昨天没论文,今天一下挂出来一堆,质量都挺高的。
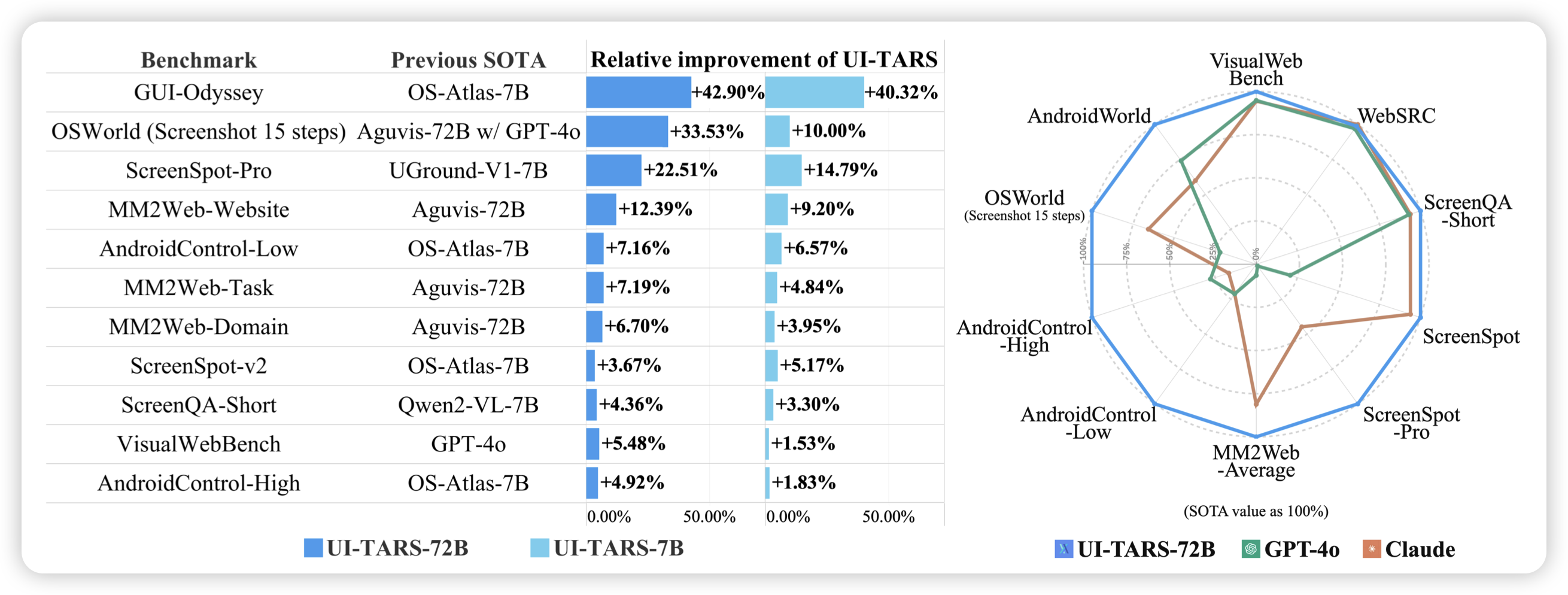
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
首先介绍一下我参与的工作(这篇不算今天的名额),一篇SOTA performance的native gui agent工作。我们之前做了XAgent,一个framework味道很重的gpt-based agent工作。这次我们想反过来:能不能去掉所有人类设计,只用一个模型,解决GUI的所有问题?
感知层面不依赖som、也不依赖页面解析软件;grounding层面,不做选择题,让模型输出坐标;action空间上,不提供各种function call的封装,而是原生的做点击、打字、手势操作;推理上,不依赖gpt、claude,而是让我们自己的模型说thought。如果可以做到的话,这个好处是显然的:把一个系统变为一个模型,就把这个任务建模成了data-driven的过程,代表着loss就可以在所有模块之间传播,进而对整体进行优化。世界本身是复杂的, 我们不应该去追求设计一个完美的framework,而应该去设计一个可以承载任意复杂度的系统,让这个系统自己在训练中重新去发现”framework“。(We want AI agents that can discover like we can, not which contain what we have discovered)
其实是个很俗套的故事,之前很多工作大家也探索了这个方向,但主要问题是在各个模块上其实都没有做到很可用的水平,所以才需要在单点能力上依赖外置模块来增强。我们花费了非常多的精力在各个原子能力的优化上,事实上你可能需要把所有的模块都分别地优化一遍、把所有工程的坑都踩一遍,才能为一个native的系统进行hotstart……
最终在各种实验中也发现:当你想办法把native系统scaling起来以后,最终会胜利的。最强的系统,不是agent framework,而是热启动以后的native agent model.
