最近发现有些好玩的工作甚至也没挂AI track,现在我每天把AI track和CV track同时看一遍……正好今天GUI Agent工作大爆发了,全列一遍
NeuroClips: Towards High-fidelity and Smooth fMRI-to-Video Reconstruction
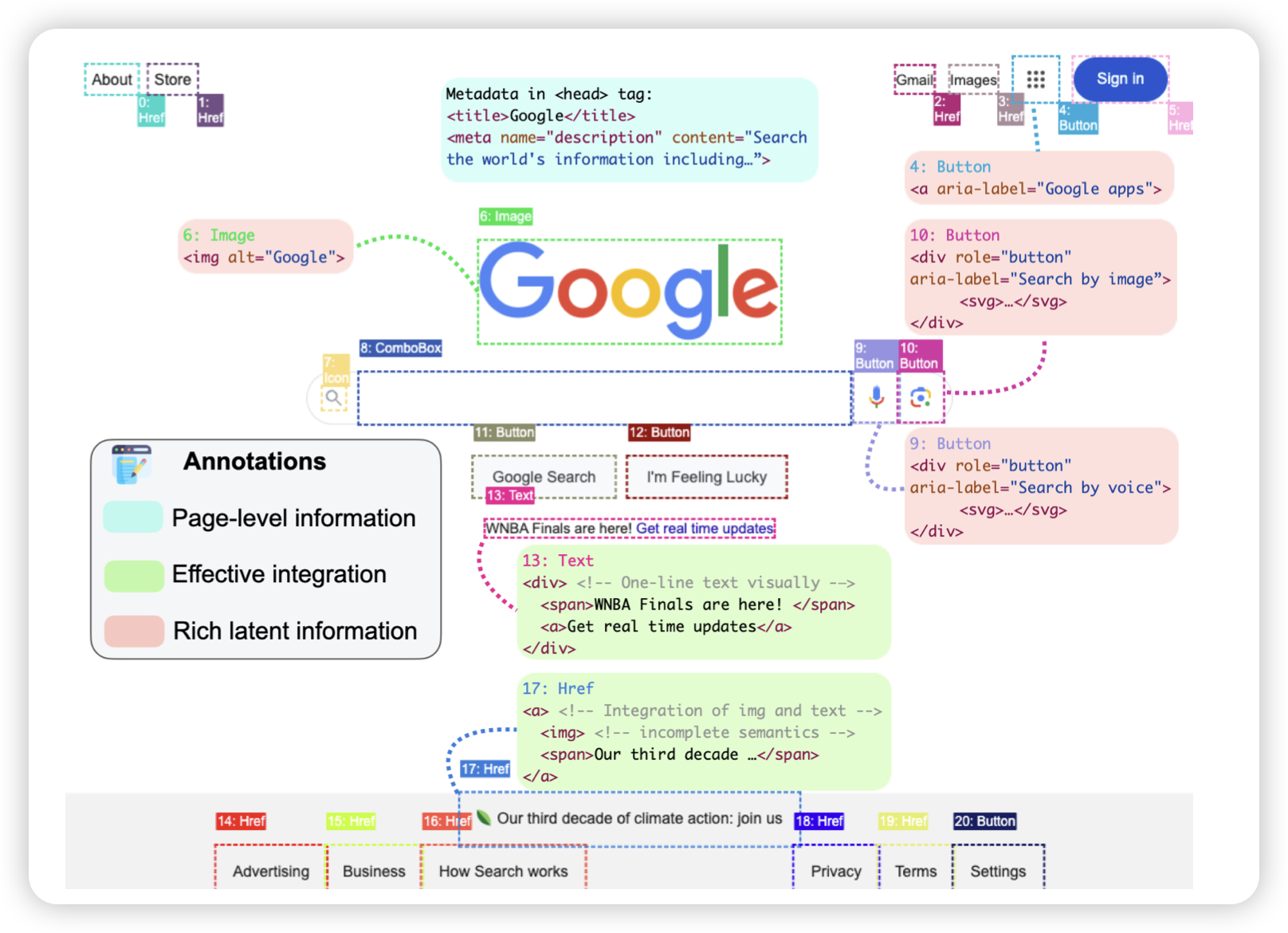
一篇做fmri重建的工作,想把人脑子里想的东西通过视频生成的方式搞出来。我记得之前看到过一篇生成图片的工作。
感觉研究这个方向挺好玩的,估计我研究的话每天有动力早起写代码
