圣诞节arxiv竟然没休息?
Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search
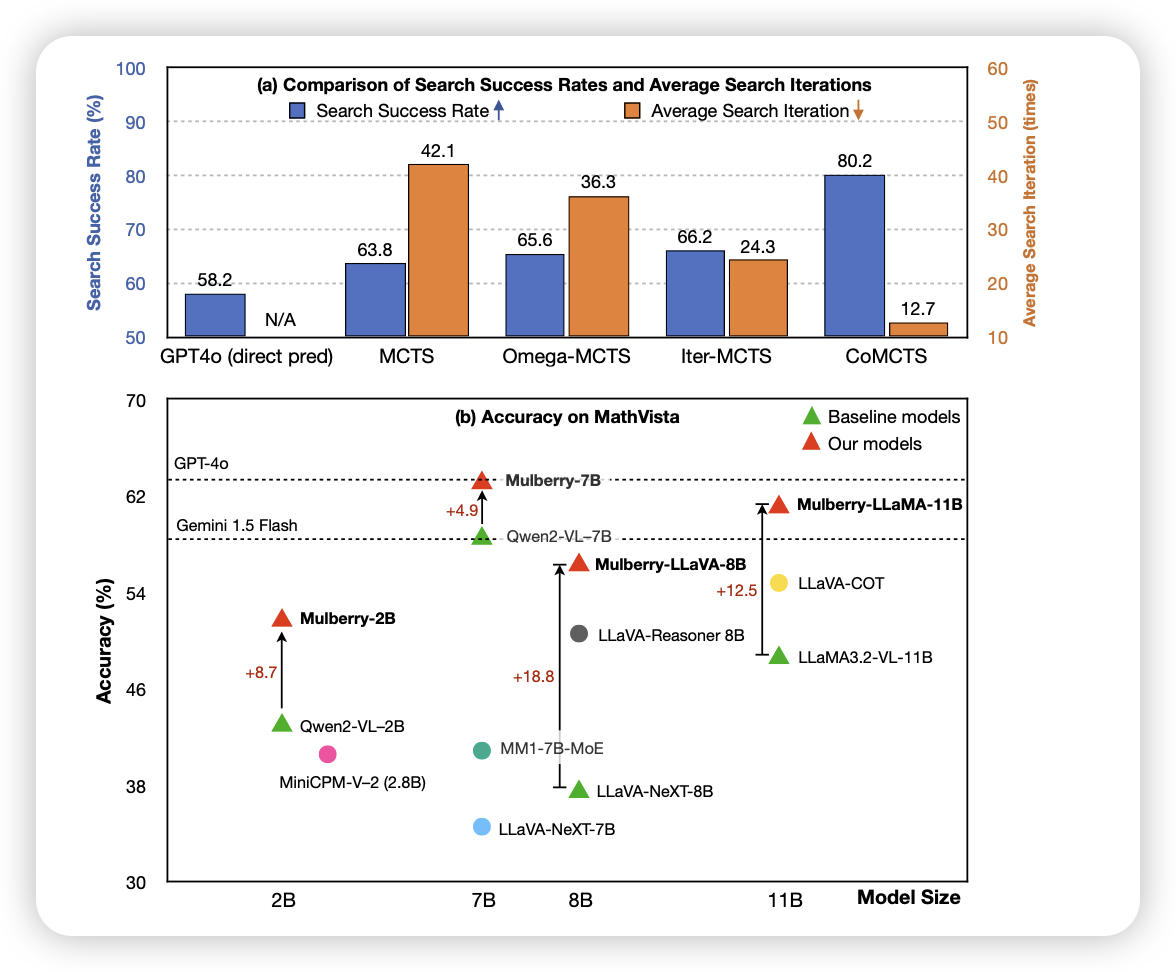
os-like VLM的工作,主要思想是把MCTS搜出来的好结果蒸馏回去。作者一个新的发现在于:可以在MCTS的过程中用不同的模型一起来模拟,这样出来的数据更客观。由此构造出的260k sft训完了,比基模在很多任务上都要好不少
Token-Budget-Aware LLM Reasoning
这篇工作讨论的问题很有意思:目前的Long CoT模型的输出其实都很冗余,能不能让模型知道自己的cot budget是多少token,然后在此基础上去做推理呢?
前天kumar有个工作在讲,让模型训练时得知测试时的算法。这两篇是不是可以结合一下,让模型知道推理多少token就会被嘎掉,通过rl让模型学着去看自己的budget
