今天出了一堆论文,但大家都在讨论sora……发布应该避开最近两周
Language-Guided Image Tokenization for Generation
这个工作很有意思,作者提到已有的vqvae 图片tokenizer,都是输入图片吐出token sequence,都会损失信息。如果让tokenizer这一层可以用上image caption这种额外的图片信号呢?作者发现这么搞,出来的tokenizer效果比纯的image tokenizer好很多。问题在于,测试时也需要image caption存在。
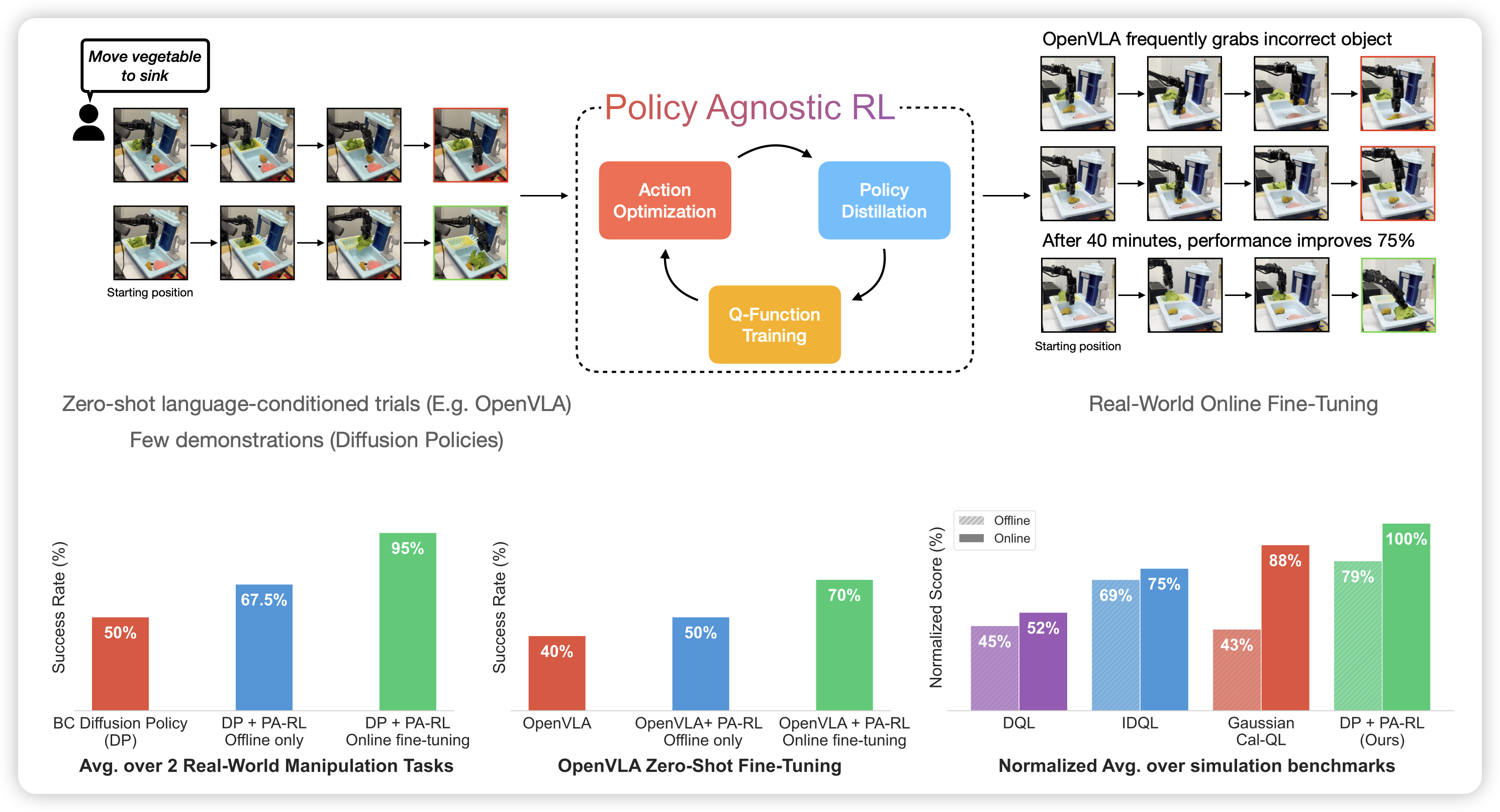
Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
kumar又出新作品了,虽然我看不太懂。作者提到现在的各路rl算法都是和模型结构深度绑定的,比如diffusion-policy、gaussian-policy、autoregressive-policy,想用一个算法跑起来几乎不可能。