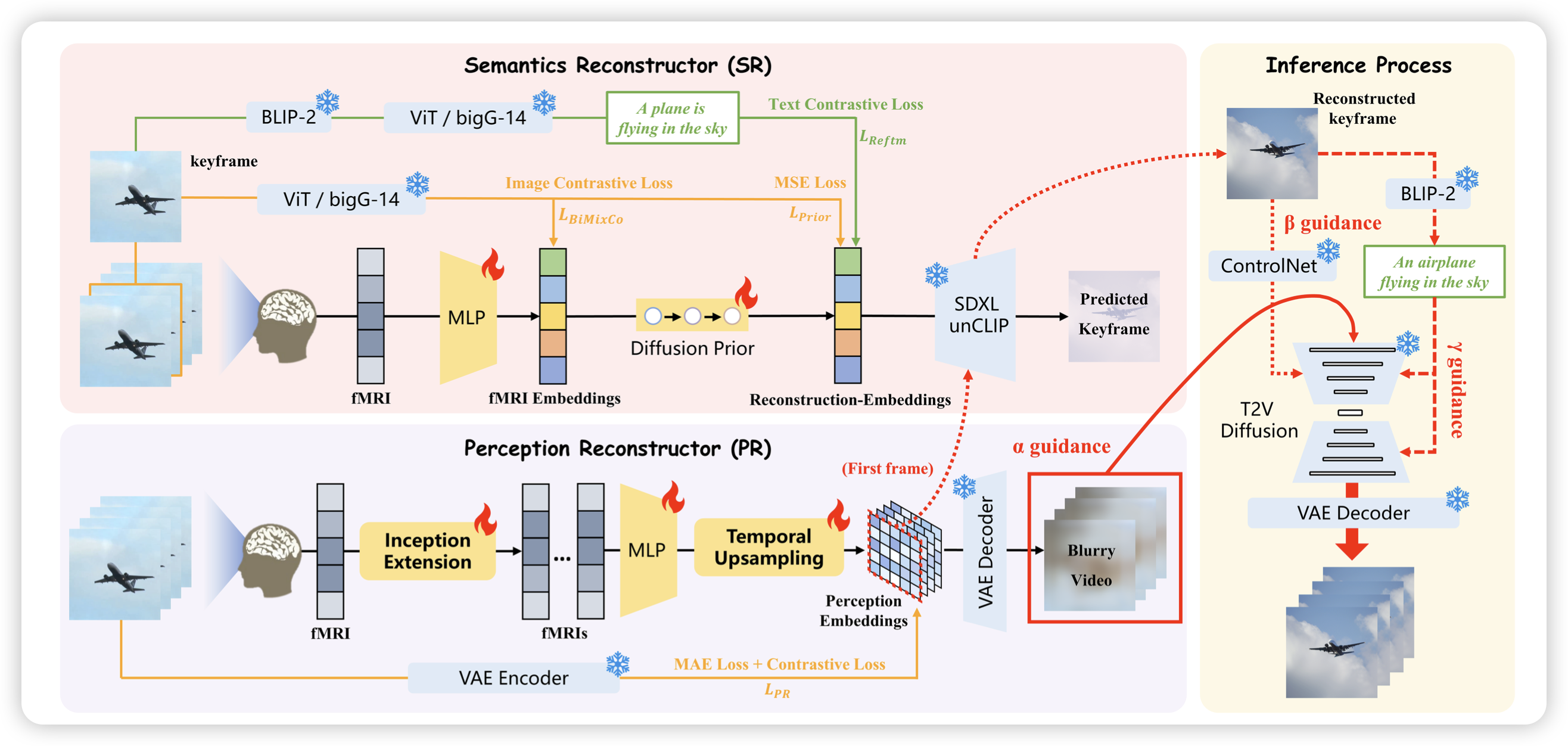
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
如果大家还记得visualWebArena,今天出了个videoWebArena。也是benchmark类的工作,作者认为目前的GUI Agent都是VLM或者LLM,没有人考虑过视频理解。所以作者设计了2000个必须要有视频理解能力才能解决的GUI Task
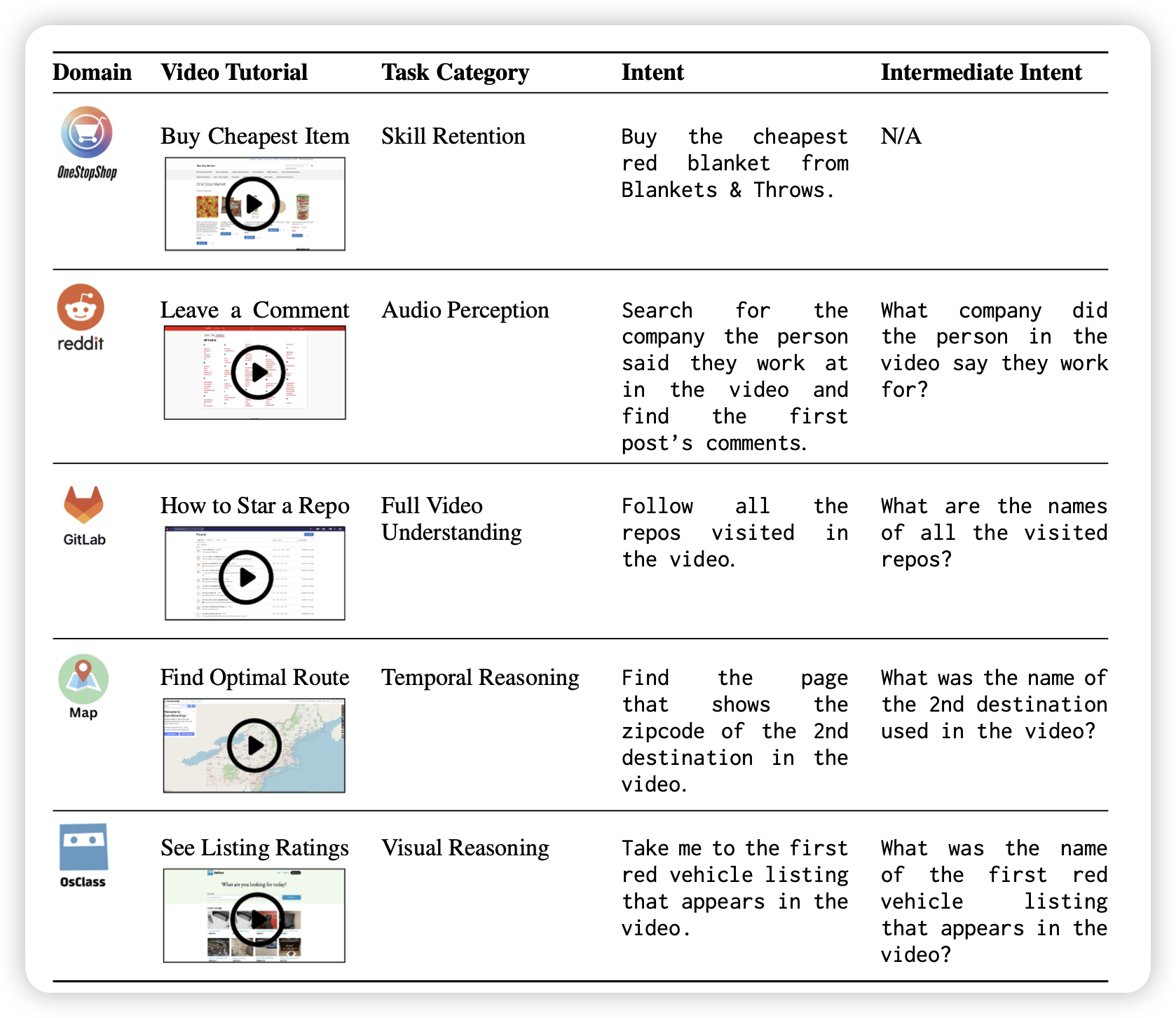
