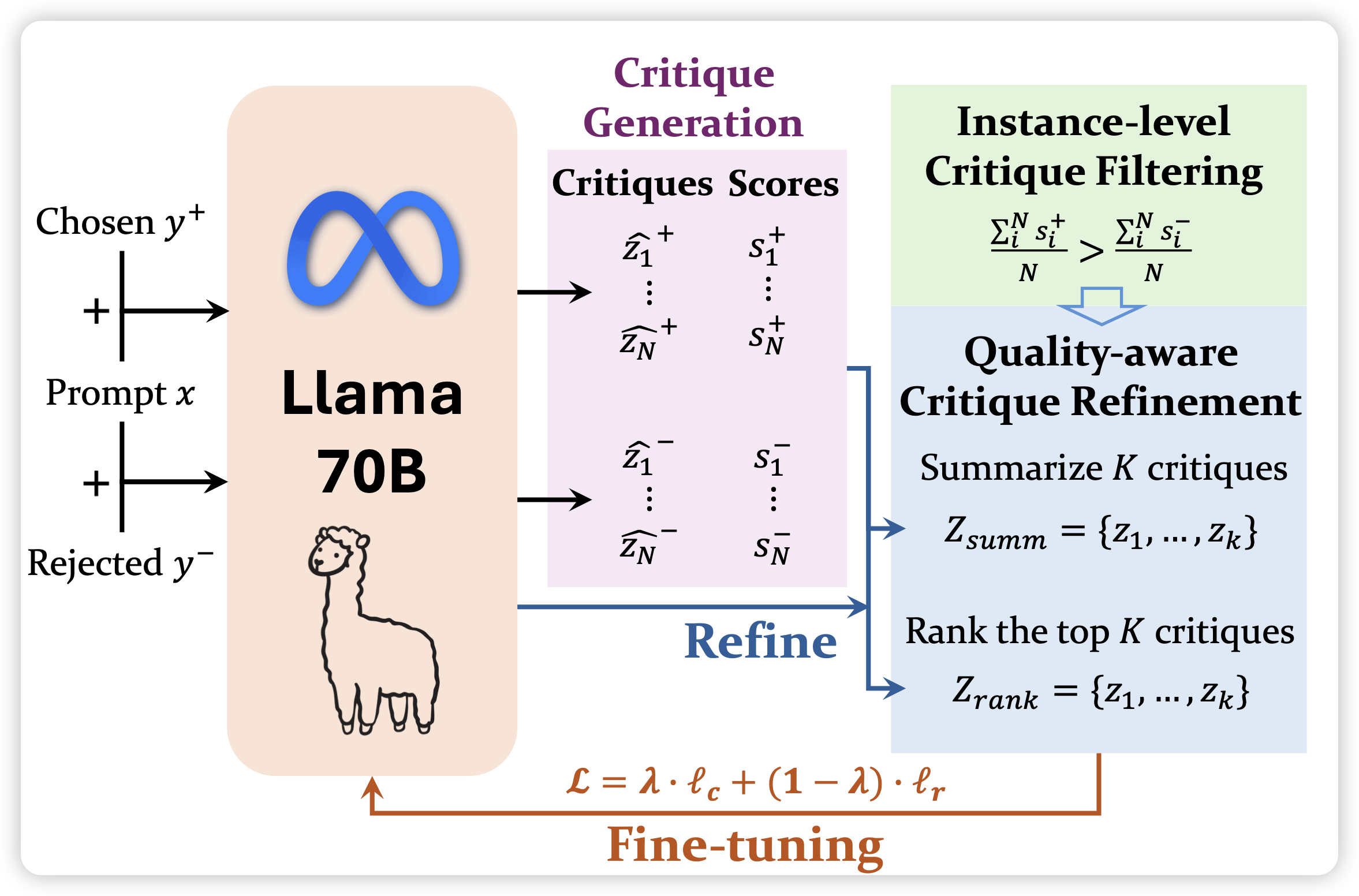
Cautious Optimizers: Improving Training with One Line of Code
好久没看到optimizer的工作了。作者发现改一行代码就能把性能提升不少。
不明觉厉
