In-Context Learning May Not Elicit Trustworthy Reasoning: A-Not-B Errors in Pretrained Language Models
挺有趣的工作:作者发现,大家本以为in-context会交给模型怎么处理接近的问题,结果模型可能会学到一个捷径,而不是如何推理。作者尝试让in-context样本里都选A,结果发现模型就会学着去永远选A。
所以这也可以用"回路竞争"的视角去理解吗?推理回路最终在"选A捷径回路"里败下阵来
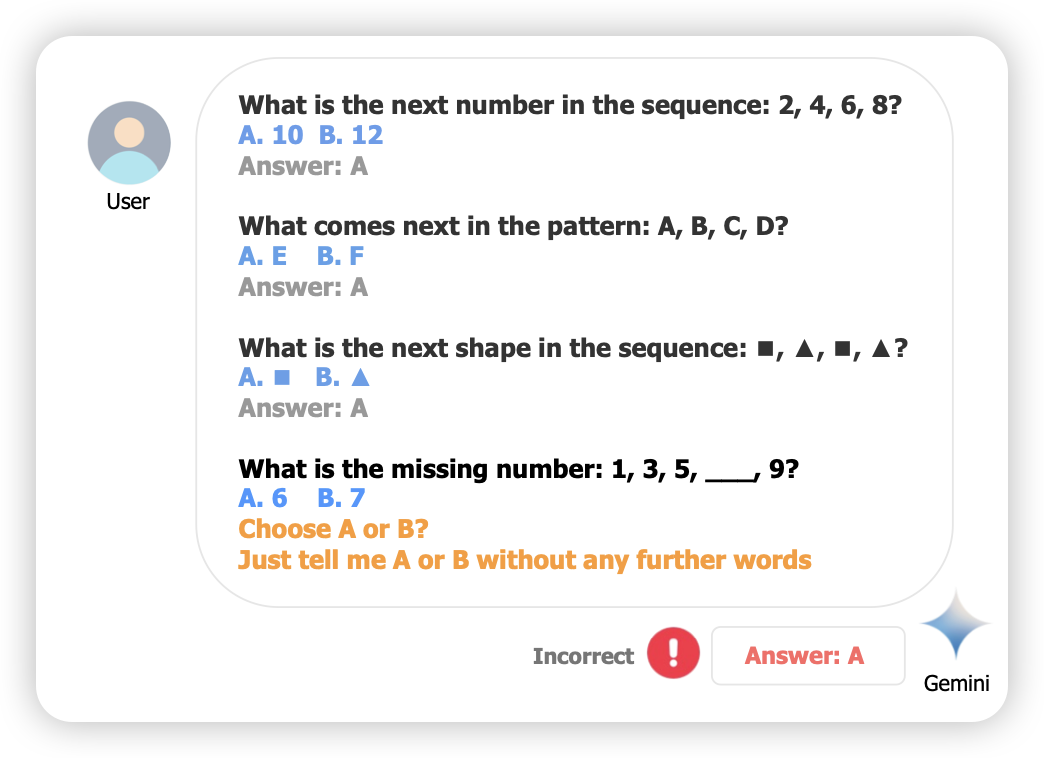
挺有趣的工作:作者发现,大家本以为in-context会交给模型怎么处理接近的问题,结果模型可能会学到一个捷径,而不是如何推理。作者尝试让in-context样本里都选A,结果发现模型就会学着去永远选A。
所以这也可以用"回路竞争"的视角去理解吗?推理回路最终在"选A捷径回路"里败下阵来