VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
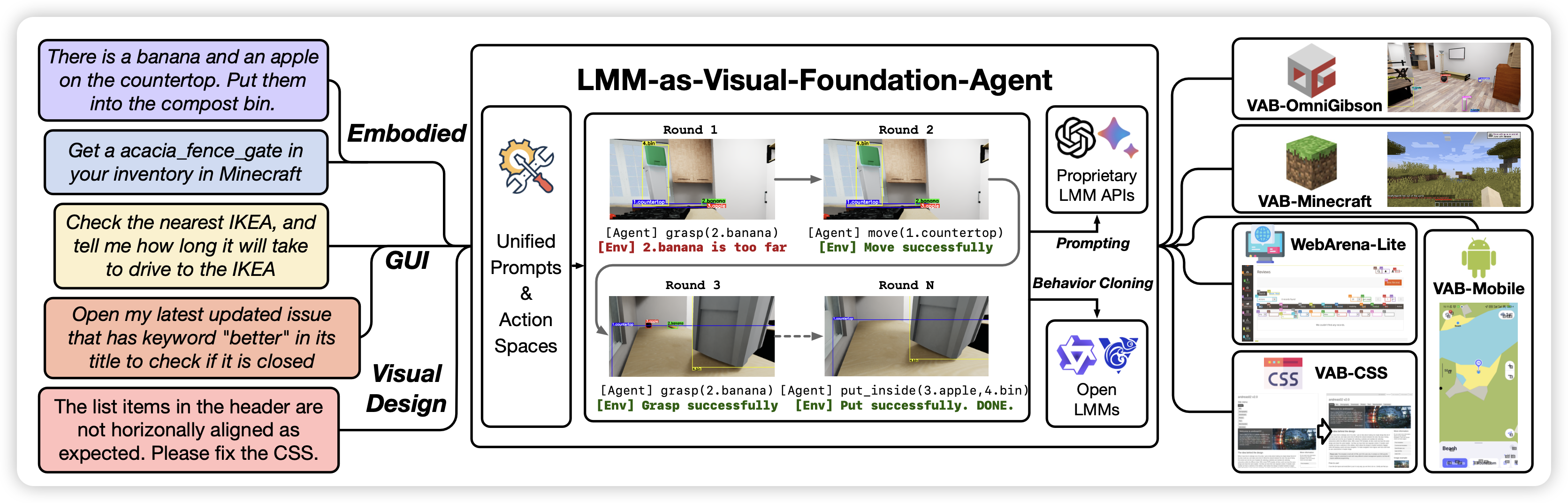
Xiao liu的新工作,暨去年的AgentBench之后,今年搞了个visual版本,首页的雷达图都是同一套模板。
Long-Form Answers to Visual Questions from Blind and Low Vision People
作者探索了输出很长的VQA场景的数据。作者发现,对于盲人或者弱视群体,需要VLM给出详细的答案,作者发现这样构造出来的数据常常会有hallicinate,并探索了一些增强的办法