以后给大家分享阅读笔记: https://x.com/Yining_Ye/status/1881953603222684064
另外,这期工作主要是对data-driven的展现,如果迁移到verifier-driven上,会发生什么呢?
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
hunyuan团队今天挂出来了新的3D生成模型。
感觉这个领域最近发展势头挺快的,我倒是想到了另外一个事情:用3d生成的方式,和用视频生成+wasd移动视角的方案,给人在视觉上好像是等价的。大家觉得后者会更加scaling吗?

Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks
jiheng老师的工作,作者设计了一套mobile agent framework,同时还引入了夸任务的tip模块,让模型随着测试去积累经验。

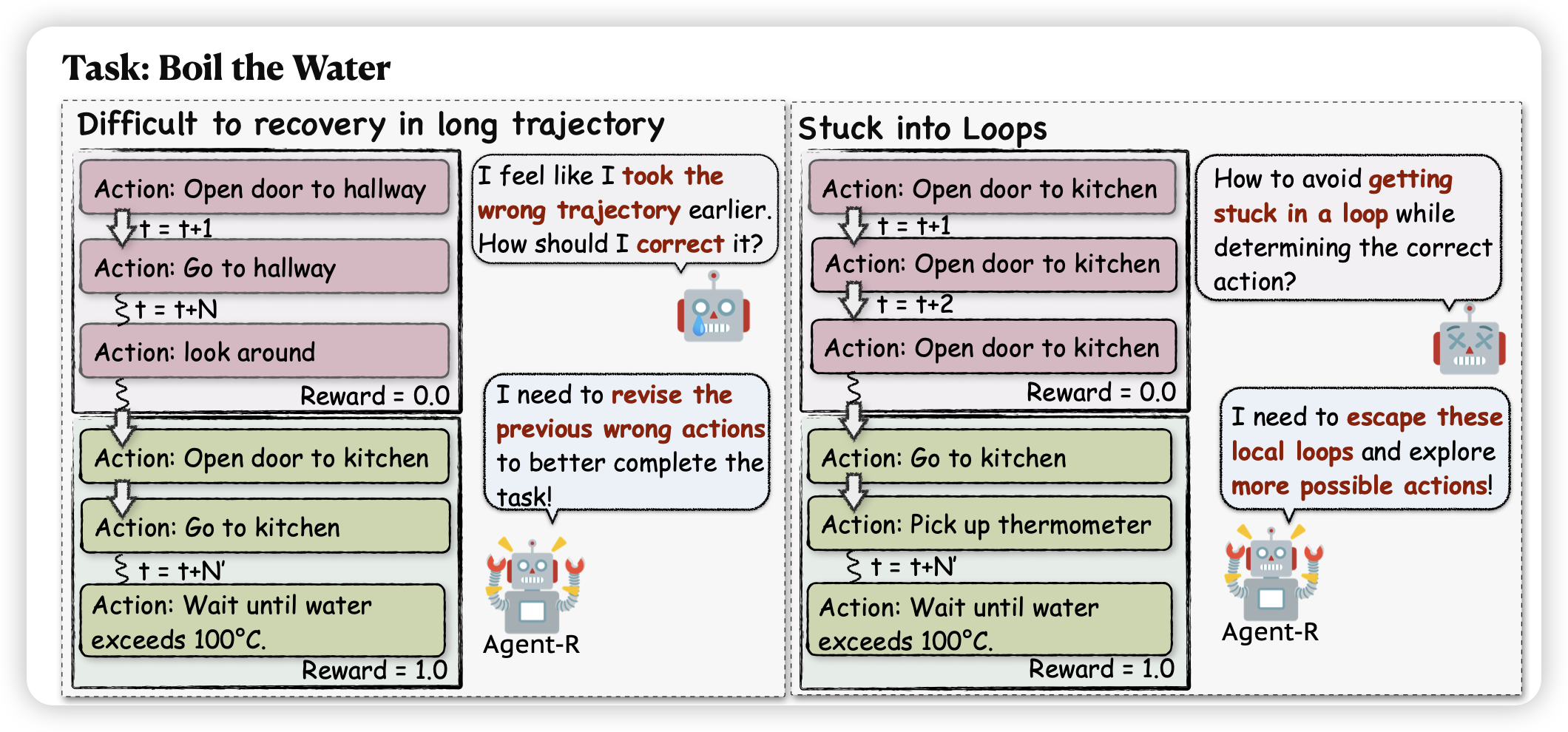
Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training
一篇合成数据的工作,作者想了一套基于MCTS的方法,合成了多步的agent trace,并希望在其中添加reflection等trace-level的meta-ability