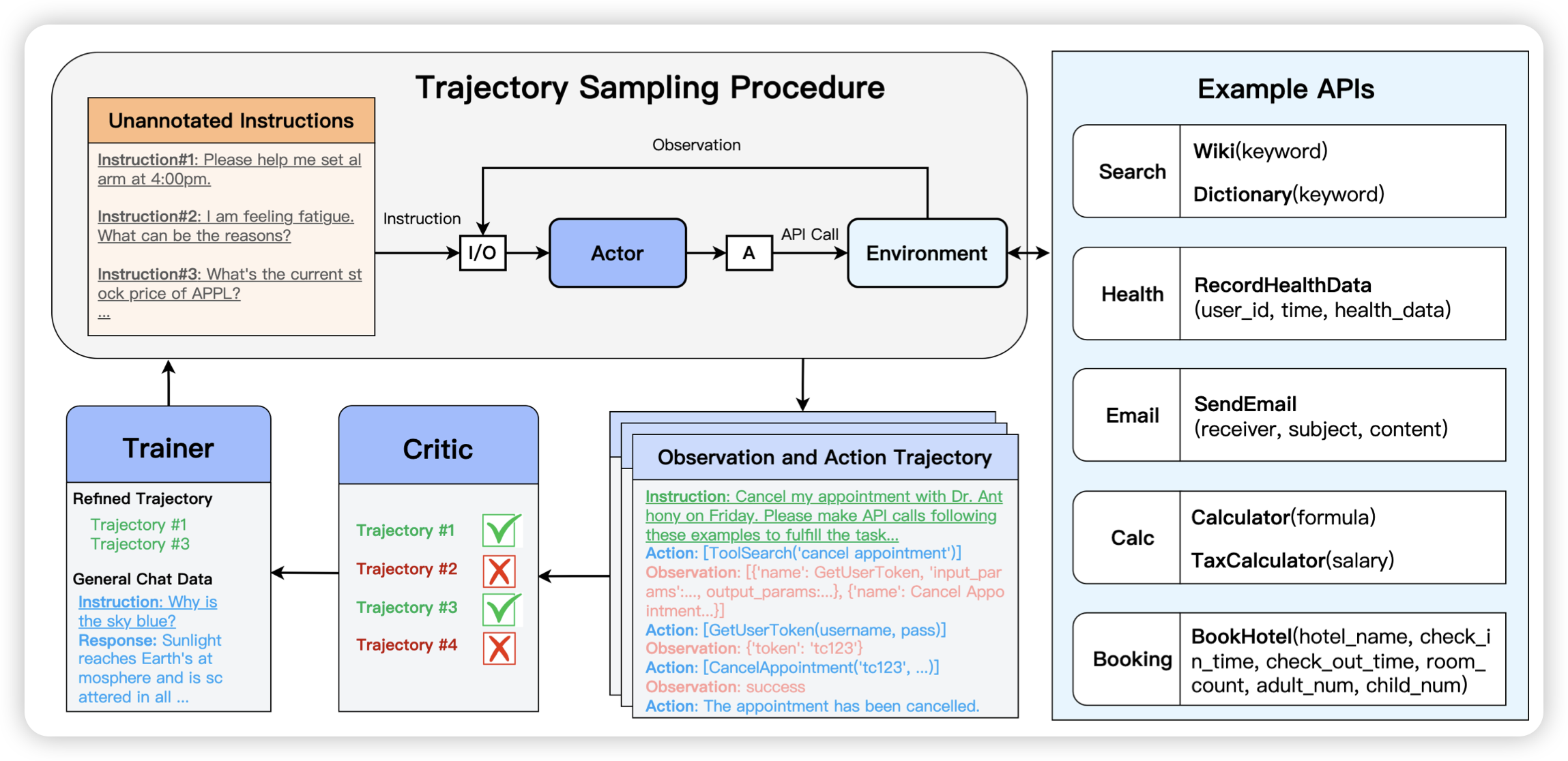
Training Agents with Weakly Supervised Feedback from Large Language Models
腾讯的工作,作者发现已有的agent训练基本都依赖无损的feedback信号,要么是从human trace做sft,要么需要依赖对于trace的result算法。作者想到:能不能找到一个critic LLM给trace做评价,然后筛出好trace,再训回去来涨分呢?