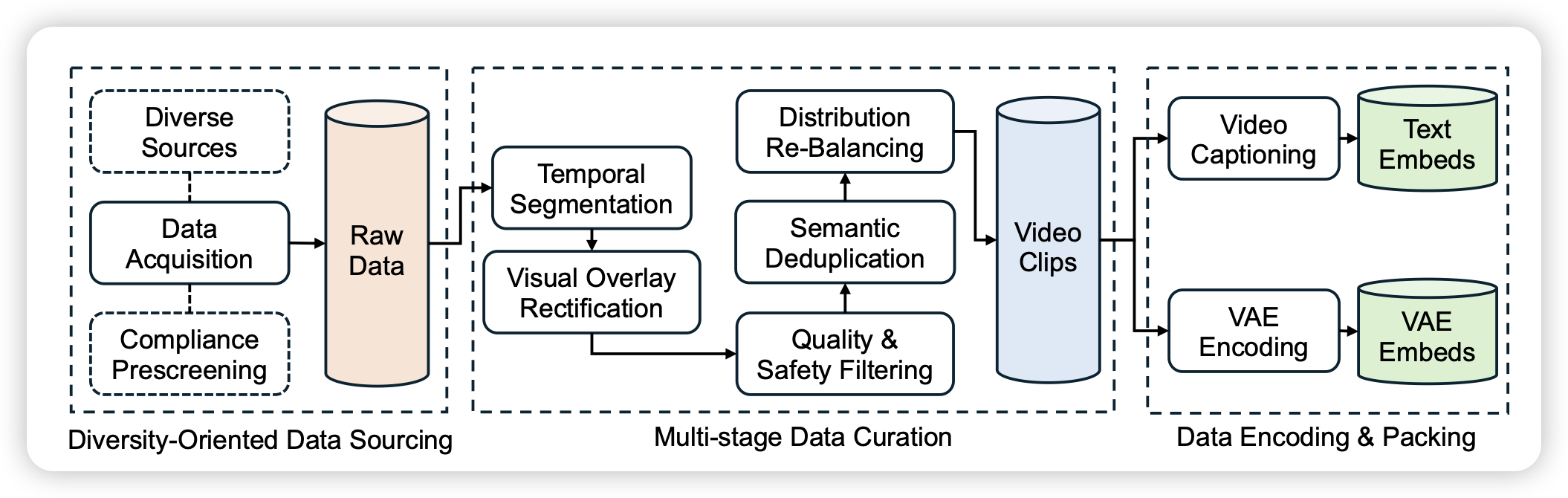
Seedance 1.0: Exploring the Boundaries of Video Generation Models
字节的另一篇视频生成模型的工作。这篇主打的是数据构造链路,真的很多层filter。
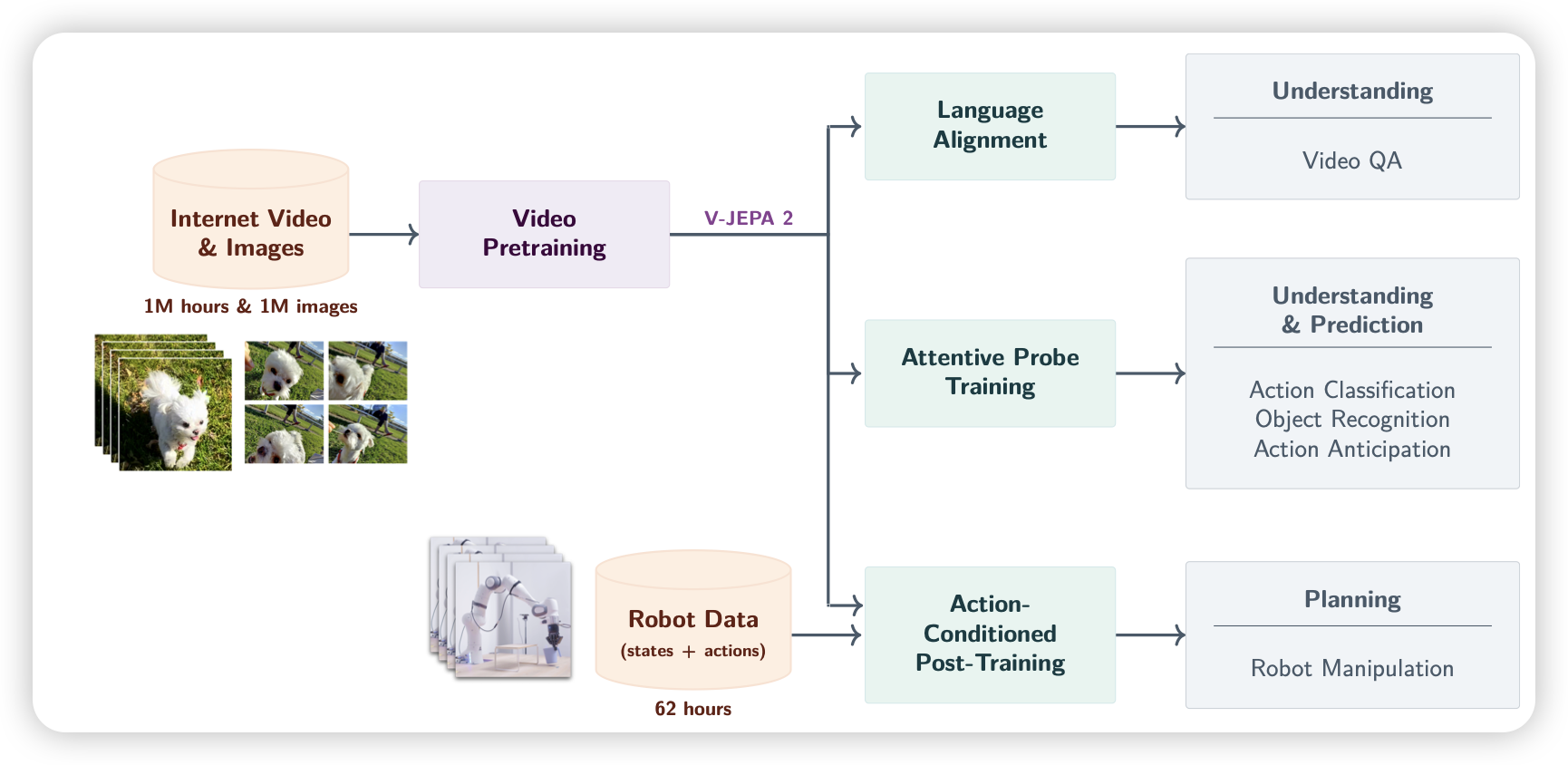
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
lecun又来了,带着他念念不忘的world model。这次看起来正规了很多,除了jepa loss的pretrain以外,作者还做了下游的sft,发现效果不错
最近突然发现公司挺少有做模型结构的组,可能是因为roi不高,lecun算是为数不多的在这方面发力的人了。respect