Multimodal Latent Language Modeling with Next-Token Diffusion
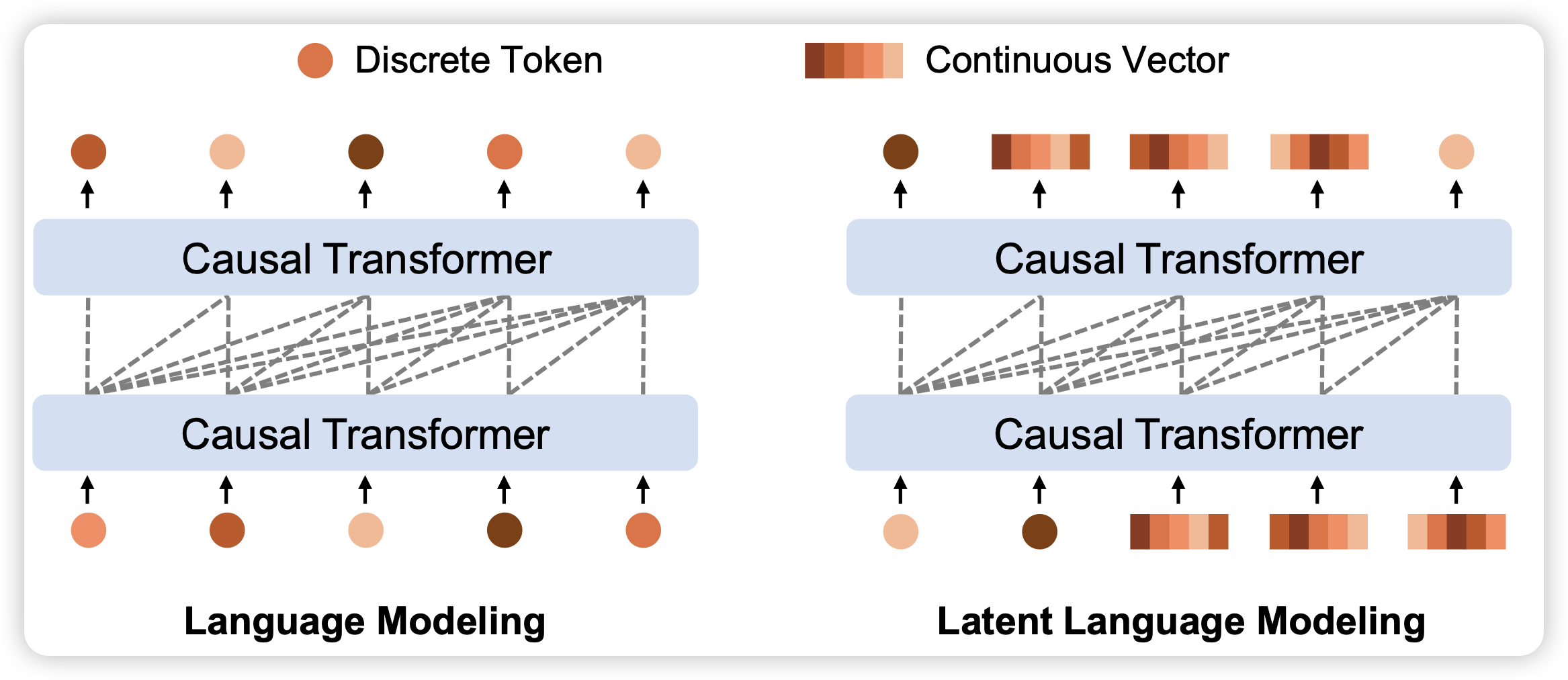
推荐一手朋友的工作,这篇工作的研究的是让模型直接把上一轮的hiddenstate拼回去,而不是查找到最接近的词向量,这是因为图片声音等模态的内容,不能像文本一样有天生的离散性质。能不能做呢?之前大家用词向量,是因为由此就可以转化成crossentropy loss让训练非常稳定,现在如果直接把词向量这个设计去掉、变成出口层的diffusion head,会带来训练的不稳定。但是作者发现,稍微对vae模块做一些改动,就可以使得vae地输出有一些往vqvae靠拢的性质。
StreamChat: Chatting with Streaming Video
一篇很有趣的工作,关于streaming video chat场景。这个场景已经不稀奇了,一堆人在研究。这篇牛的地方在于,他考虑一个情况:在模型说话的时候,视频也是在变化的,能不能让模型一边回答,同时一边持续关注视频,可能说一半再改口这样呢?
