
最近Apple出了自己的30B多模态大模型,涌现出了多模态的in-context learning效果,论文里一句"even better"让我想到库克那个嗓音……作者说明了很多在训练中收获到的经验教训,这是我最近几个月看的写法最清楚的一篇论文。正好借此讲讲多模态大模型:目前学界大火的VLM,到底是怎么跑的?
最近Apple出了自己的30B多模态大模型,涌现出了多模态的in-context learning效果,论文里一句"even better"让我想到库克那个嗓音……作者说明了很多在训练中收获到的经验教训,这是我最近几个月看的写法最清楚的一篇论文。正好借此讲讲多模态大模型:目前学界大火的VLM,到底是怎么跑的?

最近Sora巨火,仿佛开启了AIGC的新时代。Jason Wei表示:"Sora is the GPT-2 moment" for video generation。我在sora发布的大约第5个小时读了technical report,里面最打动我的其实是没提什么细节的recaption技术。让我回想想起了之前读DALL.E 3论文时的愉快体验。
所以今天来分享一下DALL.E 3论文里的recaption细节,并讨论几个问题和我的看法:1)OpenAI教你为什么要"先查看原始数据,再做创新" 2)Recaption和大家一直在聊的"training on synthetic data"是一回事吗? 3)recaption技术是否已经在(或者即将在)被其他领域使用?
另外,我总结了一下上篇笔记阅读量大的关键:语言表达要浅显易懂些,所以这篇笔记我可以声明一下:没学过AI也能看懂(我在博客里加了这个标签"from scratch",所有我认为不懂AI或者只知道一点点的人也能看懂的博客都会加上这个标签)
参考文献:
https://openai.com/sora
Improving Image Generation with Better Captions
Automatic Instruction Optimization for Open-source LLM Instruction Tuning
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
Reformatted Alignment
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling
今天是2月29日,我迎来了研究生的第二个学期。上次2月29日已经是2020年,而下次2月29日要到2028年了。人生有多少4年,再加好久没有更新,遂写一写最近的生活吧。
其实我写总结这个track,还是因为最开始看了谭院士的博客 Wandai Blog:谭院士总是时间驱动,每天写一个sentence-level的总结,陆陆续续竟然坚持了十几年。时间是有惯性的,有点类似于顺着一个人的微信刷pyq,不会到了某个位置突然被卡掉,看下来有种震撼人心的感觉。所以我也想是不是记录一下自己的生活。
我当时选了另一种形式:事件感想驱动,更大的interval, 在corpus-level做记录,所以给自己起名字叫做"随缘"。现在想想可能并不适合,我和谭院士的记录方式也许应该倒一倒。我的生活当然没有谭院士丰富,用instruction tuning的话说:每天翻来覆去总是从一些task set里先sample task \(t \in \mathcal{T}\),再sample \(x \in \mathcal{X}_t\),最后预测 \(y = me(x)\)。做得多了,熟能生巧,常用的几个task的能力越来越高了,但一直没什么机会探索更大更diverse的instruction空间。
不过近期确实有所不同,我深感在过去一个月里,尝试的新事物堪比过去一两年。
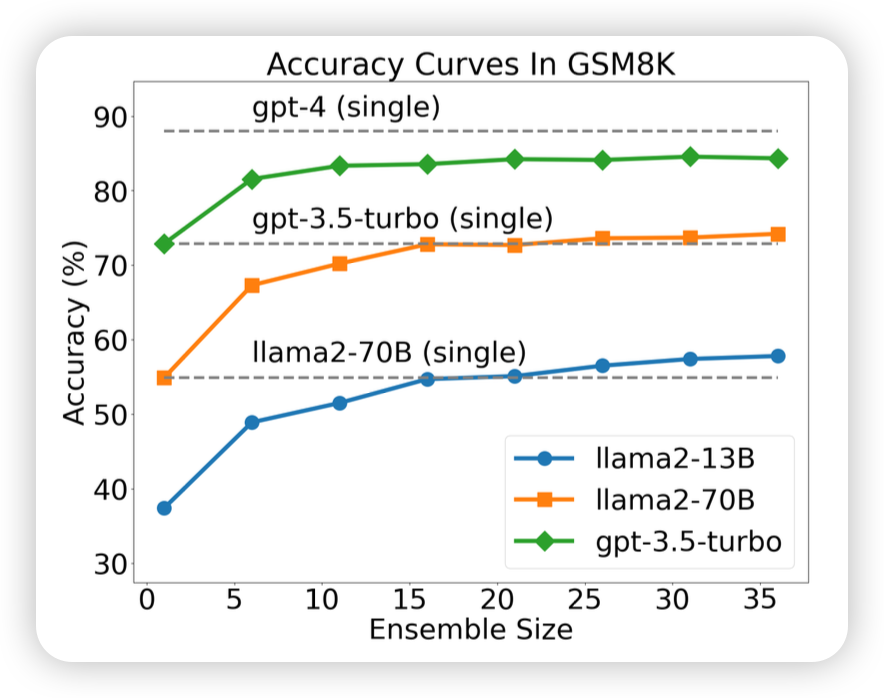
好久不更新了,看到之前大约都是15天更新一篇笔记,最近不知道咋回事竟然一个多月没更新,正好这两天刷到了"More Agents is All You Need",就来讲讲“时间换效果”的鼻祖——self-consistency。如果让模型sample多次,然后做major-voting,效果会更好吗?
