这篇文章发表于2020年的EMNLP demo,作者团队还是义原计算小组。

既然是是demo,那它一定是有一些借鉴的方法。其方法主要是这一篇提到的:
Multi-Channel Reverse Dictionary Model (AAAI 2020)
他们解决的都是所谓的“反向词典”任务。
反向词典任务
反向词典任务就是和词典的工作相反:输入一个描述,返回对应的意思,如下图所示:
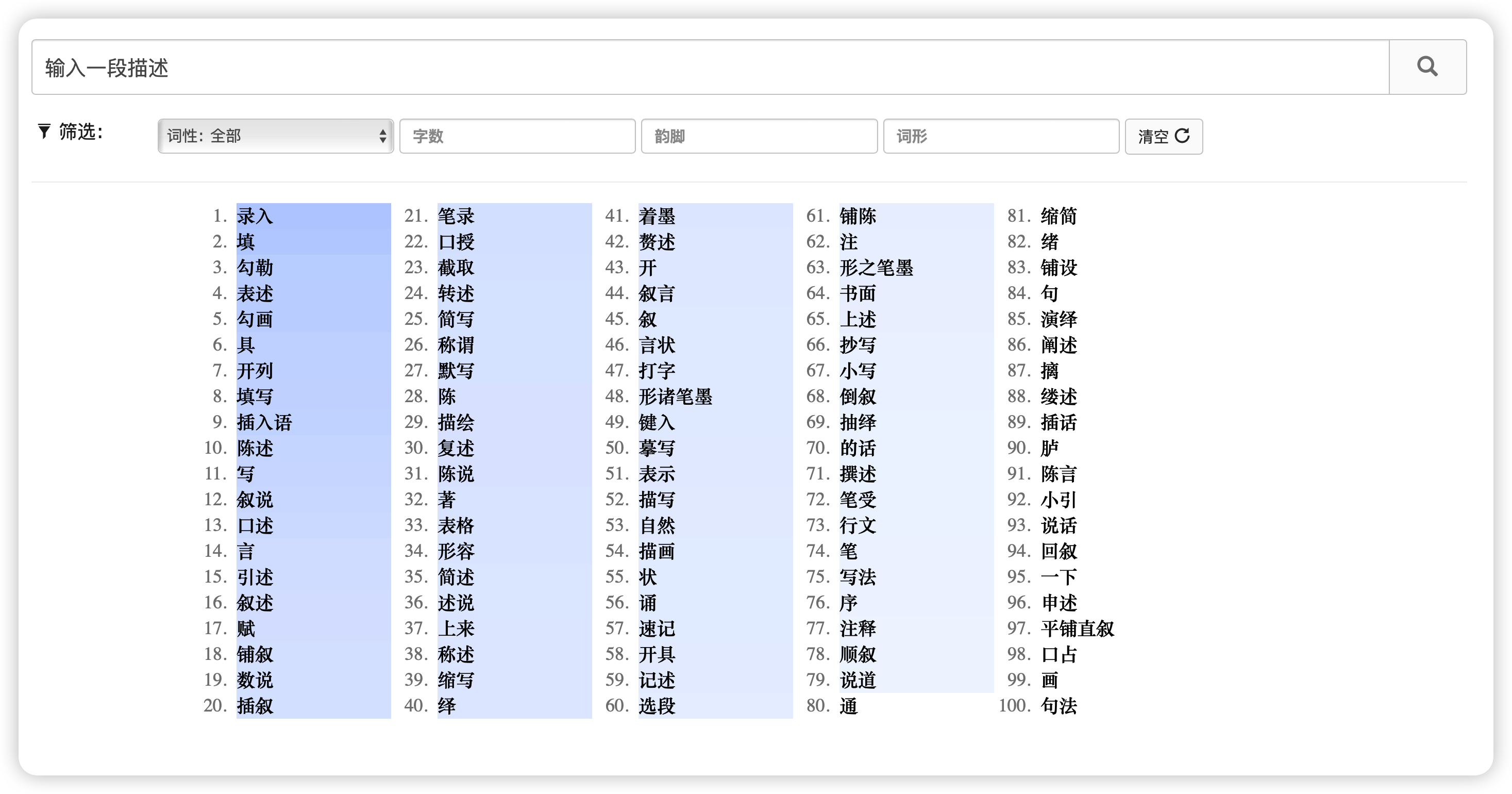
这个任务其实非常有实际意义:
- 解决所谓tip-of-the-tongue的问题,当你想要表达一个意思,突然想不起来这是什么词(尤其是成语)
- 帮助语言初学者联想到自己不知道的词语,这个时候往往用户还需要对应的词语释义
- 有些word selection anomia病人,只能通过这个方法来组织词汇
事实上,反向词典任务经过拓展还能实现更多功能:
- 比如通过在词库添加名人名言、唐诗宋词,可以帮你在作文中进行名言推荐
添加党史、领导人语录,帮你在思想汇报、新闻稿中提高深度
已有的商用反向词典比如
OneLook,ReverseDictionary都不是开源的,并且效果也一般。本文提出的方法效果很好,同时支持中英之间跨语言的搜索
Multi-Channel Reverse Dictionary Model
已有的方法词典方法一般是两种路径:
- 第一种是把查询query和词库里词语的词的释义进行比对,选最接近的。缺点是用户的query常常和释义的形式很不一样,极有可能出现偏差
- 第二种是把query编码到隐空间,和词库里的词向量进行比对,选择接近的。缺点是很多罕见词的词向量其实很不准确,但真实的用户query常常就是想要”罕见词“。
这篇方法主要走第二个路径,但通过加入一下专家知识帮助减少误判。下面简单讲讲方法
