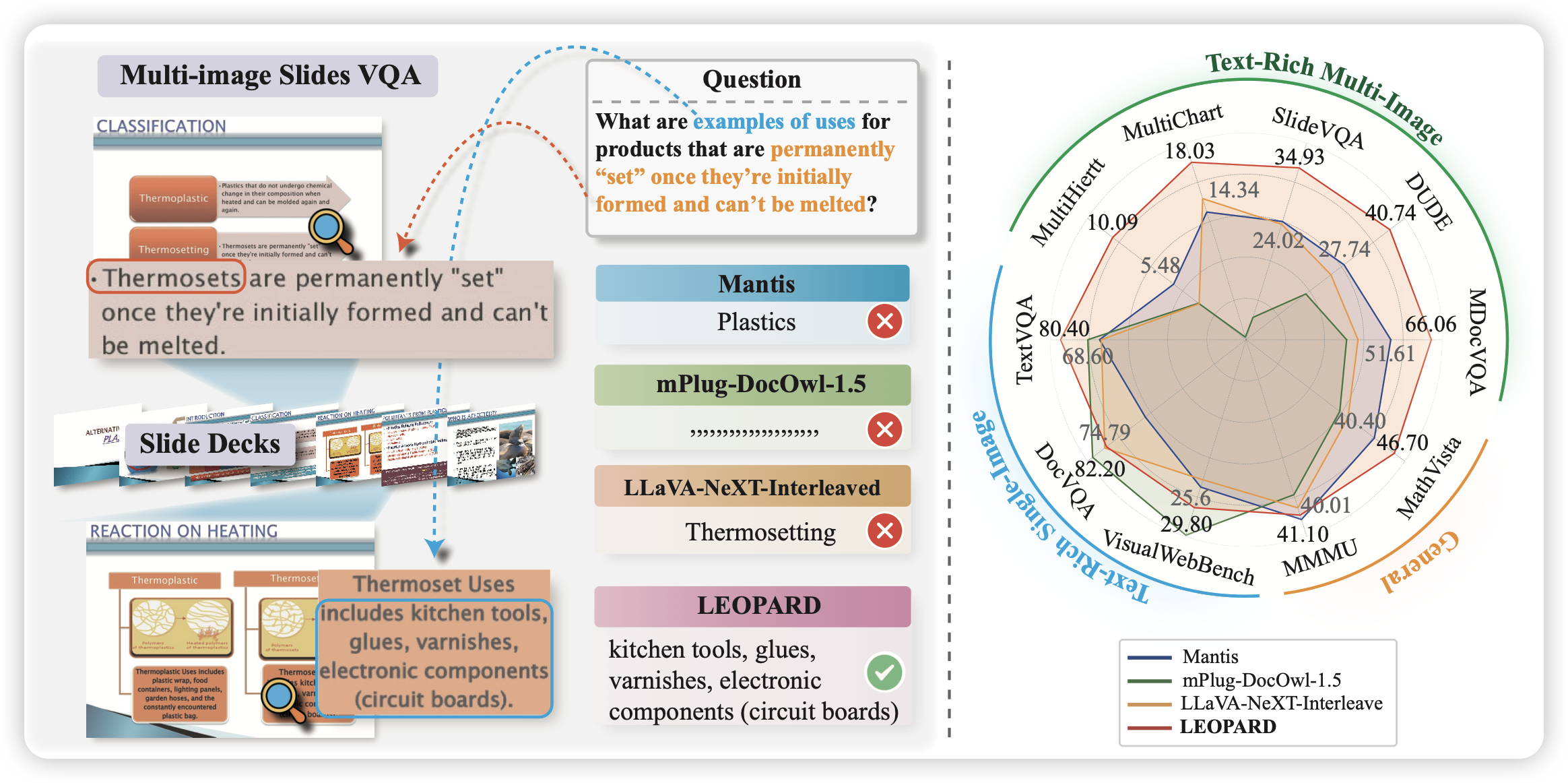
LEOPARD : A Vision Language Model for Text-Rich Multi-Image Tasks
一个专门瞄准text-rich场景的VLM,作者构建了1M的高质量SFT数据,然后设计了一套自动根据图片质量申请visual token数量的pipeline,取得了不错的效果
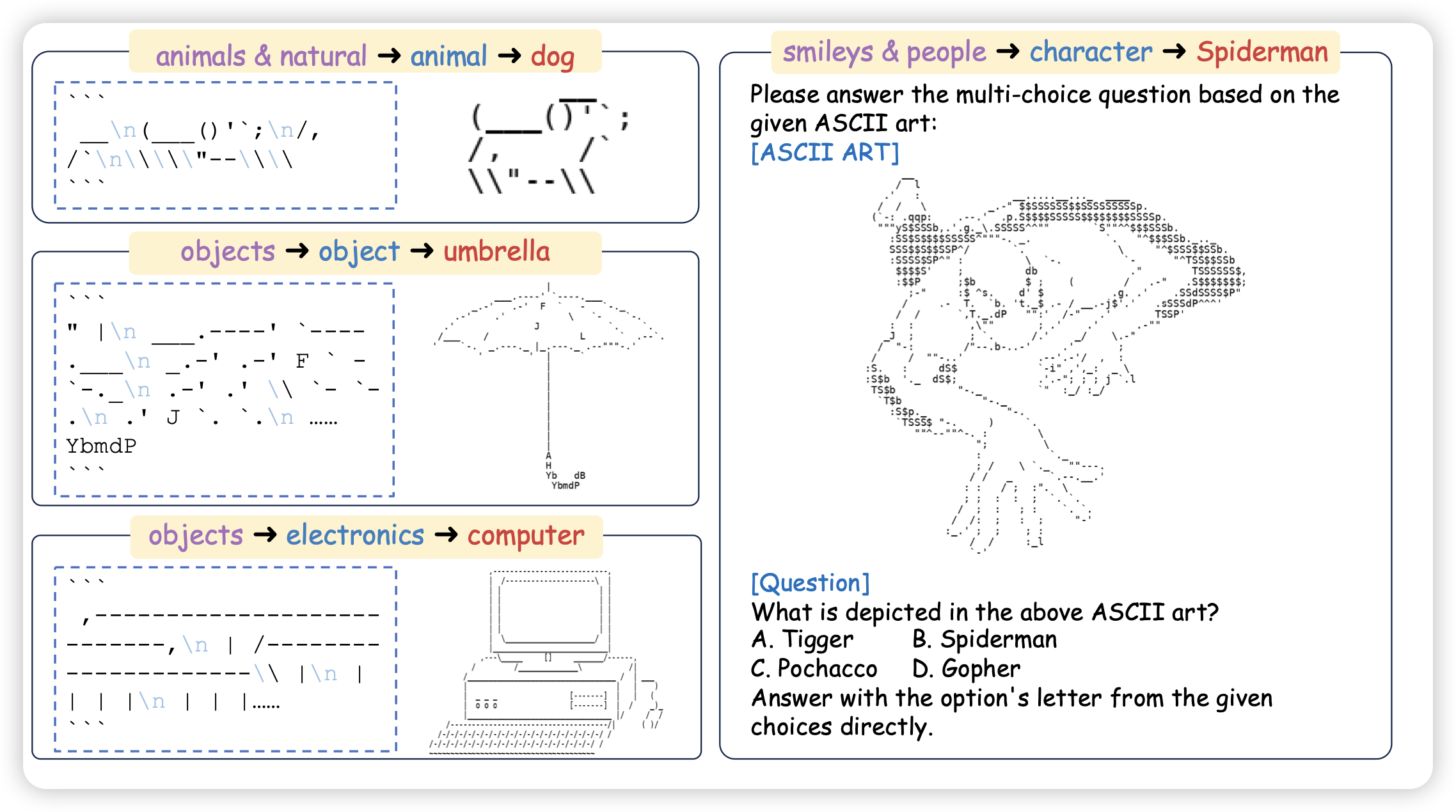
Visual Perception in Text Strings
