突然两周没更,只能说,生病了,好了以后摆了一周,以后不会变成 arxiv-weekly了吧……从今天开始每天更新两篇,起码捞回来5篇之前欠下的
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Neubig带队的多模态、多语言模型,作者搞了个6M的SFT数据集,可以说是学界数据全缝了,效果还不错。
缝合怪新王,这下cambrian自愧不如了

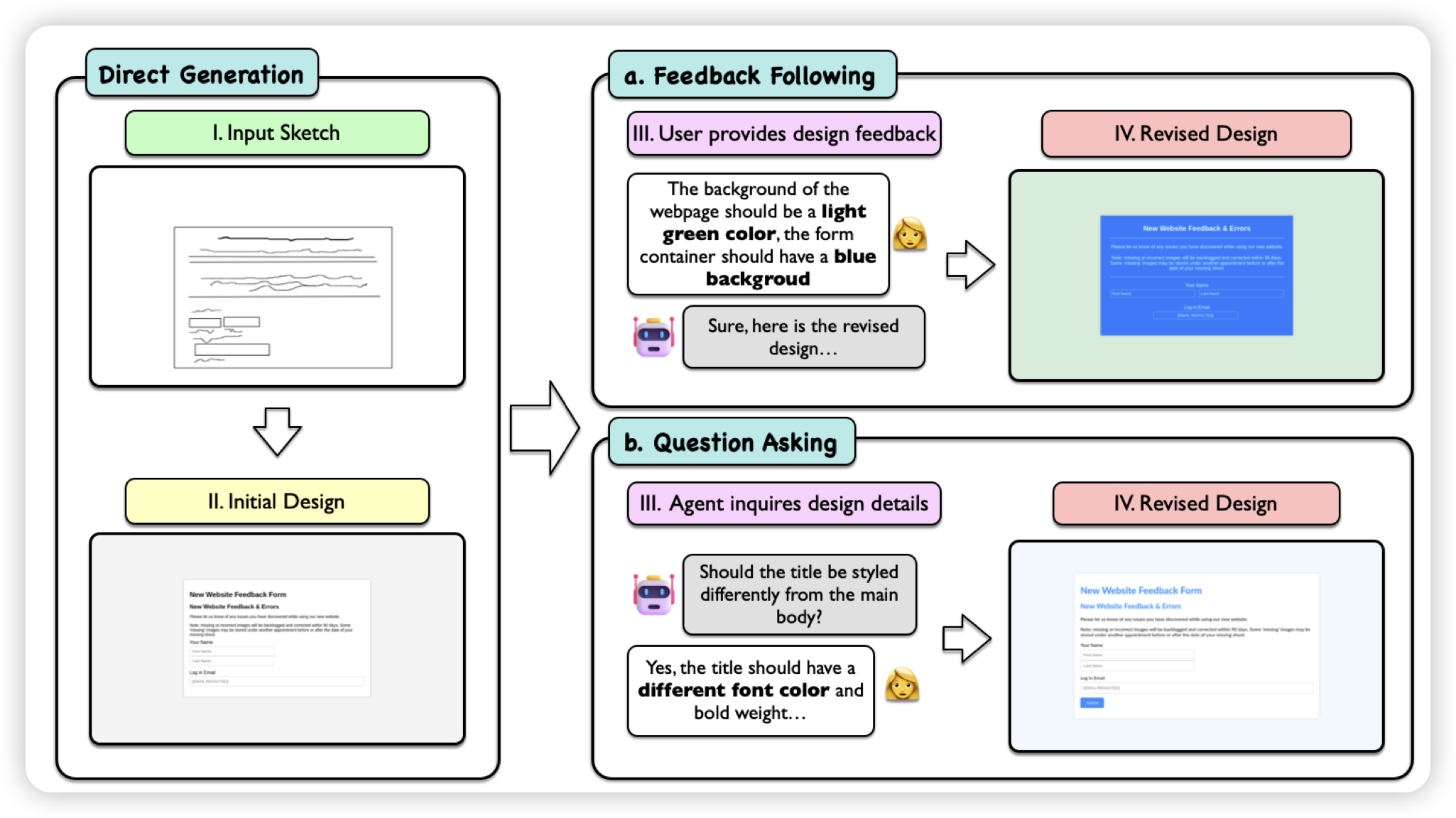
Sketch2Code: Evaluating Vision-Language Models for Interactive Web Design Prototyping
