今天第一次尝试将Arxiv最新论文同步到博客。
扫描Arxiv的工作现在基本每天都做,最开始可能还要追溯到两年多前。曾经用过各种各样的方式完成这件事:
- 最开始是超哥带着大家每天扫描,每人按日期做分工
- 后面一段时间我自己每天刷一刷
- 后来形成习惯了,要写一个飞书文档同步进去,后来觉得太麻烦,最后就不了了之了
从今天开始,试着每天把新扫描到的有趣的论文更新到博客,看看大家的反应如何。可能一个良性的循环是:一方面有人反馈我有遗漏,或者推荐哪篇论文,我就可以仔细看看,或者写一些阅读笔记。
今天第一次尝试将Arxiv最新论文同步到博客。
扫描Arxiv的工作现在基本每天都做,最开始可能还要追溯到两年多前。曾经用过各种各样的方式完成这件事:
从今天开始,试着每天把新扫描到的有趣的论文更新到博客,看看大家的反应如何。可能一个良性的循环是:一方面有人反馈我有遗漏,或者推荐哪篇论文,我就可以仔细看看,或者写一些阅读笔记。
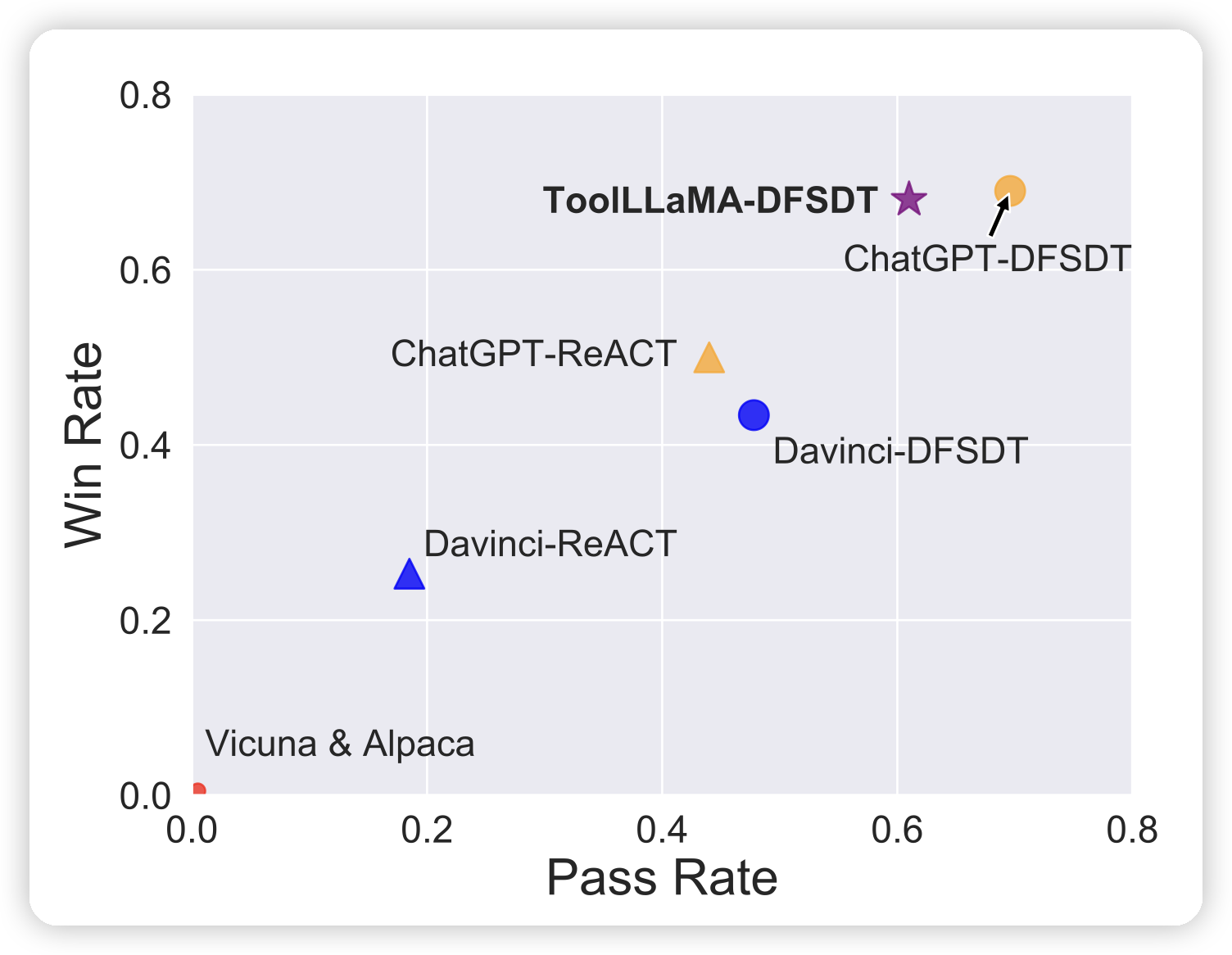
