Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
很有洞见性的工作!作者发现,目前的o1类模型一般都要套个best-of-N的壳,但是我们训练的时候模型其实不知道外面有这个inferencetime-scaling的壳。如果我们在训练的时候就让模型适应有个壳呢?比如让模型学着说的diverse一点,因为他知道一会要投票。作者发现这样训完,模型的inference-time-scaling能力被进一步激发了
有意思!

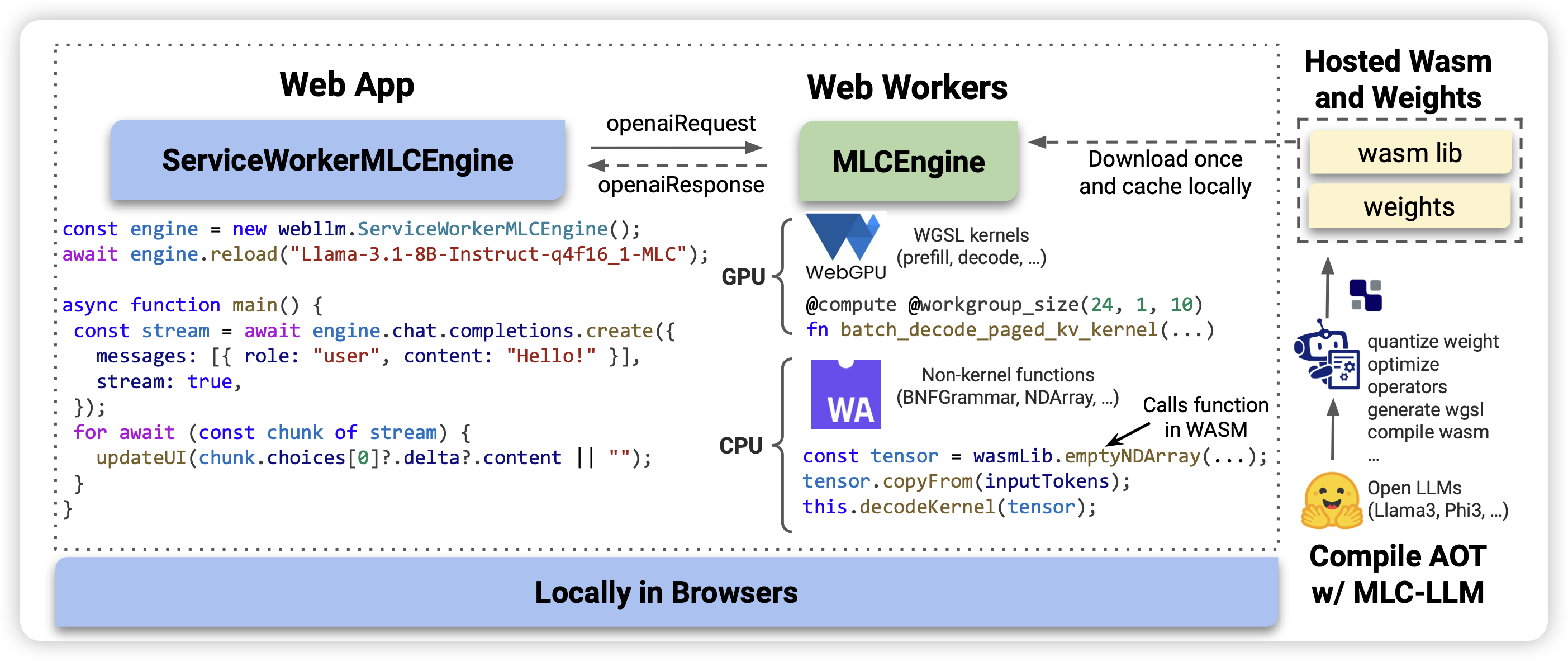
WebLLM: A High-Performance In-Browser LLM Inference Engine
乍一看,以为是GUI Agent操作网页,仔细一看:是在网页里面跑llm infer。不愧是tianqi