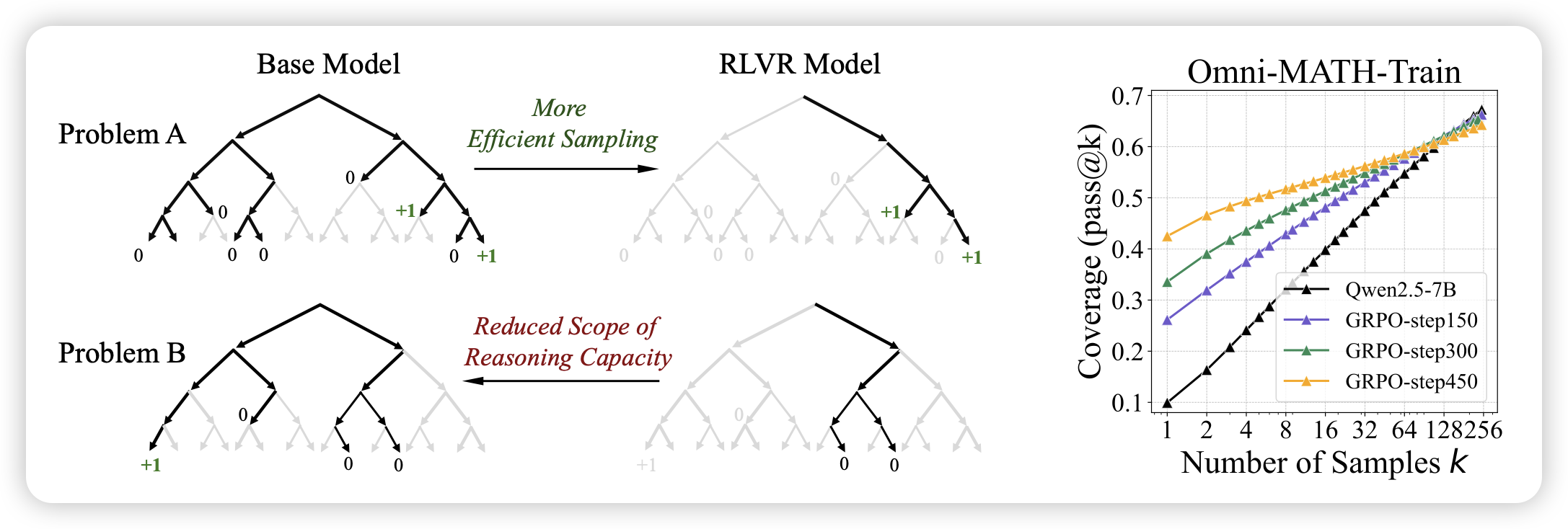
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
这篇工作里,作者研究了o1训练前和后的模型,但关注的是pass@k指标。得出一个结论:虽然模型的bo1效果上升显著,但是bon其实没涨。这其实是这类训练方法的固有问题,因为没有引入外部的知识反馈,只有结果反馈
所以,在o1训练前需要一个hotstart,叫diversity training或者别的什么名字,先把bon的水平拉起来?说起来,之前kumar有一篇工作讲的是如何优化bo1,这两个连在一起,是不是就能左脚踩右脚了……