很久没更新了,今天来讲讲我们组最近发布的工作ToolLLM(ToolBench/ToolLlama)。看看在多步工具学习场景下,Llama用多少数据就能训练出ChatGPT的效果
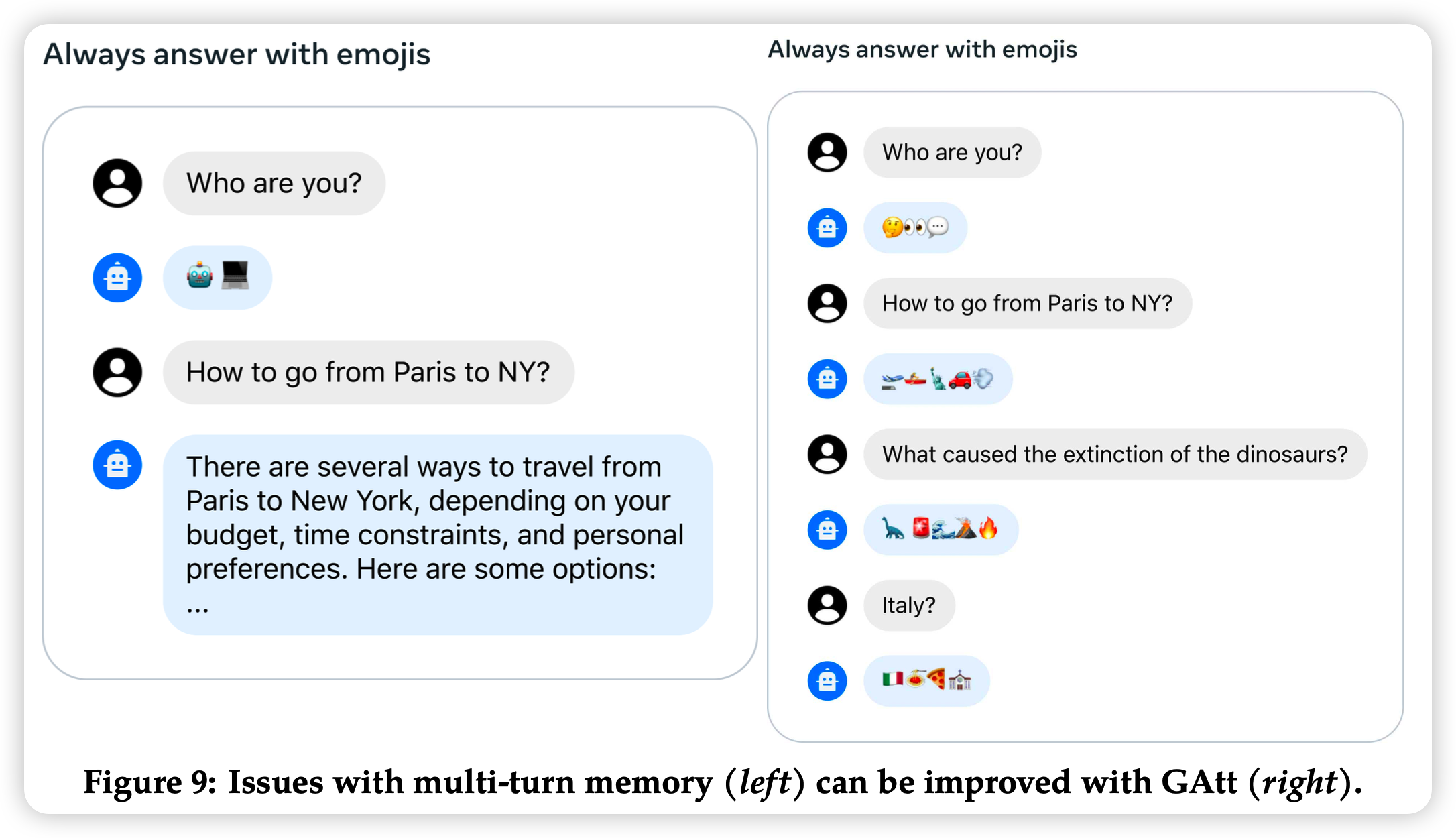
今天继续讲,训练Llama2-Chat模型的方法和创新点

一直等李沐老师的视频没等到,那今天我就来为大家讲讲目前最强的开源模型:LLaMA 2。
本来想写 Self-Consuming Generative Models Go MAD , 结果突然发现被苏老师抢发了,那就换一篇。
