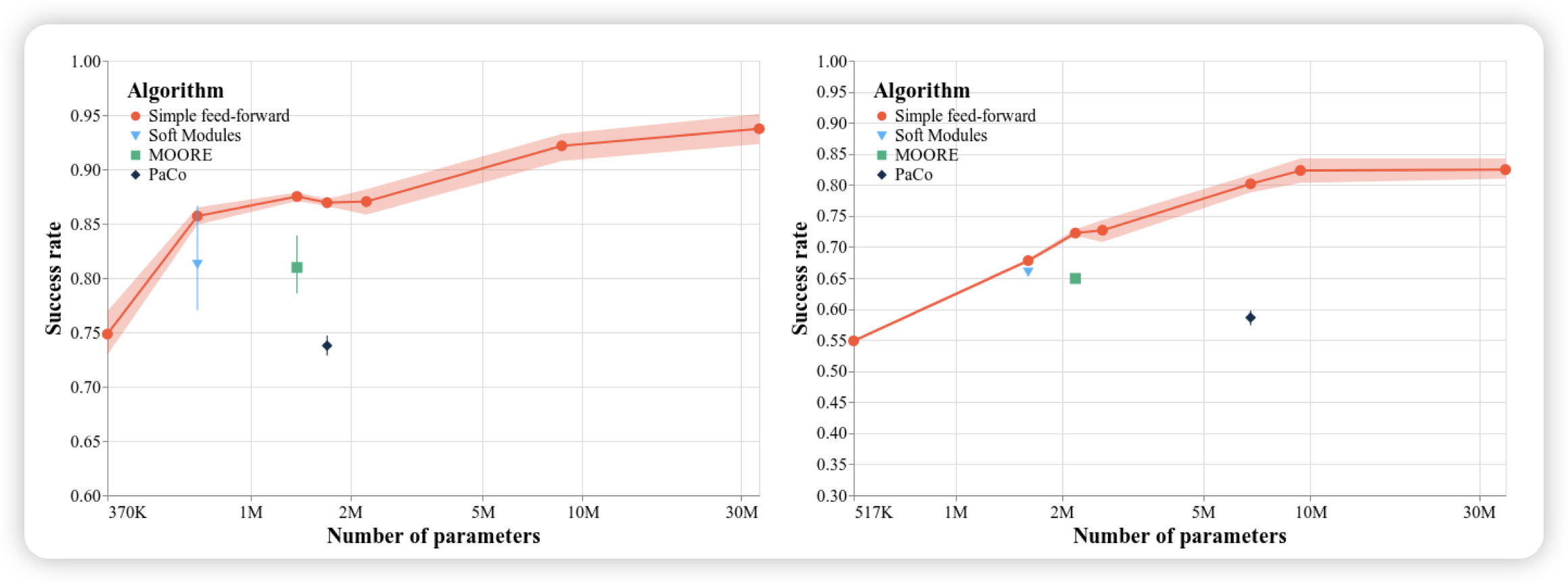
Multi-Task Reinforcement Learning Enables Parameter Scaling
这篇工作挺有意思的,之前有个multitask rl领域,是指用一个模型同时在一堆setting上训,可以把更大参数的模型训起来。与之对应的是,单独一个setting时,scaling模型参数是不会让效果上涨的。作者探索了一个问题:训起来更大的模型,是因为算法更好了,还是原来的老算法单纯加参数就有用了呢?作者发现,其实算法更新没用,老算法单纯加参数,几乎能获得100%的增量收益
所以在非o1场景,大家好像确实没找到一个比较好的scaling参数的方案……是不是setting本身太简单了呢?