作者把这个叫做Weakly Supervised Feedback
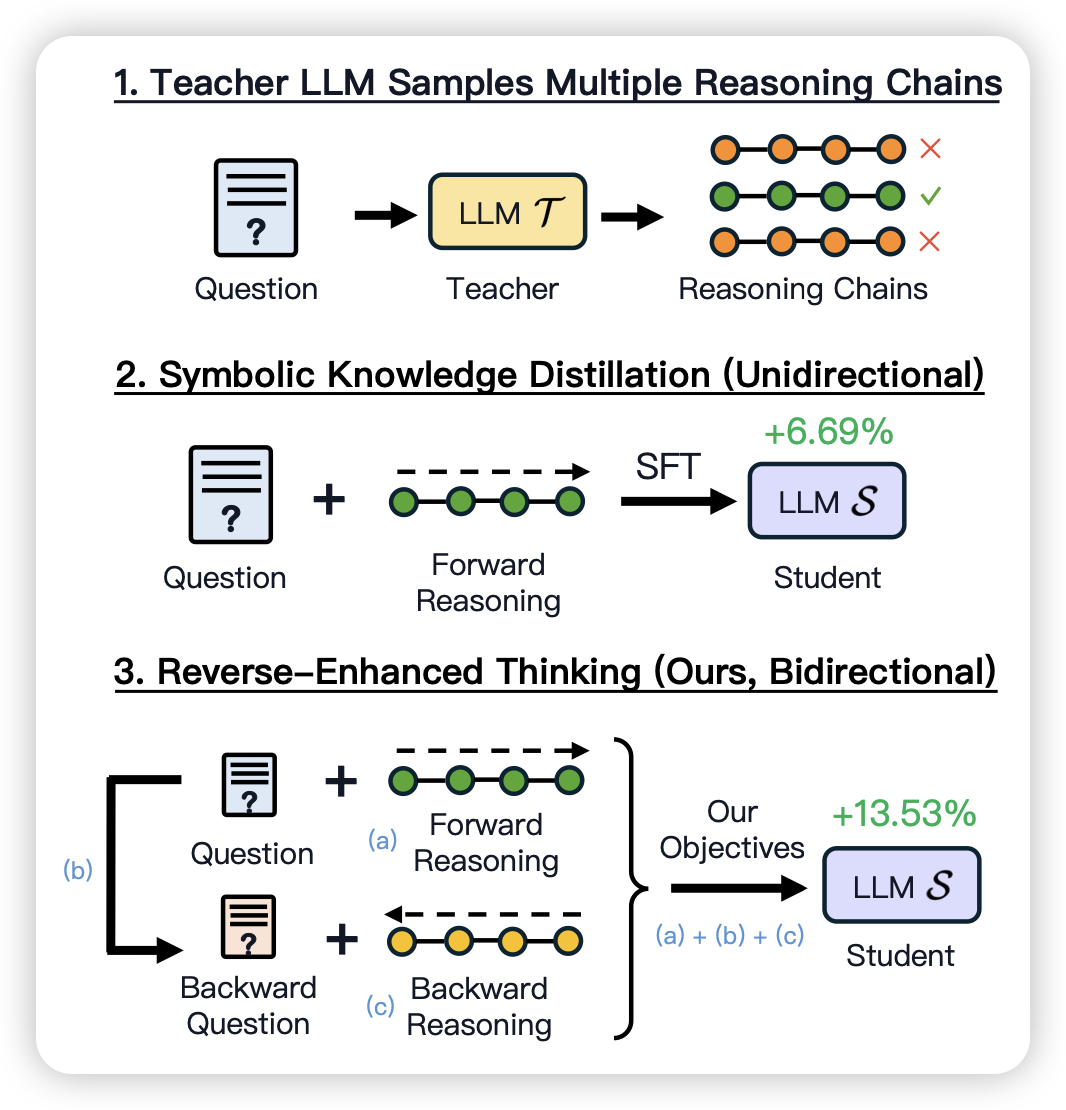
Reverse Thinking Makes LLMs Stronger Reasoners
一篇前o1风格的工作:作者发现在数学题等推理任务中,除了看到题目推导过程,人还会从结果出发倒推过程。作者构造了一些既包含正推理,也包含负推理的数据集,发现训出来的模型可以提分。