最近不少iclr 25的工作都挂出来了,质量还挺高的。
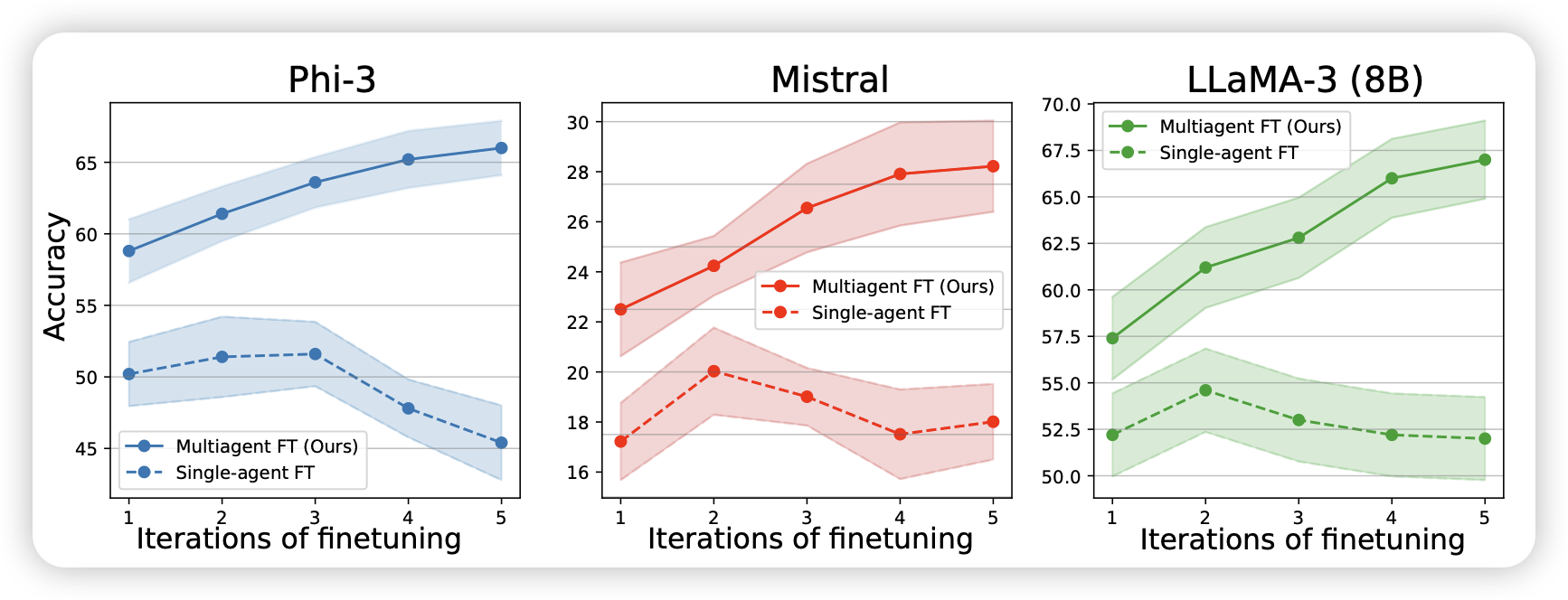
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
这篇工作探索了让一堆模型从一个ckpt出发,然后通过多agent交流的方式做任务。接下来,把整体成功的case调出来,然后训练回对应的模型去,然后观察multi agent整体作为一个系统,会不会随着self-train的增强而增强
Understanding Impact of Human Feedback via Influence Functions
这篇工作研究的问题挺好玩的:在大规模标注中,大多数标注员都是水平有限的。现在的反馈链路往往是像下面这样,在标注很多数据以后,再由数据委托方发现数据问题。但是,想把数据的问题定位回标注过程中是很困难的,所以作者希望找到某种influence function,可以直接从数据的问题找到对应影响最大的标注数据。