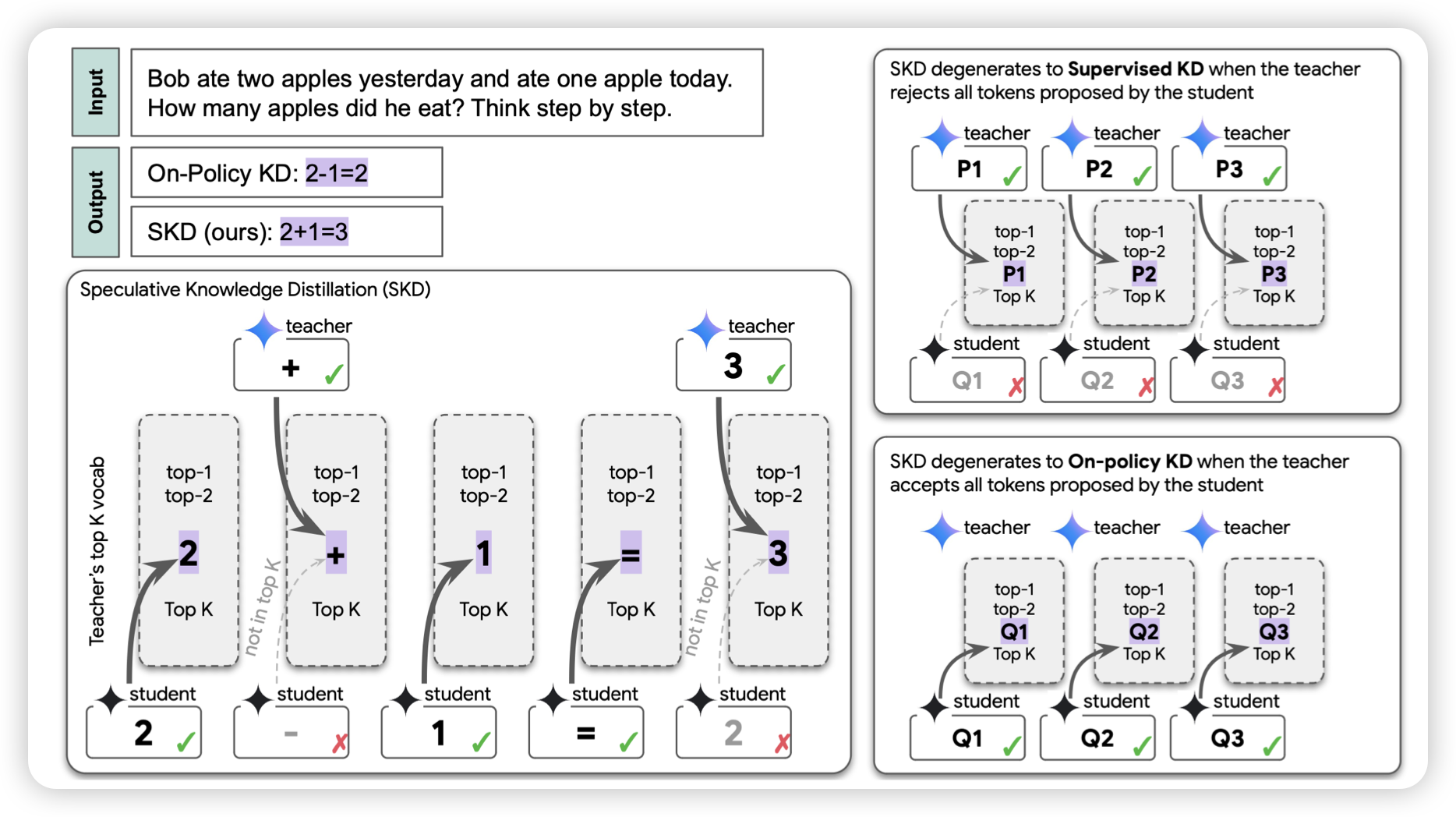
Latent Action Pretraining from Videos
很新颖的方法:作者想要训练具身机器人模型,但是缺少训练数据。作者发现,世界上有超级多的具身的视频数据,但这些数据都没有标注action,能不能训练一个vq-vae模型把视频映射到codebook,然后后续把这些codebook对齐到不同的action上呢?作者发现还真可以!效果竟然很好?