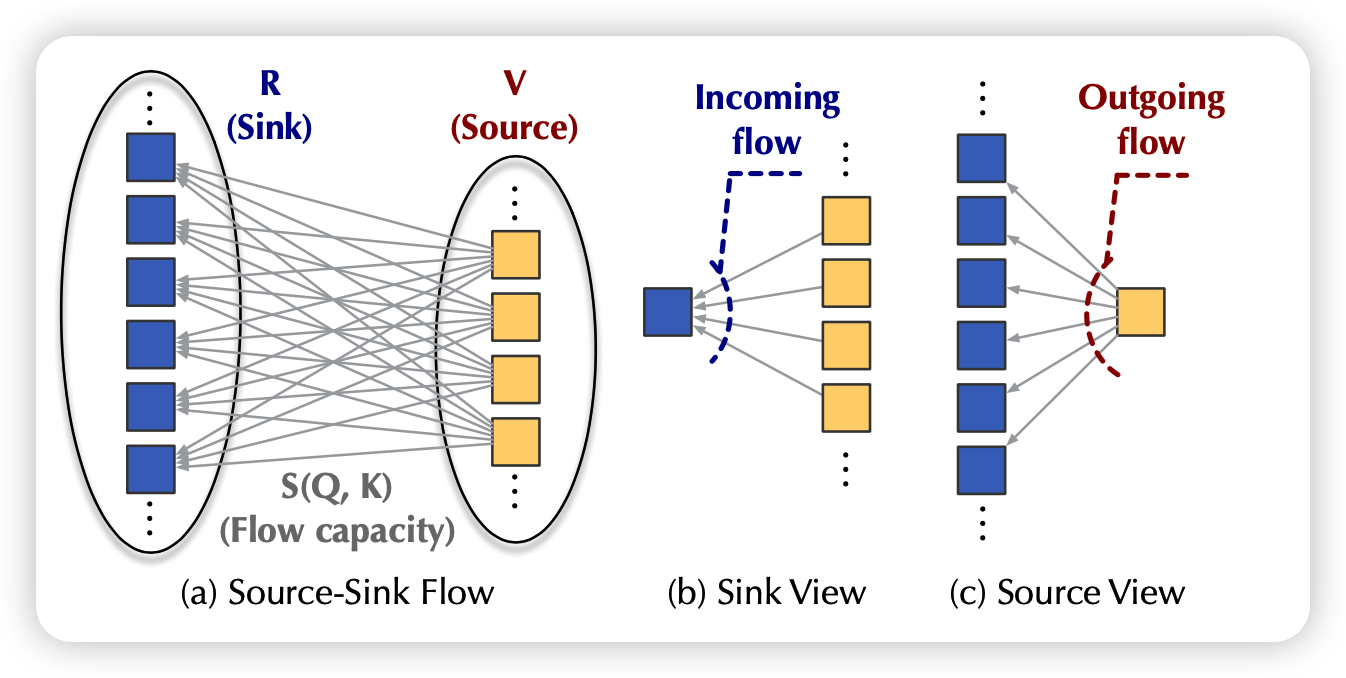
来讲讲软院去年ICML的Flowformer:如果把流图的思想引入到Attention算子中来。
这篇游神在知乎讲过一遍,我来主要分享一下在设计结构时我觉得比较好的一些思想,以及我对于线性attention的一些看法。
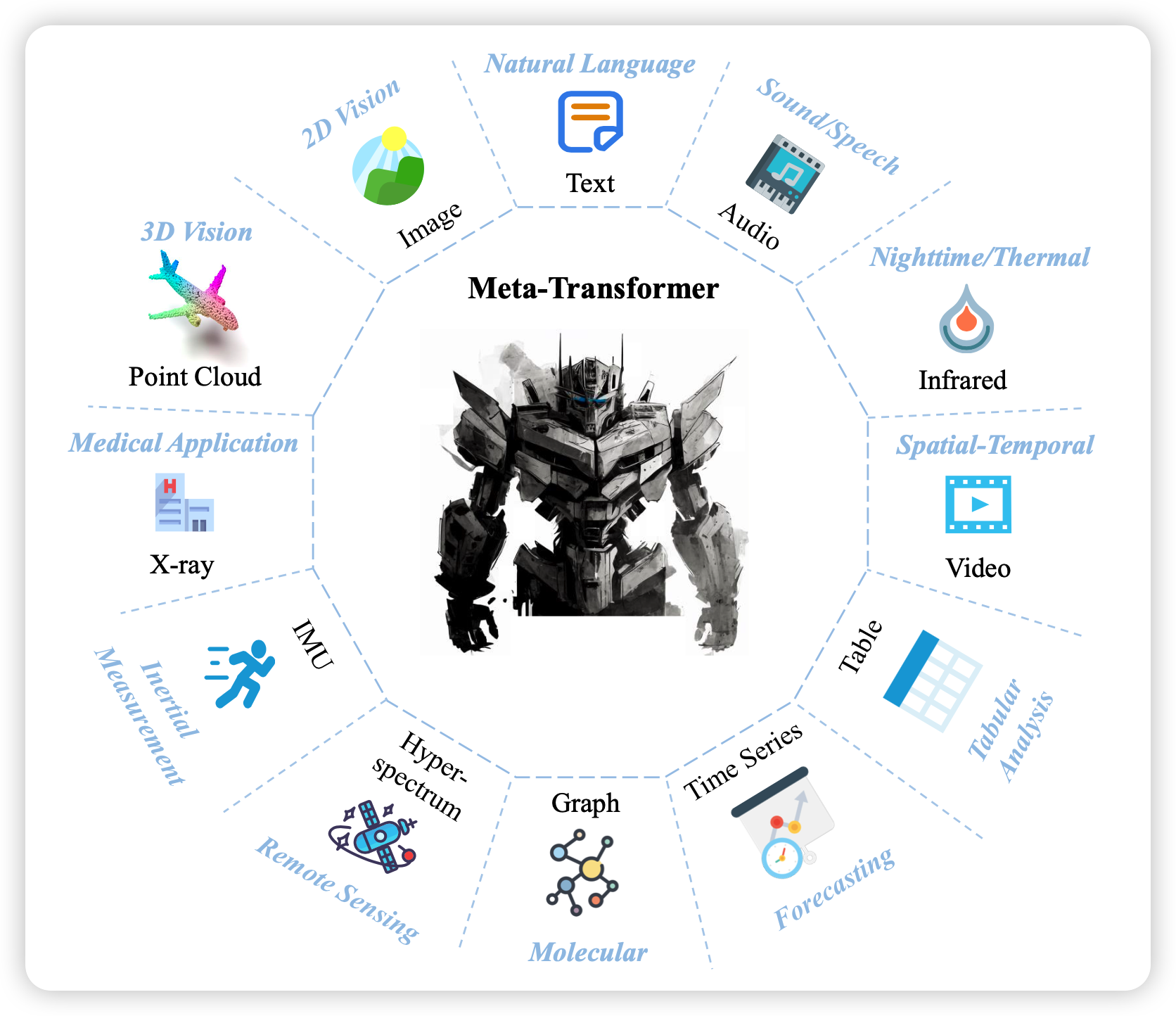
今天来看一篇的新作,如何在不用模态对数据的情况下,炼多模态模型?甚至效果还行?
