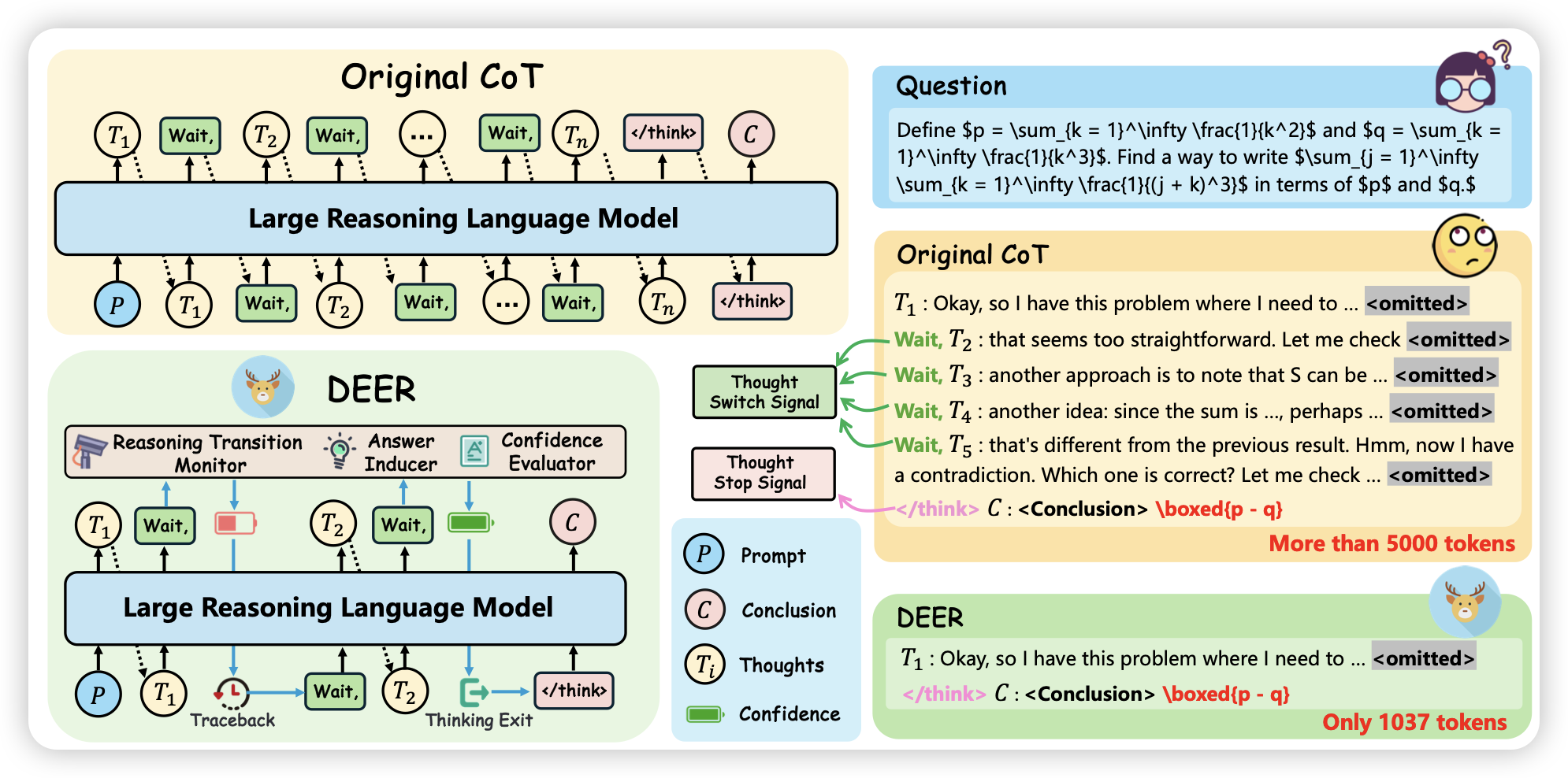
Dynamic Early Exit in Reasoning Models
如果大家看了前几天那个meta reinforcement finetuning,就会记得里面的omit技巧(让o1说一半thought,就强行拼接/thought然后去说答案),比起优化omit状态下的回答准确率,这篇工作探索了能不能用confidence直接去对thought最early stopping。
话说我一直挺喜欢omit这个东西的,我的想法是这样:如果我们把o1理解成某种模型自己学到的搜索算法。作为搜索算法,anytime的性质一直是最优的性质,模型能不能学着去优化anytime的算法呢?毕竟这样才可以世纪地去部署
