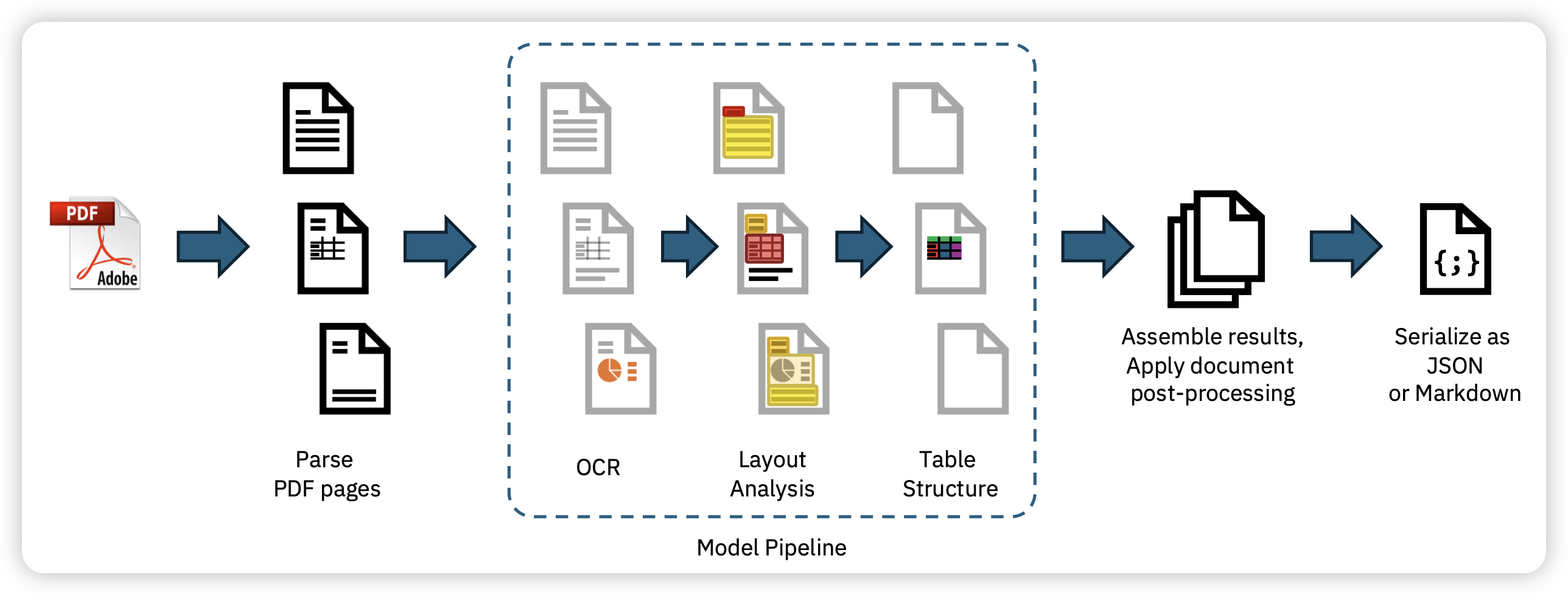
Docling Technical Report
这不是一个大模型,而是一个demo paper。作者集合了多个相关的模型,只关注pdf parsing这一件事情,希望把任意的pdf变成markdown、json这种有结构的文档。这其实是一个挺复杂的过程,因为pdf里很多段落的语义关系、表格里面不同行还有行列的合并,各种脚注、章节标题。不过IBM这套pipeline做的不错
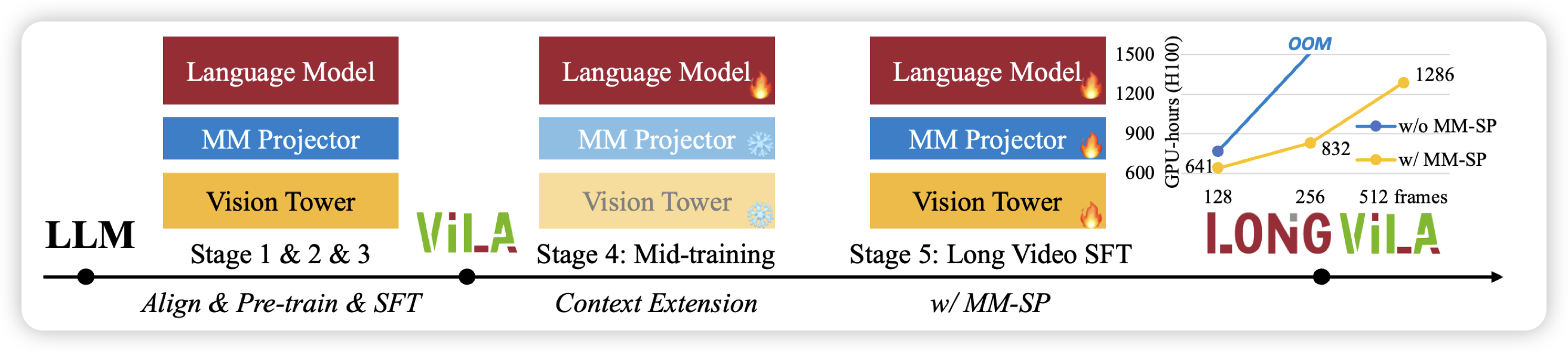
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
2M context的videoLM,由于用了long context的方法,可以原生的用高帧率表示video,而且真的训起来了。在video benchmark上表现很好
开源