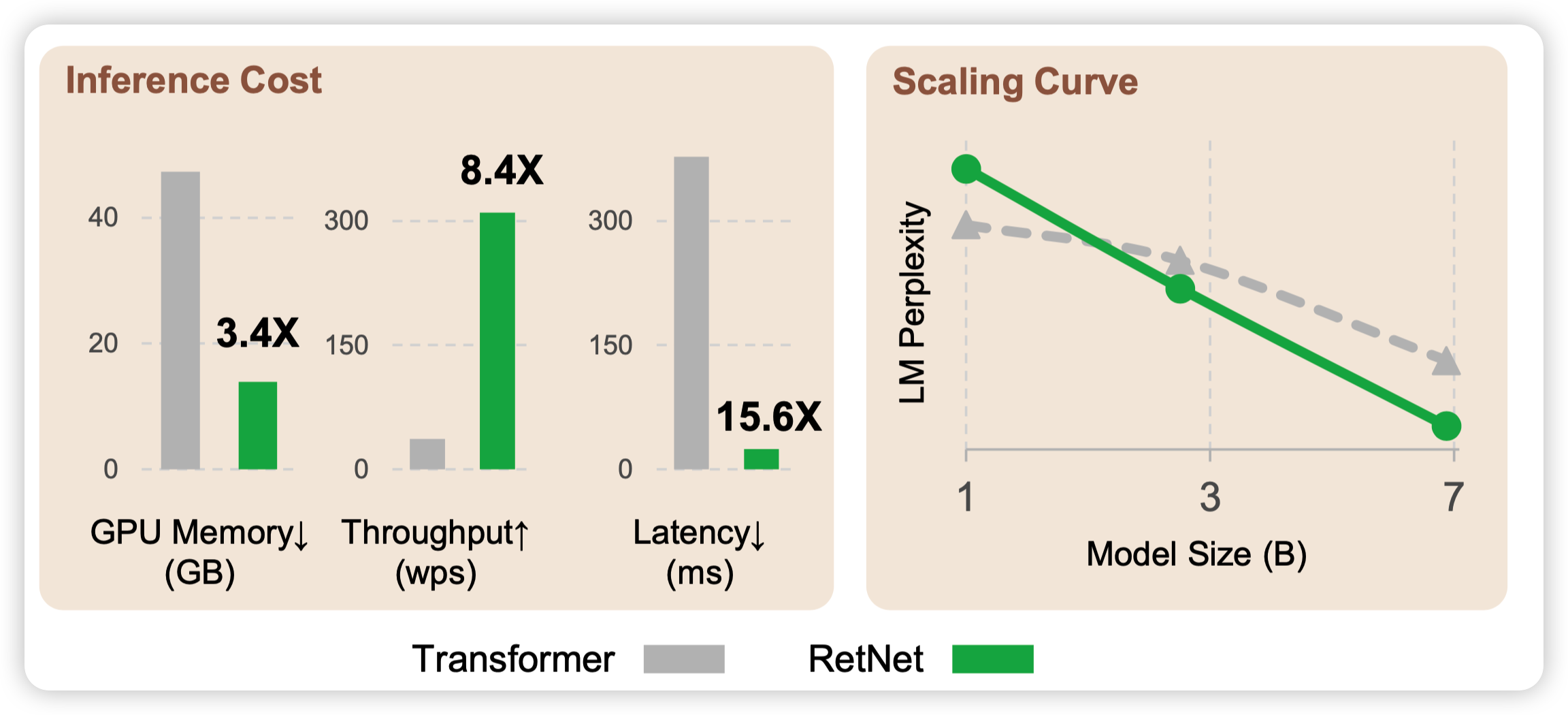
今天来讲讲被称为transformer "后继有模"的retentive network网络:速度更快、占用更少、效果更好。
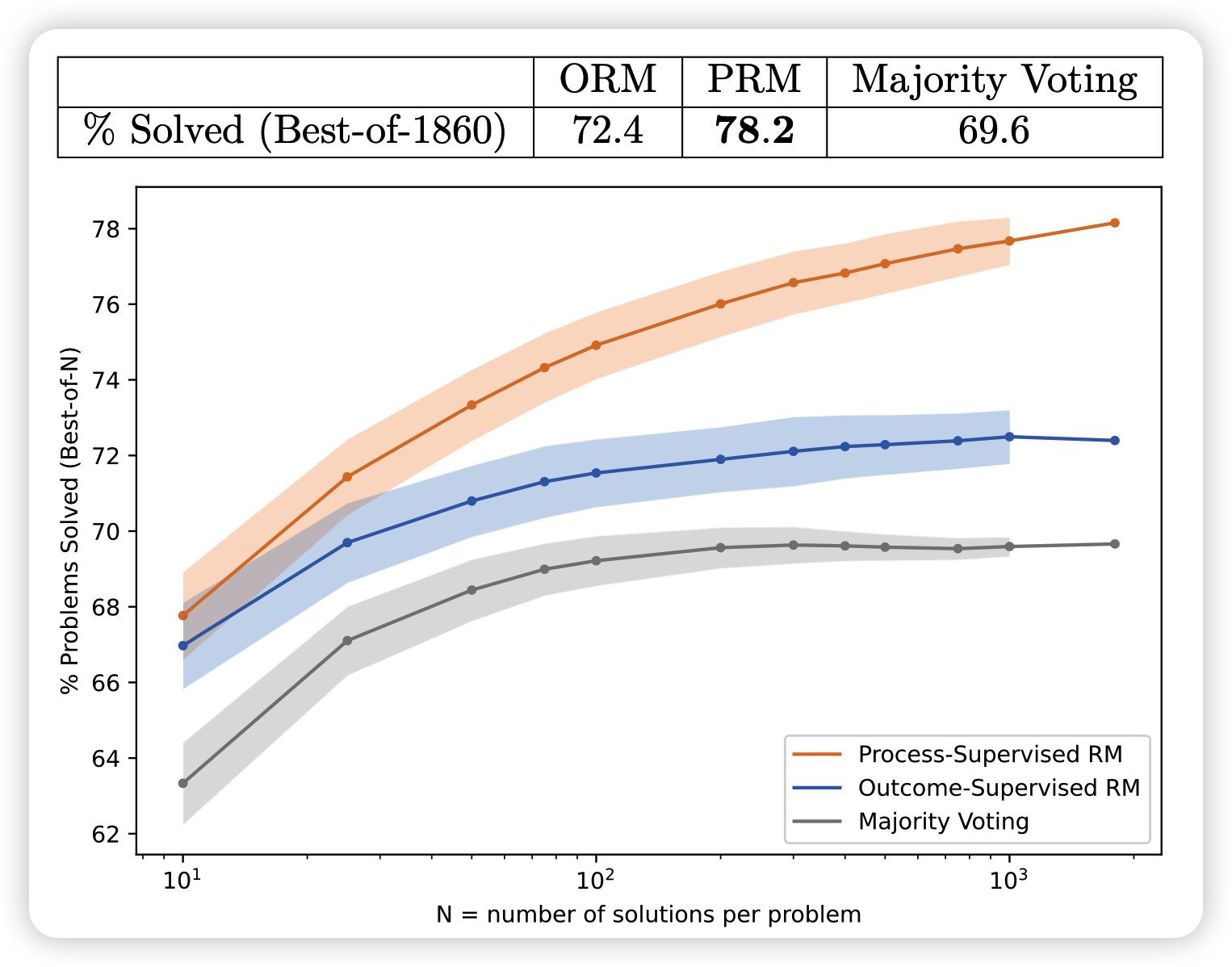
