最近几天,NeruIPS接收的工作陆陆续续都放出来了
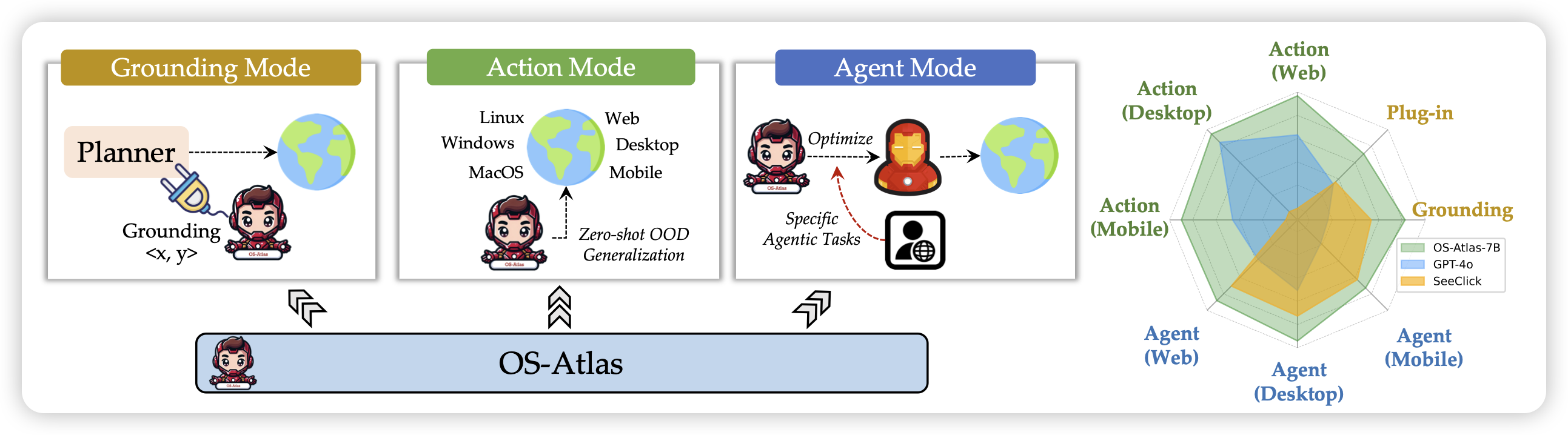
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
之前ICLR的一篇投稿论文,今天挂上arxiv了。有点类似之前那个Multi UI,作者设计了一个爬取引擎,爬了2M图片,13Melement,做了grounding训练。在下游任务上发现,提升了grounding能力以后,GUI Agent能力得到了飞跃。
这两天怎么噌噌出这类论文:昨天一个EDGE,前几天一个Multi UI,在前几天的UGround、AGUVIS
ReferEverything: Towards Segmenting Everything We Can Speak of in Videos
作者心很大,想要做video领域的Segment Anything。作者提到,生成模型的representations已经具有通用的表示能力,能不能在尽可能保留向量本身泛化性的基础上,小小地适配到refer任务呢?作者设计了一套pipeline,做到了这件事情。而且事实证明,模型可以效果非常好地refer到通用世界的各种神奇的、开放域的物体上。
不过有一说一啊,给出文字描述,输出位置信息的。这个任务叫做grounding……refer任务是给出坐标,描述内容

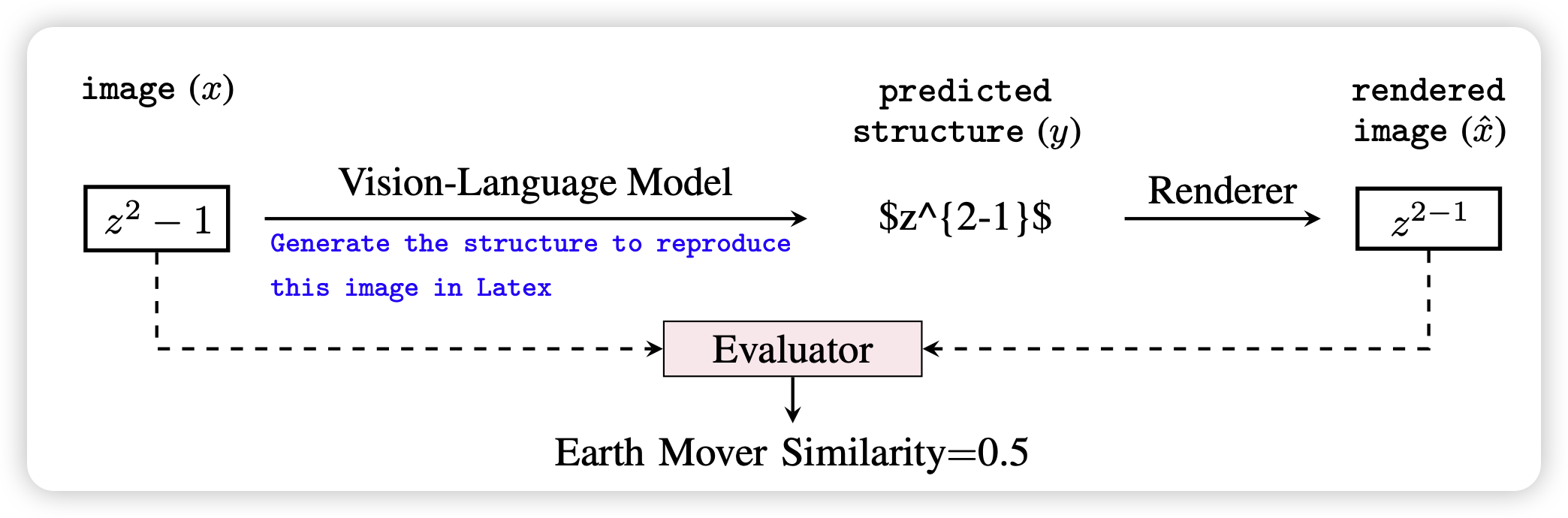
Image2Struct: Benchmarking Structure Extraction for Vision-Language Models
Percy Liang的工作,最近好像挺少见到他了。作者提了个很简单的方法:很多图片,比如网页、latex、乐谱,都是从结构化数据推导出来的。模型能不能从图片反向渲染源码,再通过把源码重新渲染,和原图做reconstruction,来对VLM给出评测呢?
这个思路其实在table understanding领域已经有一些工作了。他们会把table的源码丢给Text-LLM,然后用code intepreter集成的方式生成答案,再把答案作为信号蒸馏会VLM里。这里其实是把render engine的规则持续地蒸馏进模型参数里
SLOWFAST-VGEN: SLOW-FAST LEARNING FOR ACTION-DRIVEN LONG VIDEO GENERATION
一篇视频生成的工作:作者讲了一件事情,在视频生成中,对于action的预测是困难的,能不能用fast slow thinking那套理论来独立地学习对于action的预测,和action发生后世界变化的信息呢?作者构造了200k带有action language标注的video数据,由此训了模型,发现效果很好
所以video generation又开始找video LM的逆任务了吗?video LM里有一个 action recognition,抽取视频中所有的action。video generation这边就会有一个"action putting",把所有action给出来再生成……
