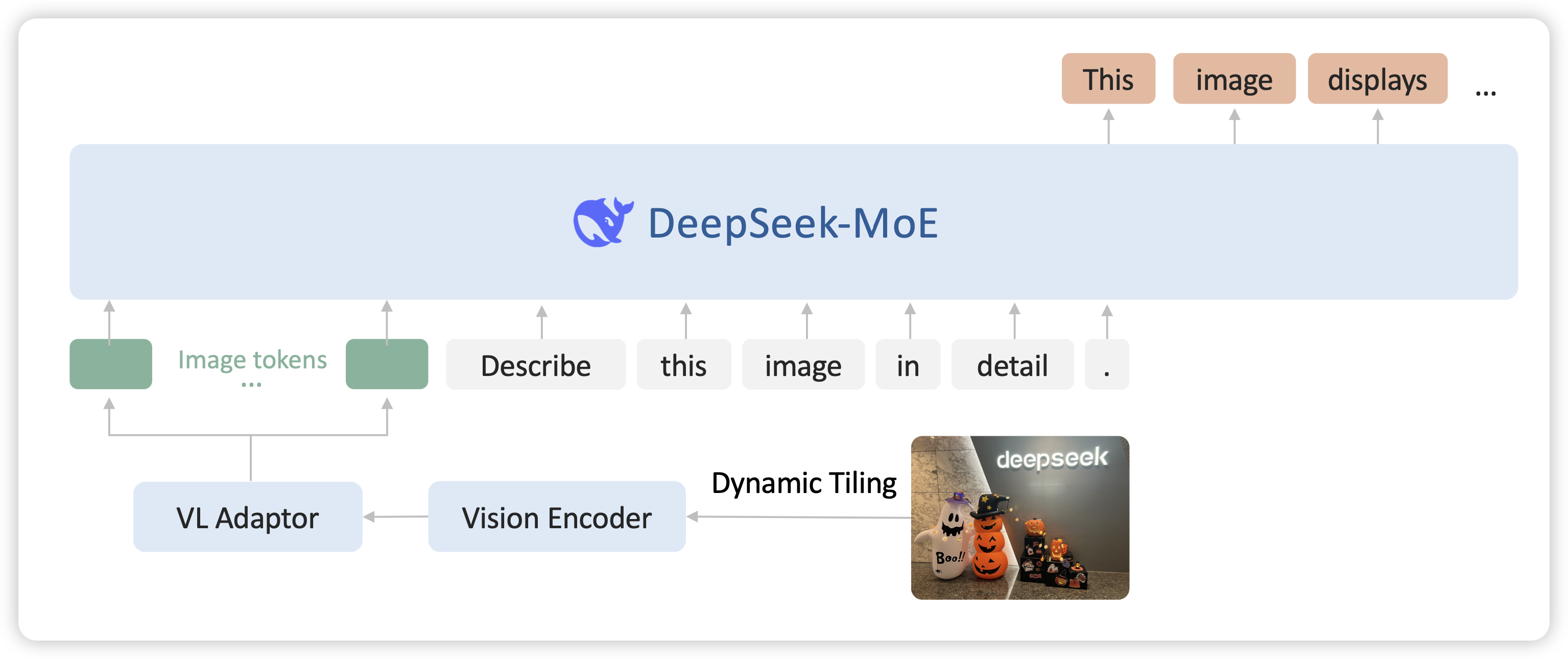
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
一年前deepseek-vl做得很早,但是一直没有新的更新,今天更新了v2,和qwen2-vl刷到了同一水平。虽然还是级联的结构,但竟然是moe。