阴间大队的又一力作,作者发现,ascii字符渲染出来的图片天然有文字、图片两种表示,而且其转换是无损的。所以,VLM在这种ascii art场景表现如何呢?作者发现:
- 4o表现傲视群雄
- 在同时给出两种模态输入以后,没有模型能有提升,大家还是只会使用图片模态。经过SFT,提升也不明显
我感觉作者这个故事这么讲有点小,可以讲一个“探索MLLM对于模态fusion的能力,由此需要去找一个各模态无损压缩的场景……”
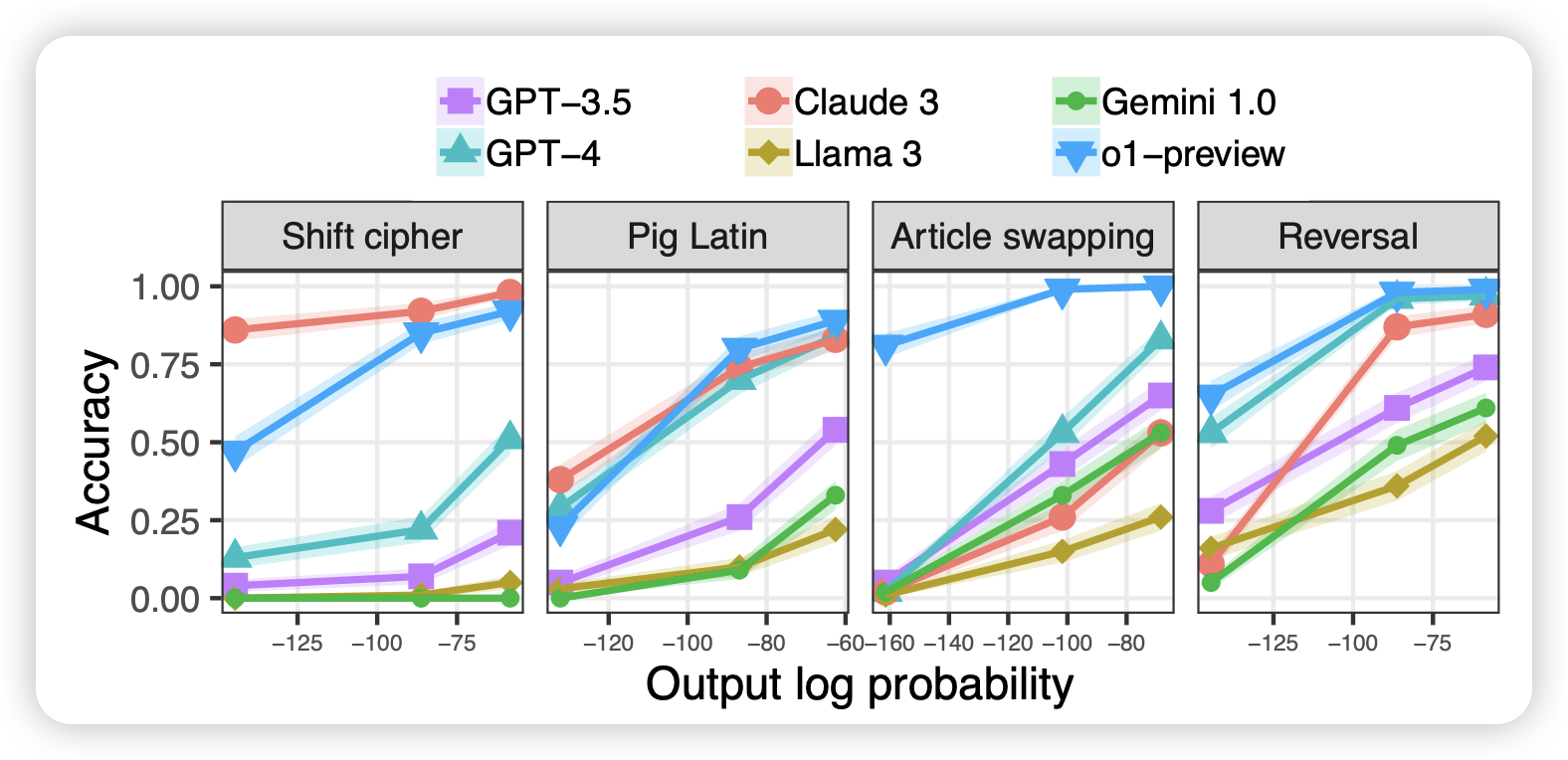
When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1
shunyu yao参与的工作,这篇工作其实有个前文叫"Embers of Autoregression",大致探索了LLM在各种任务上是不是在罕见词场景下做的更差,然后发现所有模型都在罕见词场景下都非常的差。作者这次试了试o1,看看会不会缓解这个问题:
- 发现o1已经好了很多,不过仍然受到了这个影响。换句话说,通过inference scaling,可能仍然难以解决预训练分布带来的bias
- o1表现出来一些有趣的性质,在常见词上thinking token很少,罕见词问题thinking token会更多。也许thinking token的数量变化,能发现模型大致衡量到了问题的难度