OpenWebVoyager: Building Multimodal Web Agents via Iterative Real-World Exploration, Feedback and Optimization
了解 GUI领域的人,一定知道1月份的时候有个叫webvoyager的工作,主要是通过Prompt + GPT-4v增强做的GUI Agent。今天同团队出了训模型的工作,还挺solid的。先用4o的数据做SFT,后面接了个offline RL pipeline多轮迭代增强自己。
其实和这个最像的工作是Kumar之前做的一个叫DigiRL的工作,他俩不知道比没比过
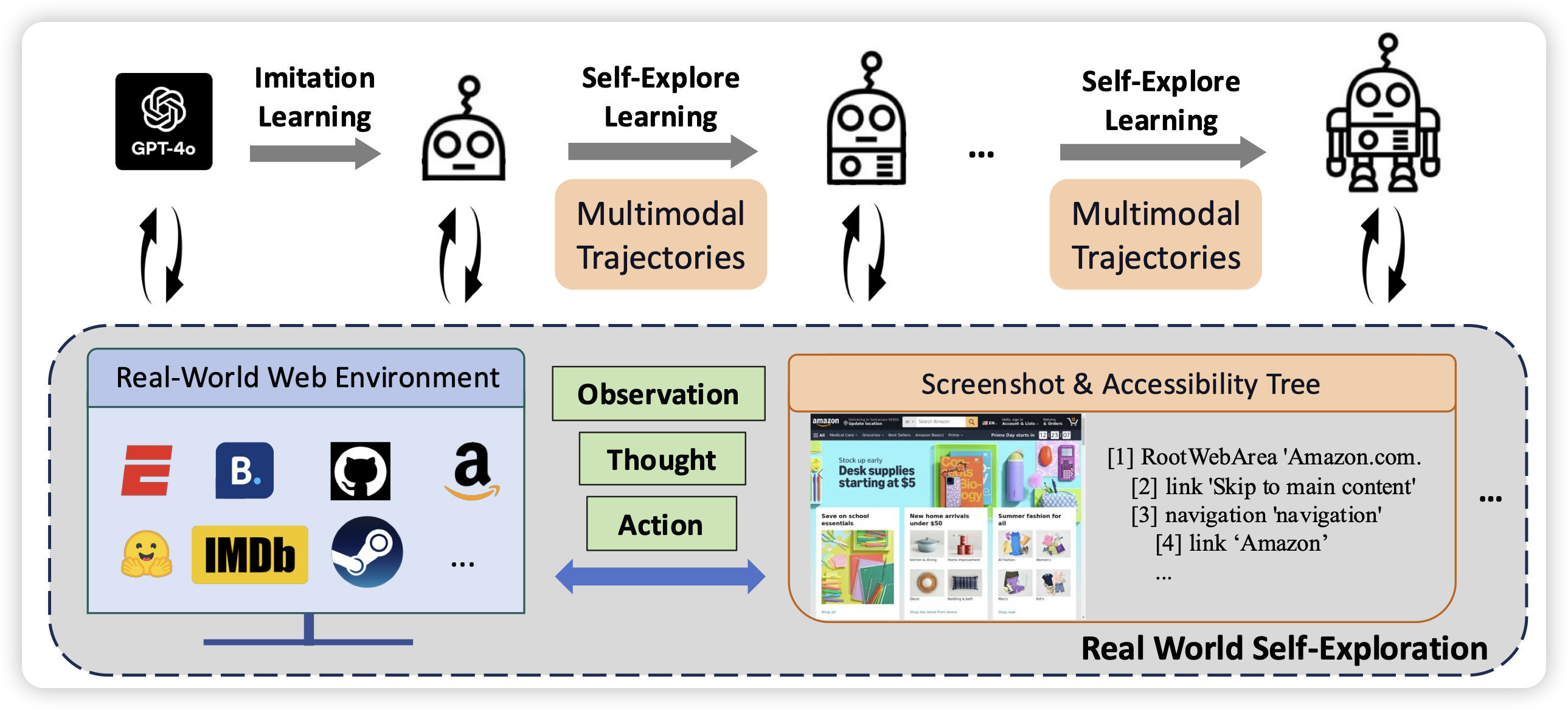
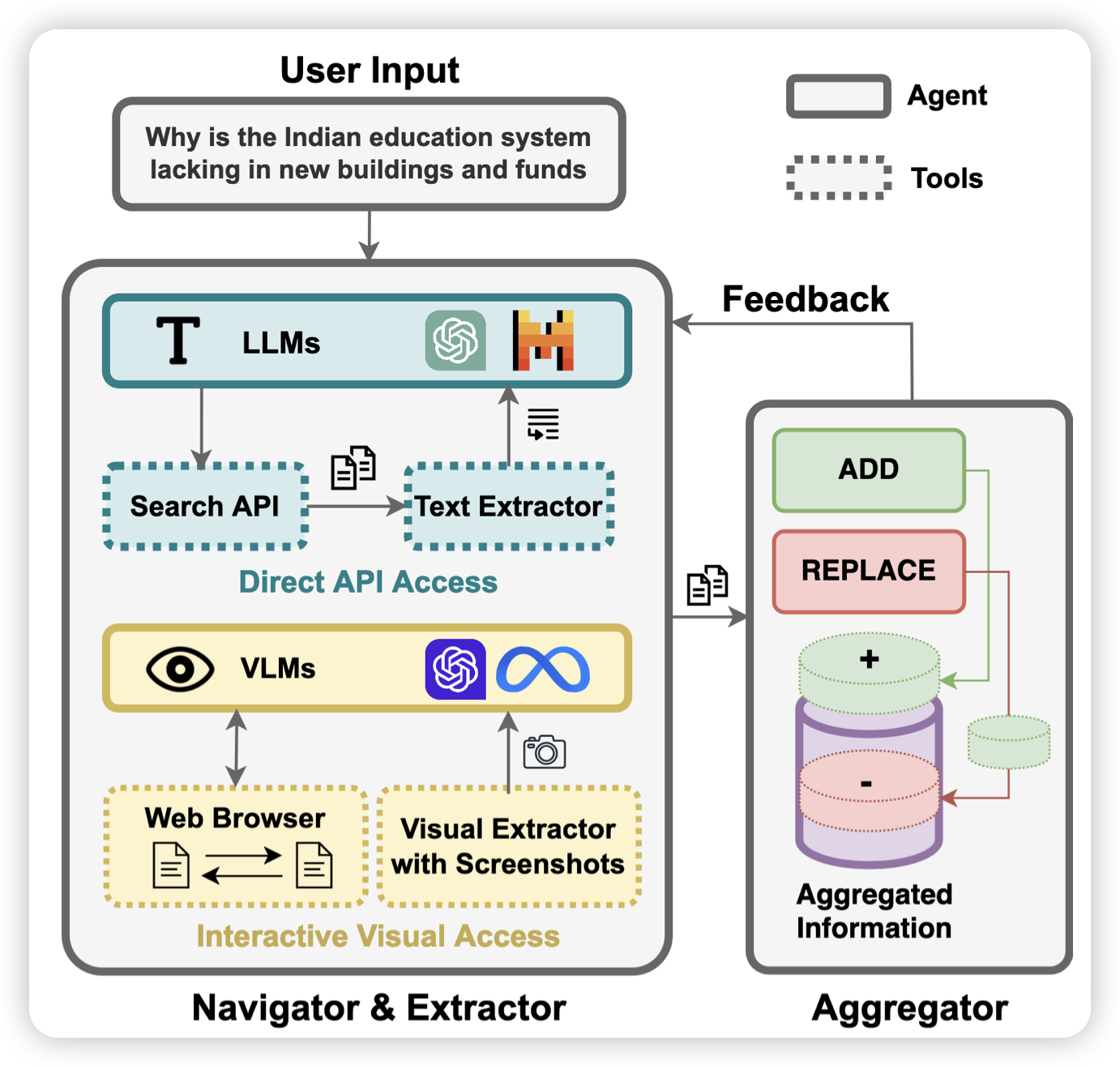
INFOGENT: An Agent-Based Framework for Web Information Aggregation
Heng Ji老师的工作,聚焦到了information seeking场景。作者发现,已有数据集基本上把information seeking认为成只有一个对应的数据源,作者开发了一套整合多个数据源、联立API和GUI两种动作空间的Agent。
联合动作空间的思路挺有意思的,后面是不是大家又发现GUI Agent和API-based Tool Learning是可以结合的……
EDGE: Enhanced Grounded GUI Understanding with Enriched Multi-Granularity Synthetic Data
一个新的webpage数据集的工作,大体上还是使用页面解析的方案,这个领域最近有nuebig做的MultiUI质量最高,这篇可能是被neubig卷到了吧