mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
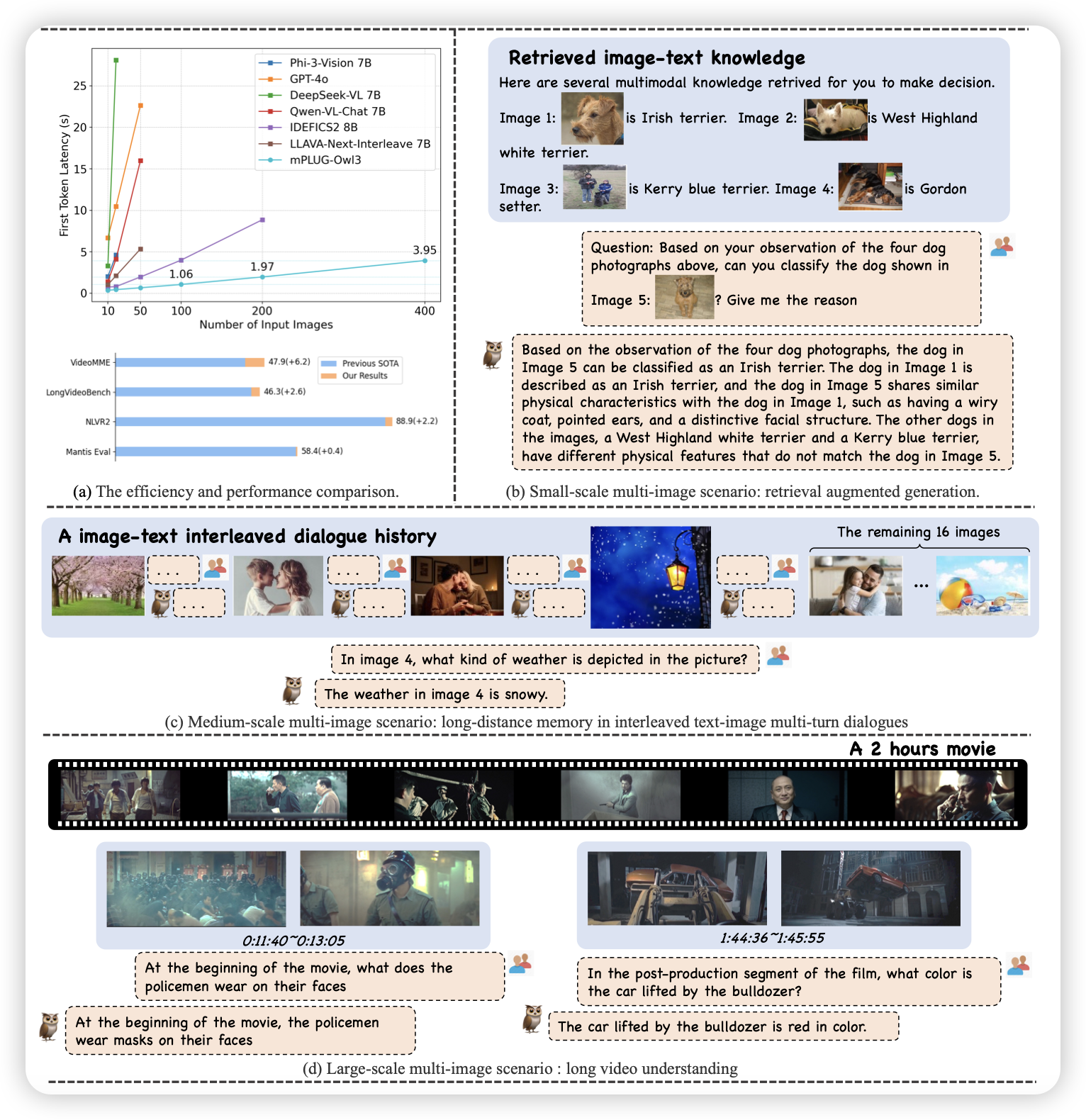
mplug系列的第三部作品,可能有些人对这个系列不太熟悉,这个就是阿里团队主推的VLM,对标qwen的。这次的第三代作者主打的概念是长文本,或者说在vlm叫multi-image。作者设计了新的数据构造pipeline生成数据,然后设计了高效地模型结构可以处理非常多图。
这一块我看到的比较早的是llava做的llava-interleave。感觉今年下半年的学术热点准备从VLM前移到multi-image VLM,或者说videoLM了