一篇挺好玩的前端生成的benchmark,作者设想了一个交互式的场景:用户最开始提供了一个草图sketch,然后可以在生成过程中持续地提供意见指导,评测最后的效果。作者发现,多轮对话和feedback对于生成好的网页至关重要。
这个领域能不能快点发展,感觉我下轮blog的前端更新就指望这个了
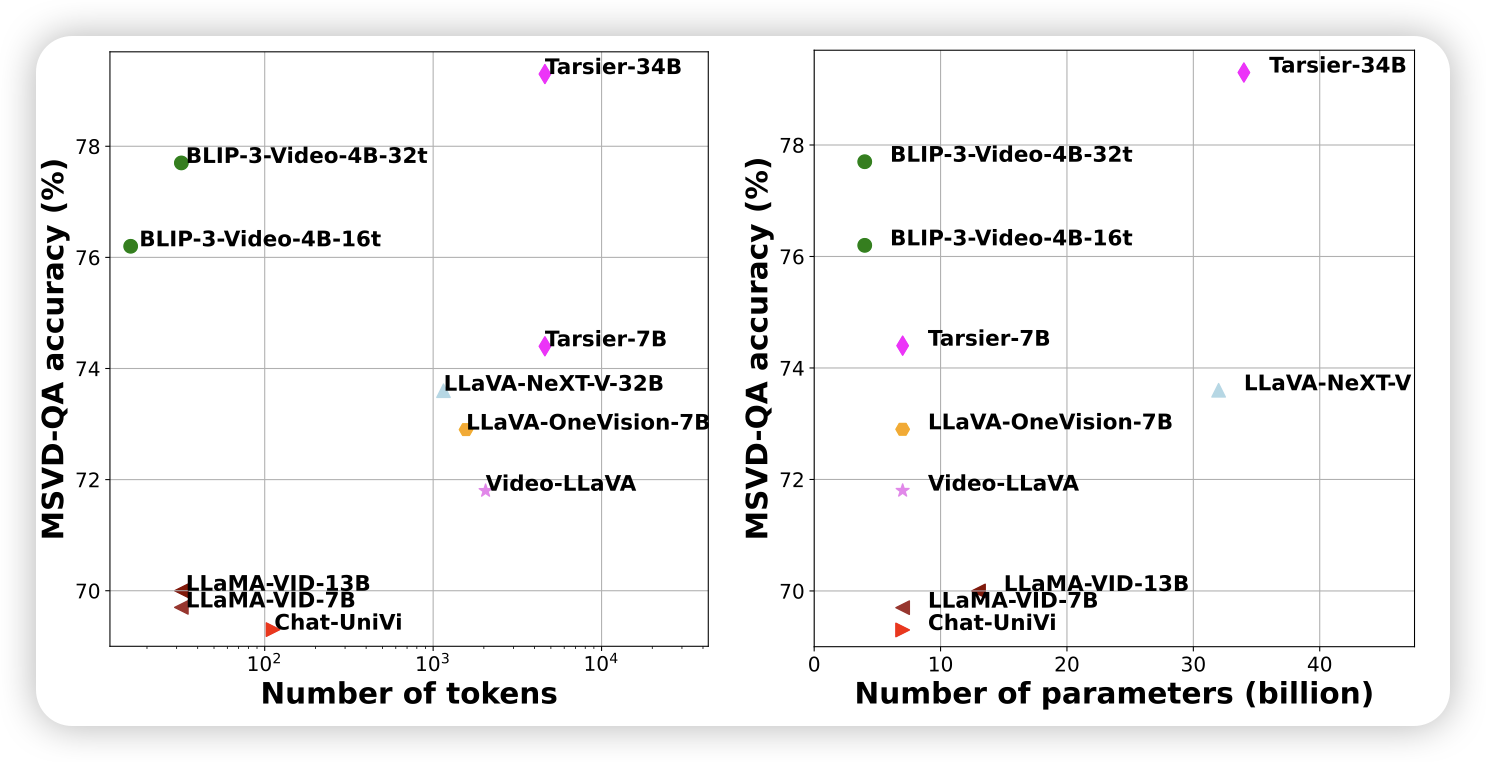
XGEN-MM-VID (BLIP-3-VIDEO): YOU ONLY NEED 32 TOKENS TO REPRESENT A VIDEO EVEN IN VLMS
BLIP系列更新了,这次是video。作者搞了一套image token高效的方案,看起来效率还挺高
所以现在大家仍然没有发现可以真正不掉效果去减少token数量的办法呀