这个工作里面可能还蕴含着很多秘密……
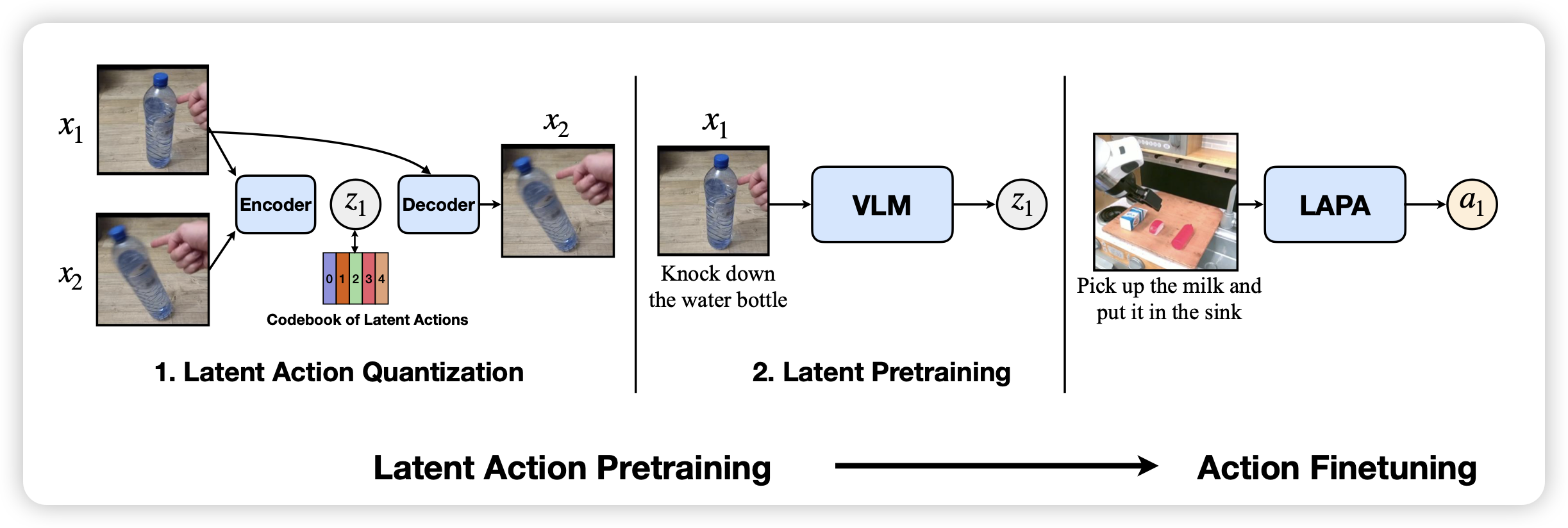
VidEgoThink: Assessing Egocentric Video Understanding Capabilities for Embodied AI
之前读过一篇小众的论文”GUIWorld“,这篇工作是把它换到了第一人称视频的场景下。作者找到了一堆第一人称视角完成任务的数据,搭建了一个benchmark,涵盖了从qa、planning到grounding的各种任务。
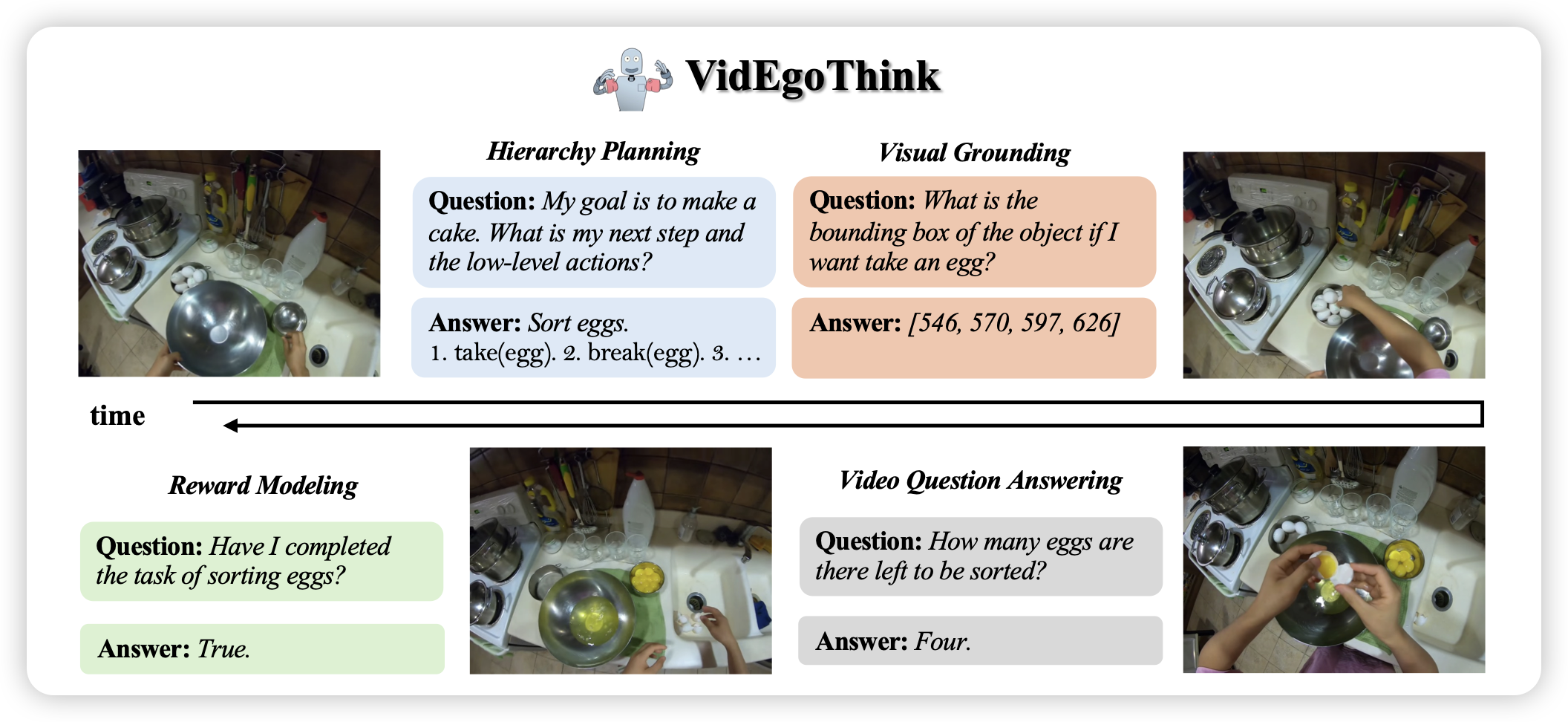
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling
一篇关于蒸馏的工作,但作者提到另一个视角:蒸馏中学生和老师之间的knowledge gap带来的影响。作者认为如果让学生强行学习老师的分布,会带来严重的knowledge mismatch。所以,能不能让老师改学生的输出,只把关键地方改对呢?作者设计了类似投机推理的框架,老师看过去,觉得大差不差得token就不管,差很多的token再来借入。最后发现效果很好
这是不仅仅学下棋,还要求老师把学生的烂局救活呀。感觉最近学界有个趋势:尽量不要改变模型本身的知识范围