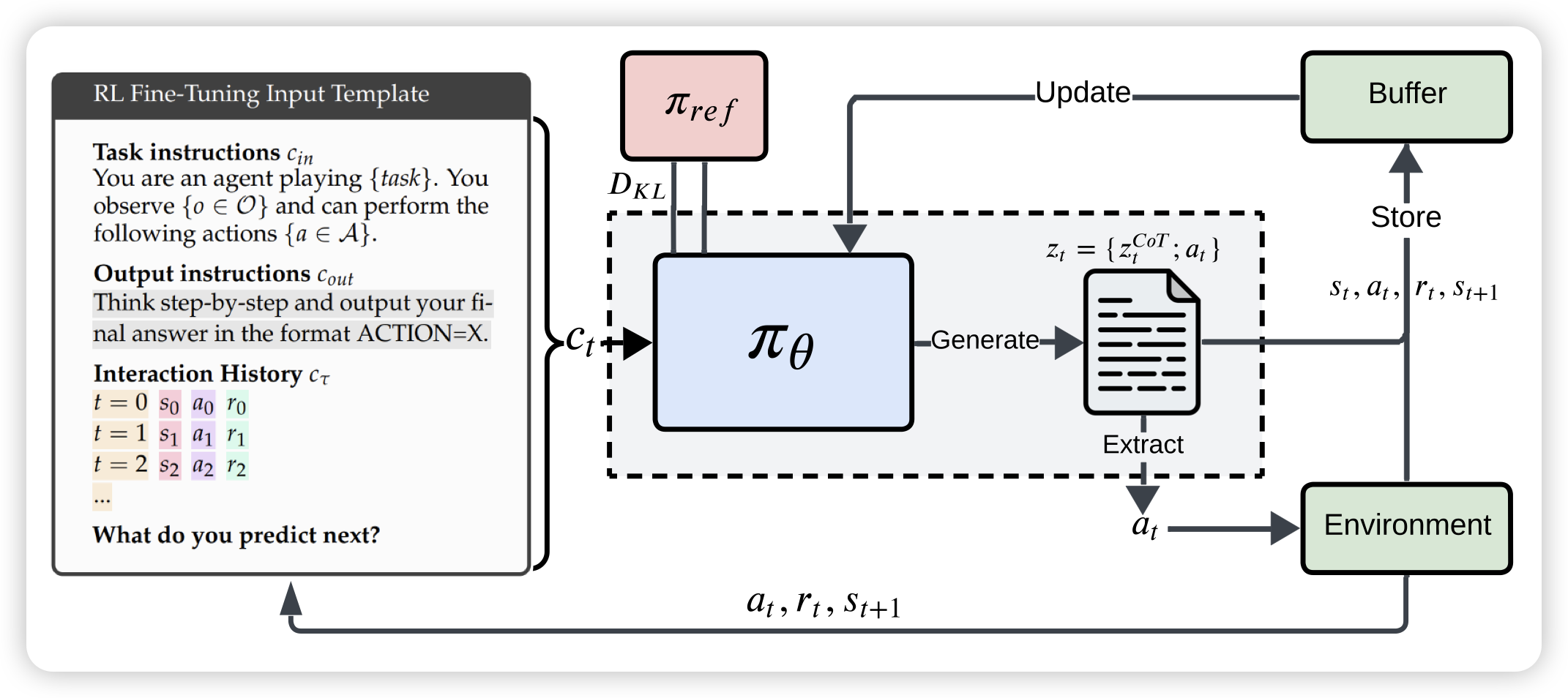
LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
这篇工作很有趣:作者研究了llm做decision making的能力,发现总是效果不好。经过近一步分析,发现了三个瓶颈:greediness(大多数action从来不探索), frequency bias(只选择次数最多的,可能是因为context里最多), knowing-doing gap(用qa的形式发现它知道最佳策略,但就是不能根据策略去做)。由此作者设计了一套rl算法,看起来可以解决这些问题
knowing-doing gap这个见解很深刻,不愧deepmind