Handling Delay in Real-Time Reinforcement Learning
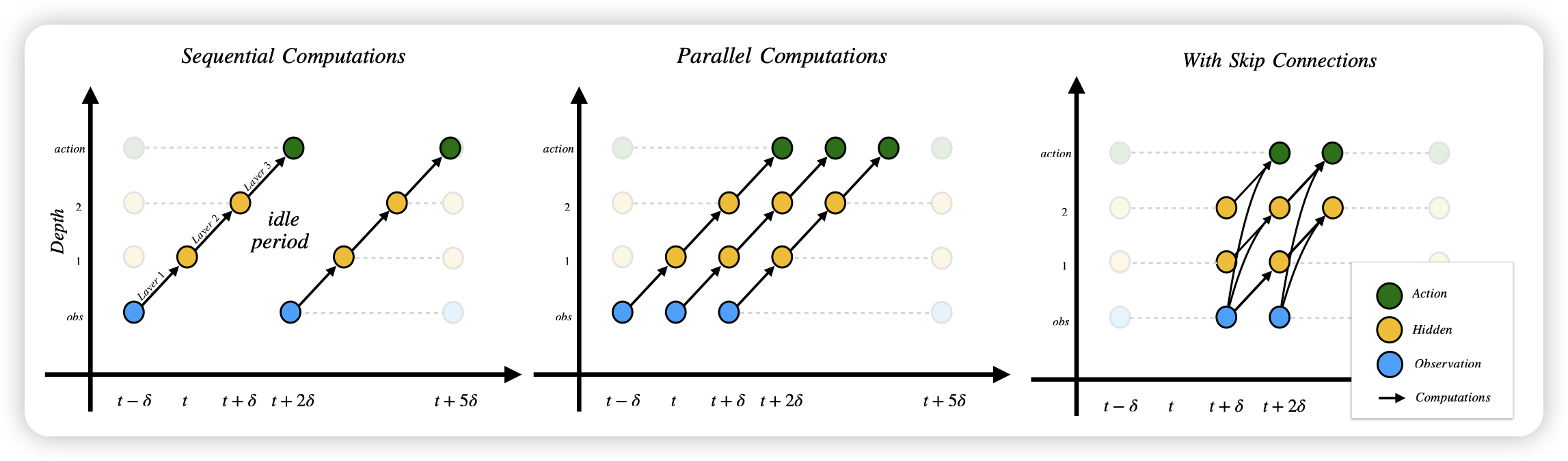
我很喜欢这篇工作,是一篇很“modern”的研究。作者发现,传统rl基本上都是一个可以暂停的环境,然后模型也很小,推理基本上是瞬间结束的,所以可以认为action产出是光速的,可以保证环境的causality。但当我们迁移到今天的rl agent时,你就会发现:模型的infer需要10秒,并且在这个时间里环境也不能暂停,比如你打cs,你见到人开始推理,等你infer完想瞄准,你已经死了。这个时候该怎么办呢?作者想到一个streaming的方案,能不能把模型在时间维度上做layer-wise的并行化,通过牺牲一定可解释性和效果,把适应延迟当成模型的一种能力训进去
他是真做过agent rl的……不过他这个方案似乎有两个问题:
- 这里讲了infer带来的延迟,还有另一个延迟,就是真实环境里,action的执行,到反映到屏幕上的时间,也会有延迟(网络延迟、渲染延迟)。
- 这个训练方案,等于锁定了延迟是一个固定的数值,我感觉是不是应该做一些domain randomization……毕竟你的延迟和推理速度是会波动的呀