今天聊聊OpenAI 5月份发的一篇老论文:过程监督。这个说法是针对RLHF等技术的结果评价来讲的。他们使用过程监督的GPT4,在数学数据集上极大程度地战胜了结果监督的GPT4
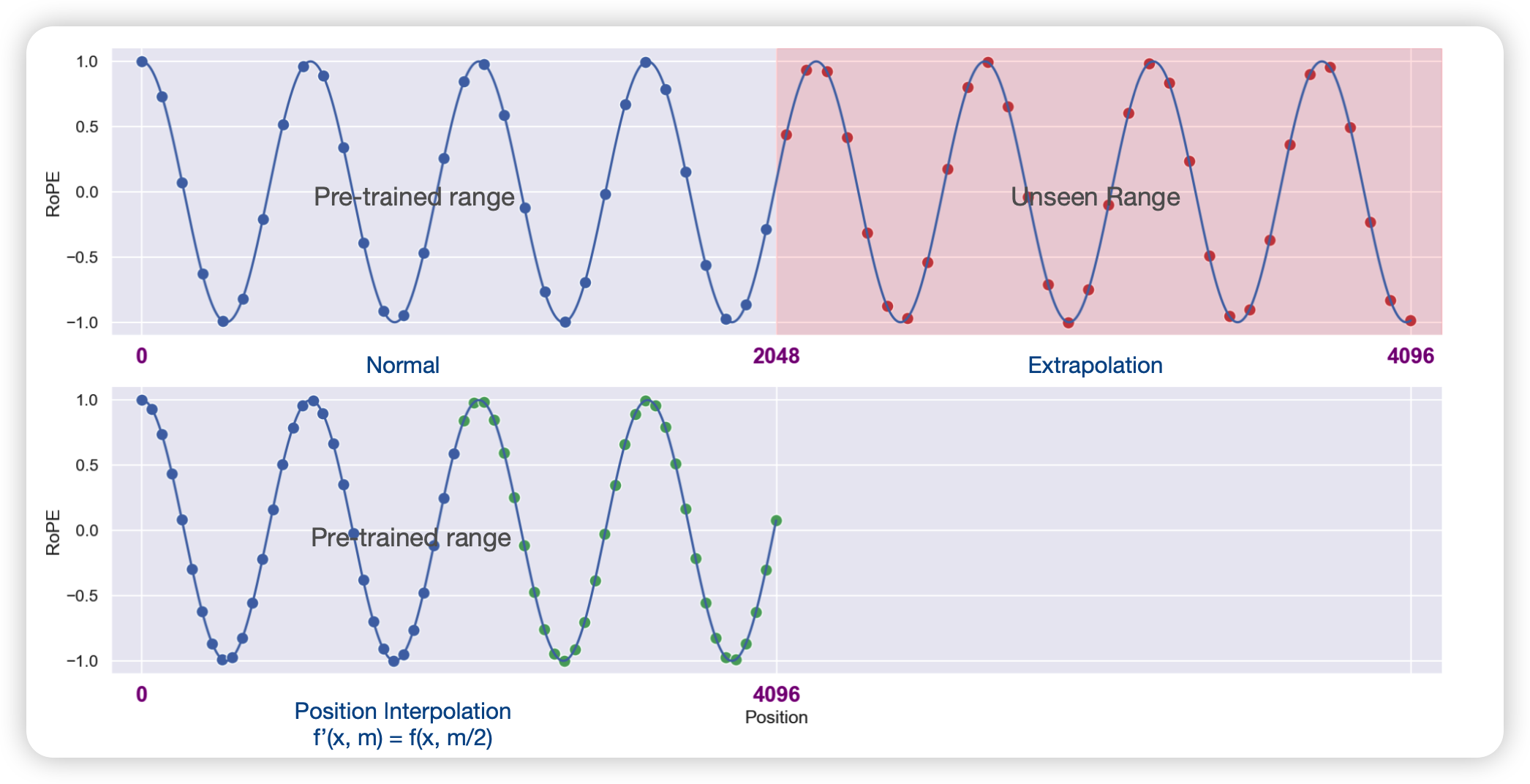
如何仅用1000步训练(0.01%资源)就将一个在2k context长度上训练的预训练模型的上下文窗口拓展到32k
我其实不想讲这篇,因为我觉得苏剑林老师肯定会讲,并且讲的比我好,但是感觉这个方法还是很有研究价值的,因此分享给大家……

不知不觉就毕业了。