这里面的核心问题在于rl中的policy improvement这个step对于不同policy有不同的定义和问题。既然这样,如果把这个过程统一成SFT范式可以吗?虽然和rl的原始定义不太一致,但是训练却很稳定,真给他训出来了。
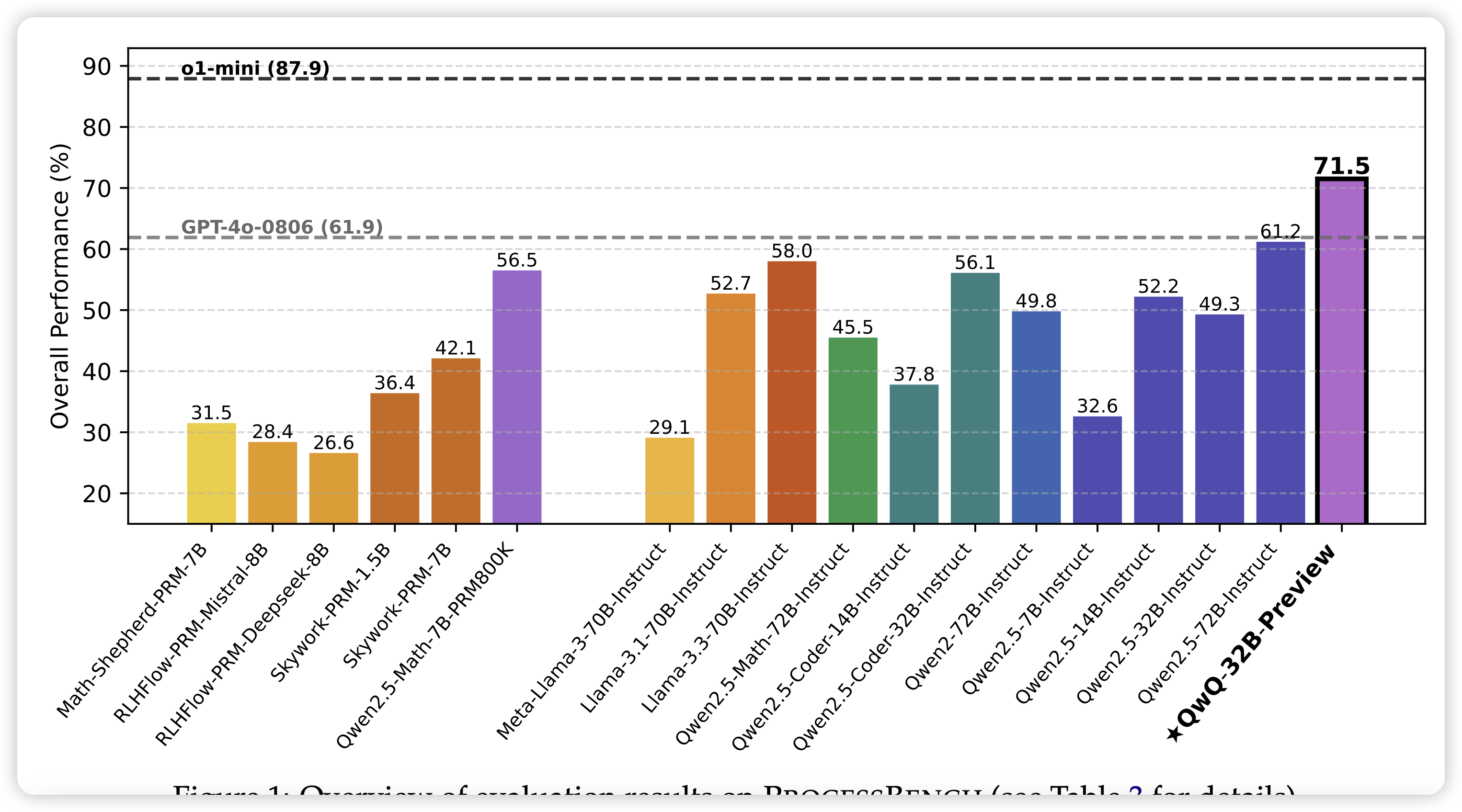
PROCESSBENCH: Identifying Process Errors in Mathematical Reasoning
Qwen团队的作品,一个衡量各家prm的benchmark。作者在3400道竞赛级别数学题上,用不同模型标注了trace,然后找人给出了 process reward,由此构造了一个prm测试集。作者发现,仅仅在gsm8k MATH这种简单题的prm标注上训出来的prm,其实泛化不到竞赛题上。然后基模换成qwq这种o1-based model,能好不少,不过比起真o1还是差远了。