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Ant group训的MoE模型,有一个300激活28B的大号版本。话说ant组论文挺少见的
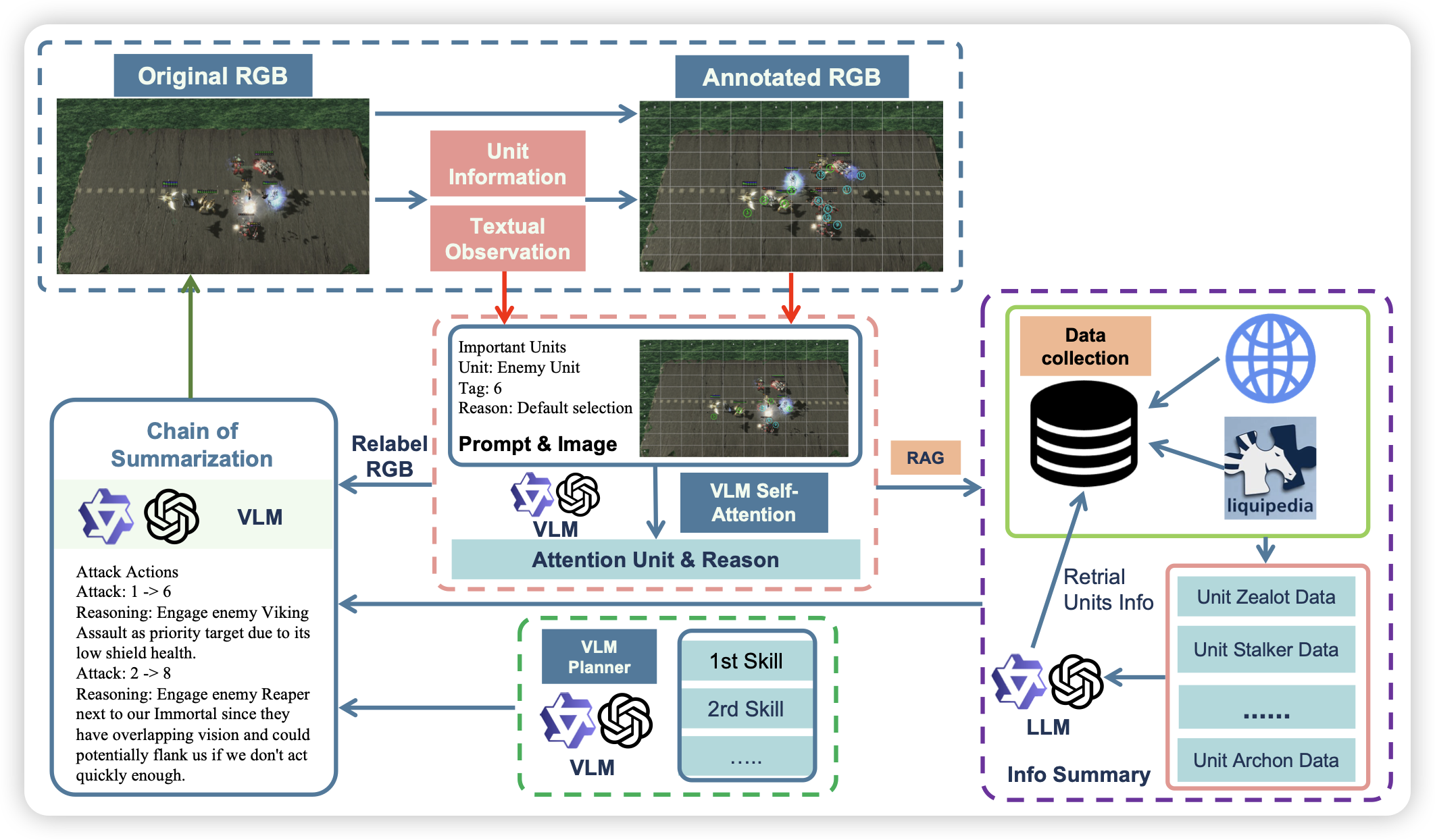
VLMs Play StarCraft II: A Benchmark and Multimodal Decision Method
从3.7玩pokemon到manus玩2048,感觉VLM+Game会成为今年的下一个热点。作者这次对starcraft做了封装,产生了对VLM比较友好的som形式的数据集,另外外接了知识库,做出了一个比较好封装的测试、训练框架