ViSpeak: Visual Instruction Feedback in Streaming Videos
这个工作很有趣,作者发现在流式视频模型里,除了问答场景之外,还应该开发更多可能,让instruction也脱离语言模态。比如说,我挥挥手,意思是再见,模型能不能理解?

Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
这两天gemini 2的原声双模态生成刚火了一波,今天deepmind就出了个双模态生成模型,这个是基于gemma训的。不知道这俩有没有关系
好家伙,小号开源大号商用……这不字节吗
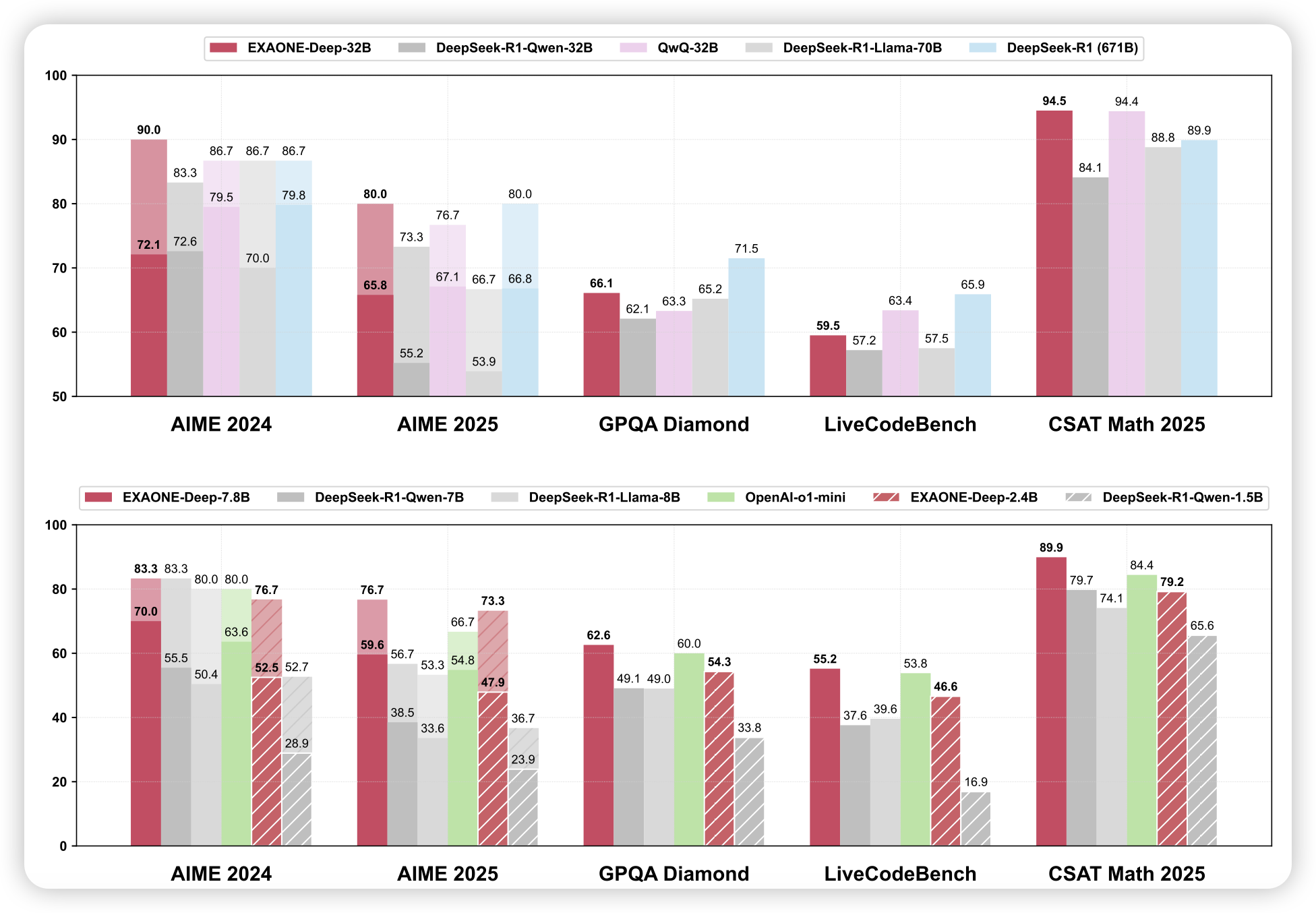
EXAONE Deep: Reasoning Enhanced Language Models
一个r1-like的工作:不错的分数,开源的模型。就是不知道刷榜严重不严重,感觉未来半年这种工作会越来越多。
Training Video Foundation Models with NVIDIA NeMo
Nvidia最近似乎一直在做这个Video Foundation Model的概念,上次出了个模型,这次把训练框架单独出了。
