Focused Large Language Models are Stable Many-Shot Learners
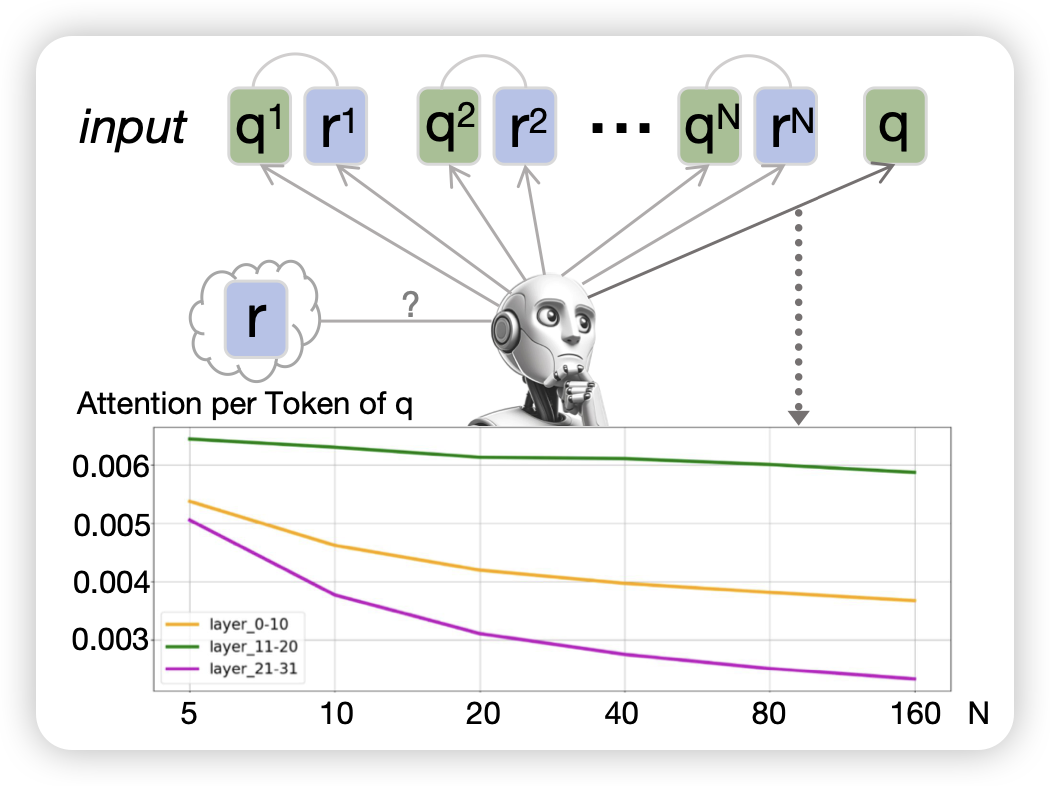
在many-shot场景,近期有研究发现LLM的表现不达预期。作者分析这个现象,发现一个简单的原因:当context很长以后,answer生成时的attention不会聚焦在query上,而是被in-context样本分散了。作者设计了一个简单的恢复方法,甚至结果还不错
颇有ACL遗风,论文挺有故事感的
Step-by-Step Unmasking for Parameter-Efficient Fine-tuning of Large Language Models
印度老哥的工作,作者思考了delta tuning这个场景:只微调少量参数来节省显存,同时获得正常finetune差不多的效果。作者设计了一套selective的框架,让模型自由选择学习哪些参数,通过loss大小作为feedback。
这个场景之前推荐过类似的论文,这里面其实有个反直觉的问题:如果我增加训练次数等方法来做更好地delta tuning,那到底是增加了算力还是减少了算力呢……