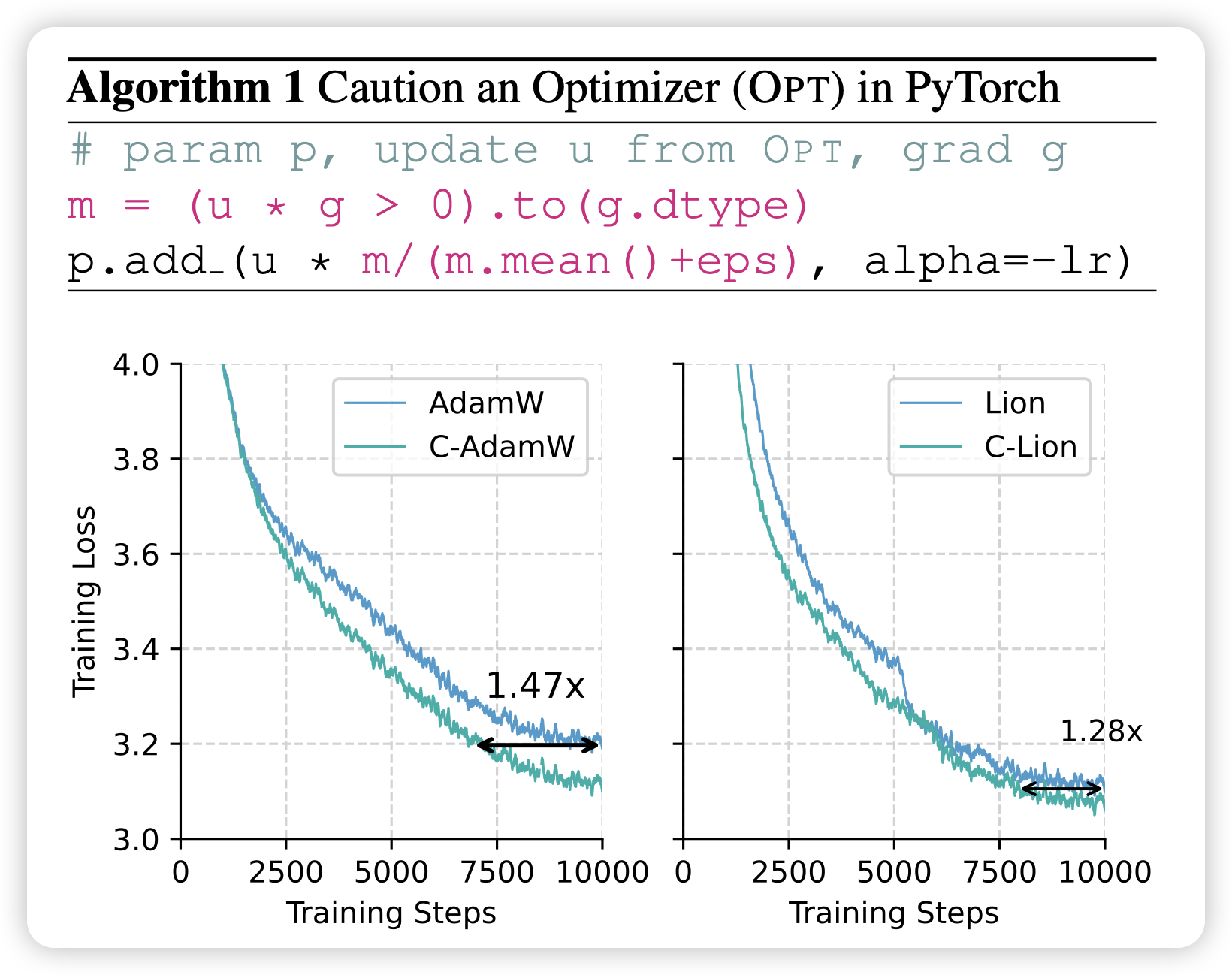
O1 Replication Journey – Part 2: Surpassing O1-preview through Simple Distillation Big Progress or Bitter Lesson?