参考文献:
Self-Consistency Improves Chain of Thought Reasoning In Language Models
Escape Sky-High Cost: Early-Stopping Self-Consistency for Multi-Step Reasoning
Universal Self-Consistency for Large Language Model Generation
More Agents is All You Need
Unlock Predictable Scaling from Emergent Abilities
上次写总结还是在2023-9-29, 没想到下次再写竟已经是3个月之后了,到了2023年的最后一天。每到年末,各种APP就喜欢来个xxx年度总结:B站总结、steam总结、网易云音乐总结……不过今天看到一个"新华社年度十大新闻"觉得挺有意思,我就想,能不能给我自己也列一个"年度十大新闻"呢?

上周刷到了刘鹏飞老师的 Alignment For Honesty, 分享给了大家 2023-12-13-insights。里面讲到如何训练LLM变得诚实,他沿用了孔子的定义:
知之为知之,不知为不知,是知(zhì)也。
To say “I know” when you know, and “I don’t know” when you don’t, that is wisdom.
我来一起看看他们是怎么做的吧

昨天OpenAI一口气更新了两篇论文,暨DALL.E 3之后的又一更新,其中一篇讲述了一个朴素的问题:如果未来的模型超越人类了,我们该怎么给他们提供监督信号?(毕竟我们只有人类——一个相对更弱的模型)
OpenAI把这个问题叫做weak-to-strong generalization在这里做了一些简单的尝试,对于这个问题的性质进行了一些探索。我们来一起学习一下他们看问题和解决问题的思路吧!
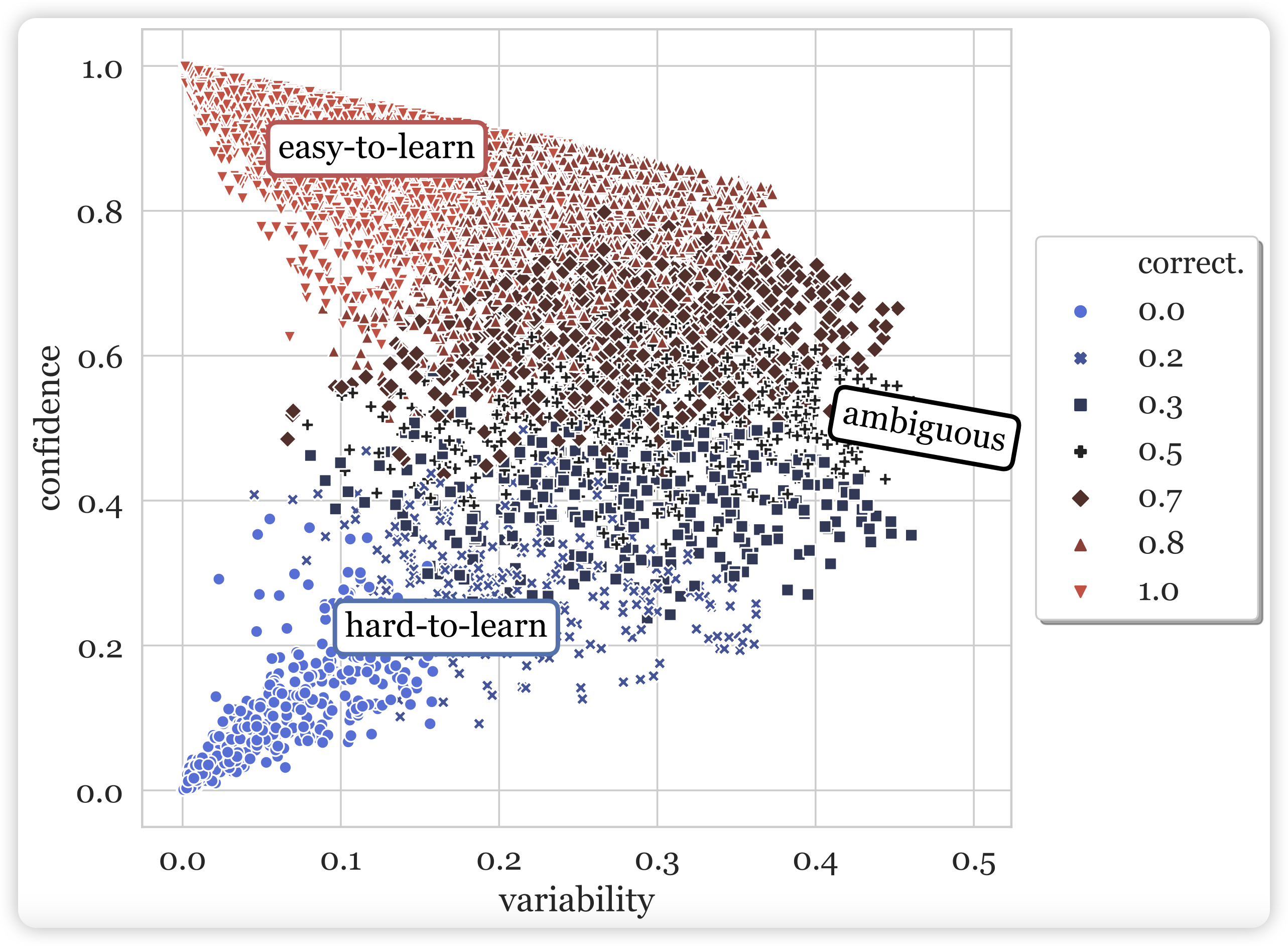
读得论文多了,写的笔记反而更少了……很多篇论文都想写,最后哪个都没写出来。今天来讲讲yejin Choi 2020年的一个论文:如何用模型自己在训练过程中的表现作为自监督信号,衡量训练集中每一条数据的质量?
