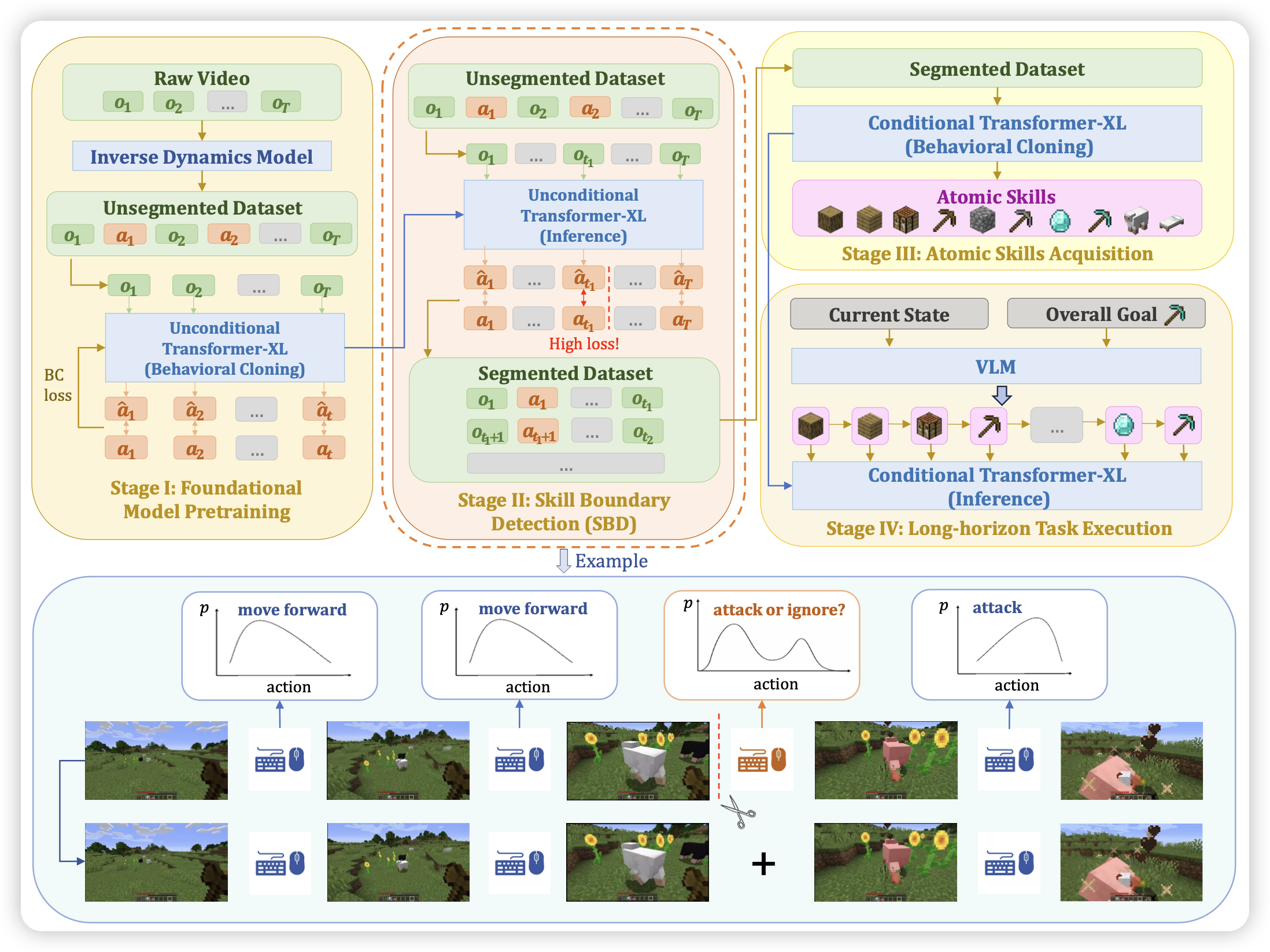
Open-World Skill Discovery from Unsegmented Demonstrations
推一手哥们的工作,作者研究的问题是如何把agent trace进行切分,进而推算出一些high-level的query。作者的招数是,model-oriented:直接训一个policy,找到loss最大的地方,认为这里就是关键位置,并做切分。
之前其实有不少工作在研究这个方向,比如GUIWorld他们都是用4o直接prompt切分,感觉效果都不太好。
不过这种model-oriented的方案,可能有另一个问题?模型预测不出来的action,可能不是困难的地方,而是随机性更强的地方。我之前看过Yejin Choi一个工作,他会用一强一弱两个模型分别预测,然后认为随机性强的地方,loss应该不会随着规模的变化而变化;只有困难数据,应该是强模型loss更小