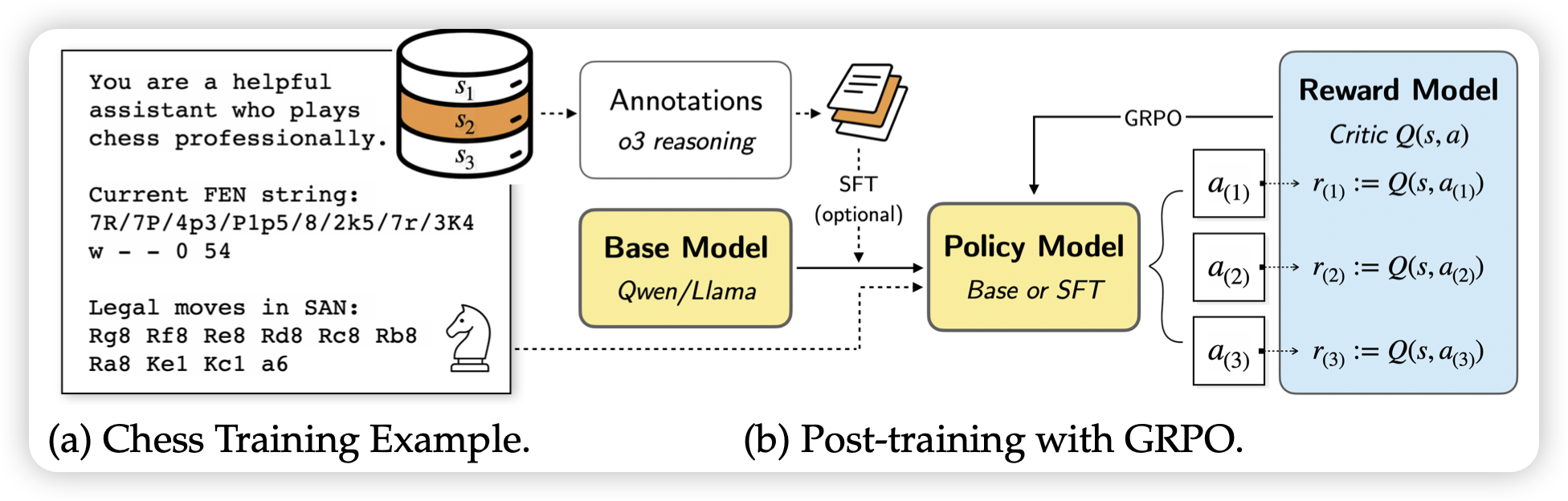
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
zhipu的VLM o1工作,作者提到了很多rl领域的小trick。还额外做了agent场景
这个名字起得好……
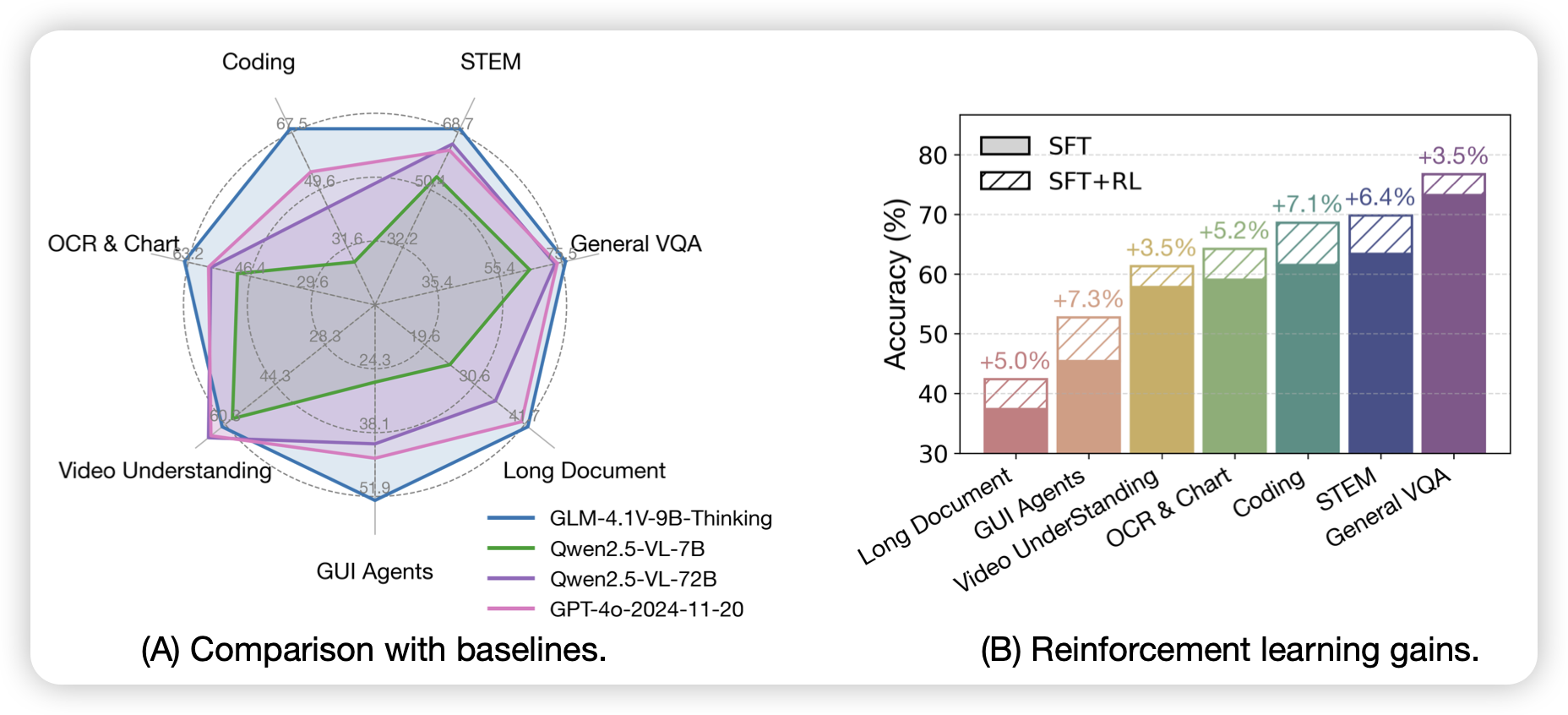
Can Large Language Models Develop Strategic Reasoning? Post-training Insights from Learning Chess
作者在chess场景做了rl,然后甚至用一个state value model去给出更高精度的反馈来提升训练鲁棒性。然而,作者发现模型总是在一个较低的水平收敛,没有发现更深层次的strategy。作者认为这个基模能力带来的,靠rl很难去发现新策略