很难想象这是yejin choi三年前思考的问题,我直到最近读到这篇论文,还觉得思路很新颖、很精妙
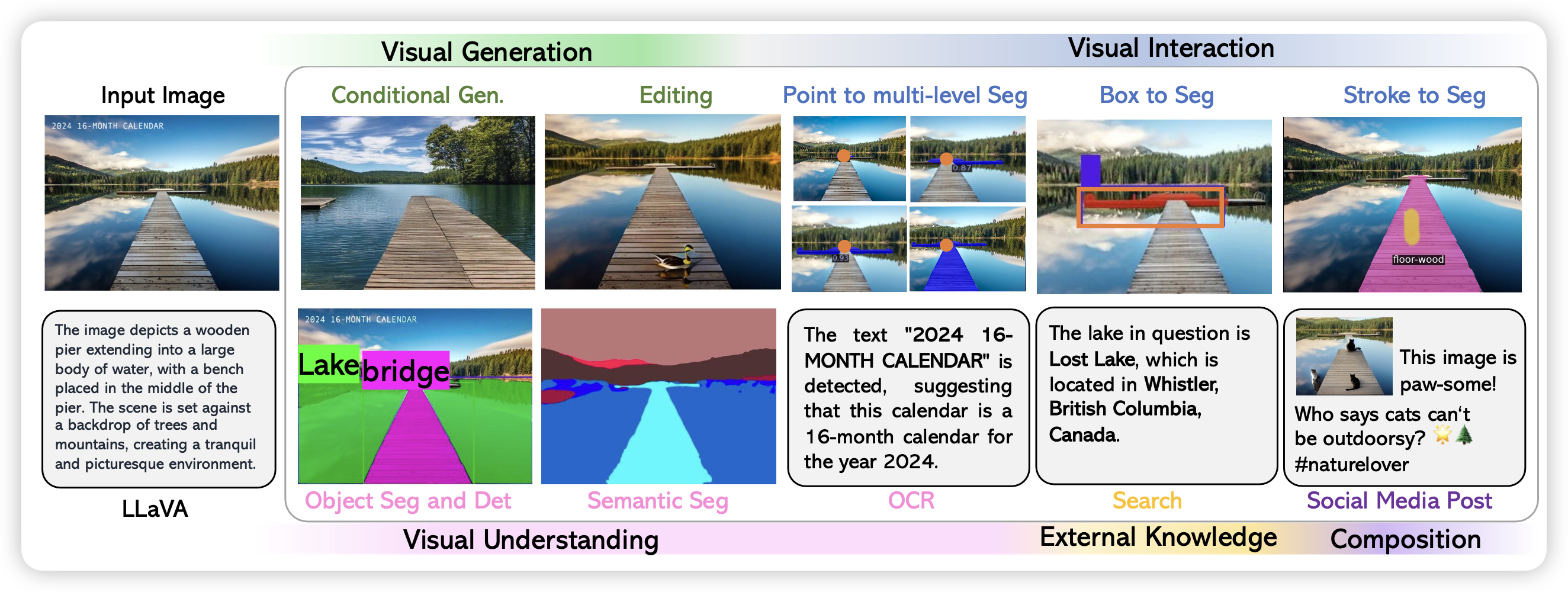
昨天刷到新挂的LLaVA-Plus的Arxiv论文,讲怎么做多模态的ReACT与训练模型。正好发现LMM(Large Multimodal Model)系列的模型似乎怎么讲过。那么LLaVA系,三篇论文,今天一次说完。
flamingo、Kosmos 2.5下次有时间说啊
众所周知,OpenAI打算在2023/11/6,ChatGPT问世(2022/11/30)大约1一年以后,召开第一届开发者大会,距离现在还有15天。我们不如来大胆预测一下开发者大会可能更新的所有内容吧!即是预测,也是我对OpenAI接下来开发的功能的期望。你觉得哪种结局最有可能呢?
所有图片均由DALL·E 3生成