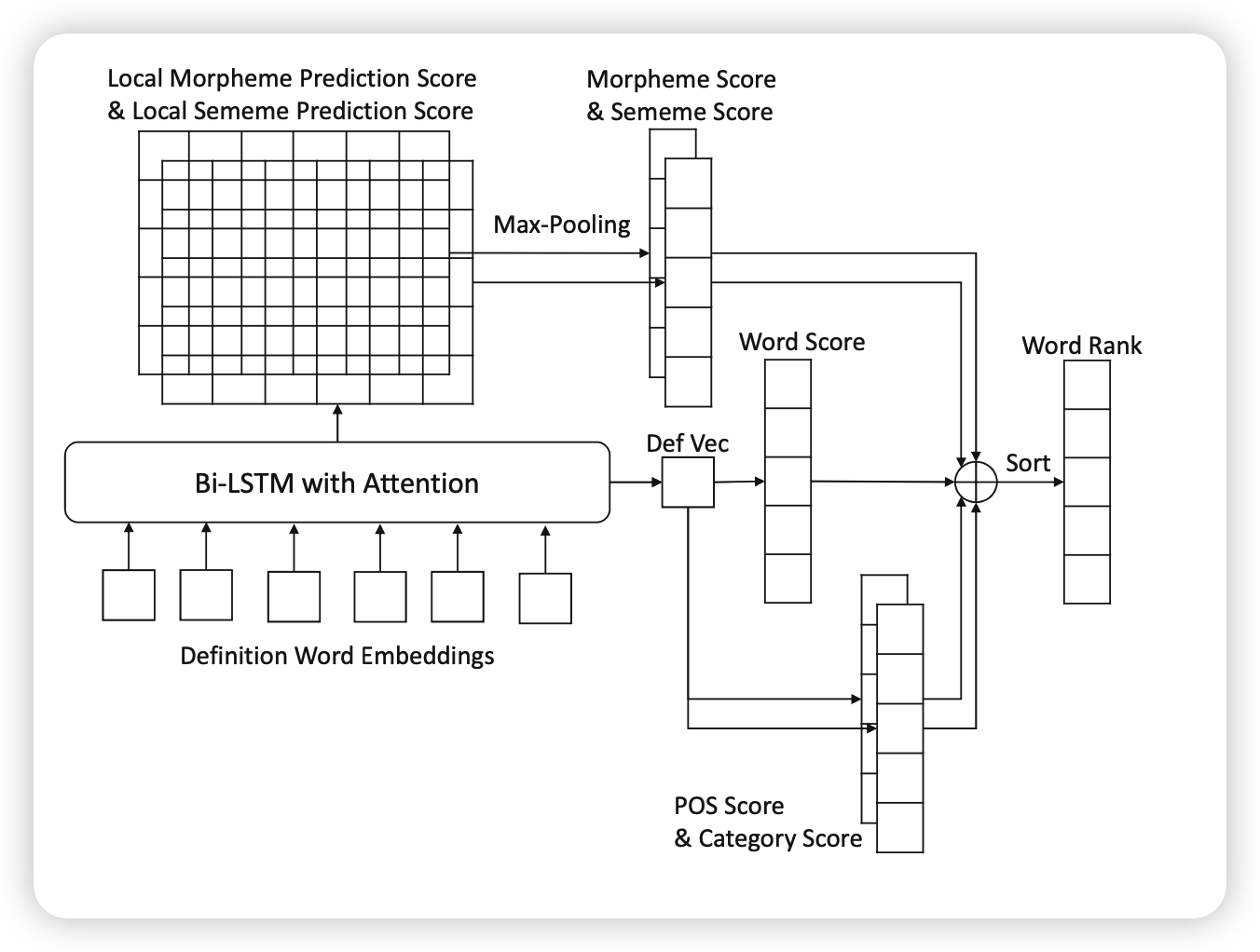
首先是用一个Bi-LSTM把输入编码到hidden state。接下来有四个channel辅助判断,以减少罕见词的误差:
- POS预测器: 用分类器把hidden state给每一种词性一个分类得分。同时词库里的词对应一些POS。词语的得分额外加上”对应POS的得分“
- category预测器:和上面很接近,相当于把词库里的词分成好多组,然后一样给得分。
- morpheme预测器:morpheme也有点类似,每个词都有对应的morpheme。给hidden state每个token都进行morpheme分类算得分,然后词库里的词也有morpheme,把对应得分加上
- sememe预测器:和morpheme完全一致
上面四个channel的得分以及本身词向量和hidden state(线性到一个token)相似度的得分wordScore,加一个权重,最后来一个总的得分。这个方法效果很好,尤其对于罕见词。
WantWords
本文的demo主要也是用Multi-Channel Reverse Dictionary Model(MRDM)的方法,但做了一些改进
把Bi-LSTM换成了BERT
同时处理了一些边界条件:
- 同语言查询输入一个词:把query词的词向量直接算cosine similarity
- 跨语言查询:通过百度翻译API翻译到目标语言,然后查询
- 跨语言时输入一个词:把词对应的释义通过百度翻译API翻译到目标语言,然后查询
同时WantWords也给出了查询词对应的释义,帮助语言学习者掌握联想到的词语
我的思考
- 不知道用大模型+prompt做这个的效果怎么样
- 感觉现有的词典软件都可以添加这个功能