前两天阿里国际的macro-o1是搞蒸馏,今天pengfei老师的o1 jurney出了二期,也是搞蒸馏。发现纯靠蒸馏o1 API的数据,就能把math code这些打到一个很不错的水平
另外,给open o1打个广告:macro o1和o1 journey都用了open o1的数据,另外从kimi和deepseek的思考数据形式来看,他们应该也都用了……
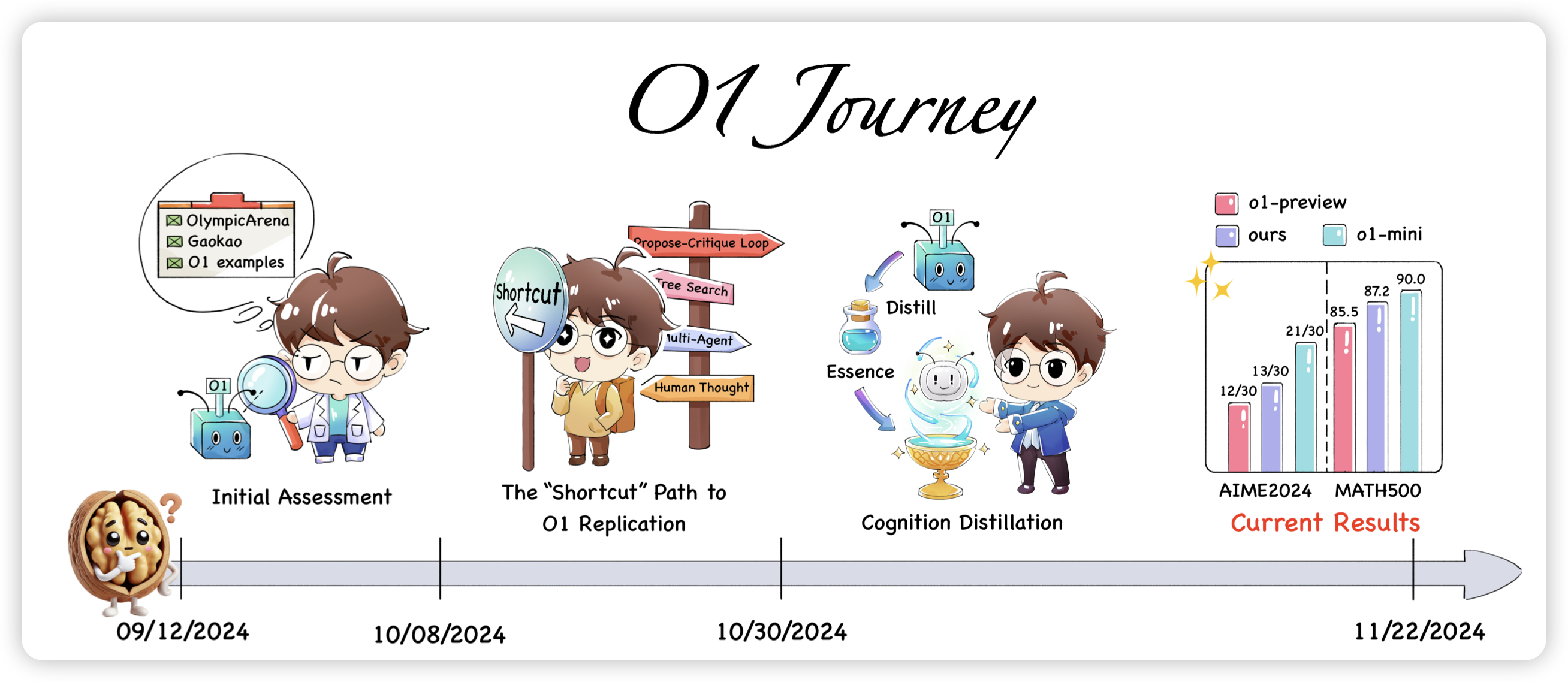
Self-Generated Critiques Boost Reward Modeling for Language Models
开头一篇浅蓝的abs,就知道是好东西,仔细一看果然是好东西。之前Aviral Kumar搞了个Generative-RM,好像比较小众不太火,这次Meta搞了个Critic RM。思路都是一样的:如果让RM模型先自己用CoT的方式说一大堆话,最后再给出一个scalar reward,会不会效果更好呢?既然o1能work,这个自然也能work。做出来果然work了
下次给所有领域都套个o1的壳:generative RAG, generative CLIP, generative ToT...