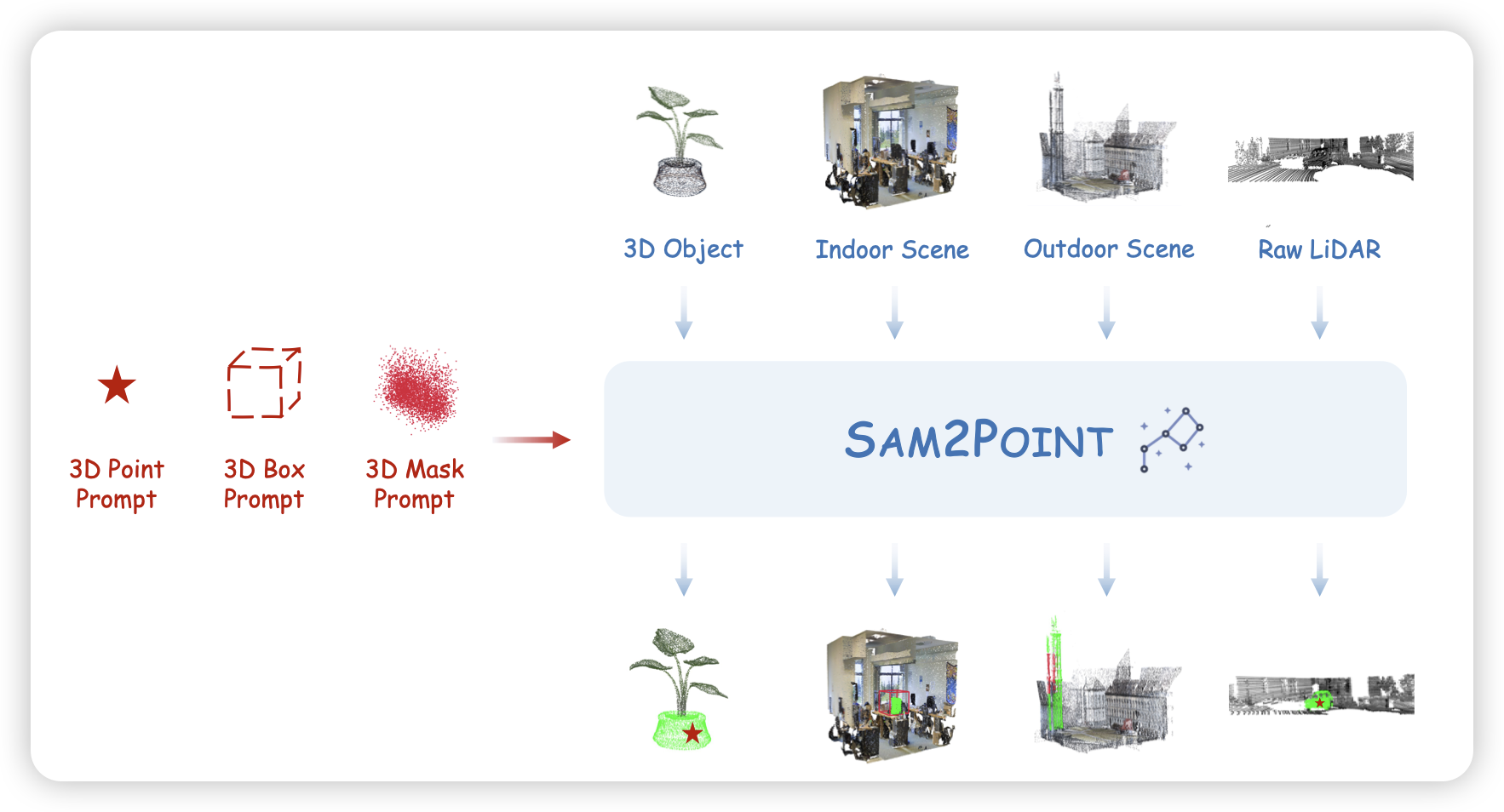
SAM2Point: Segment Any 3D as Videos in Zero-shot and Promptable Manners
作者拓展了sam,把三维空间当成视频多图的样子输入给模型,让模型输出三维的segment,竟然效果还不错?
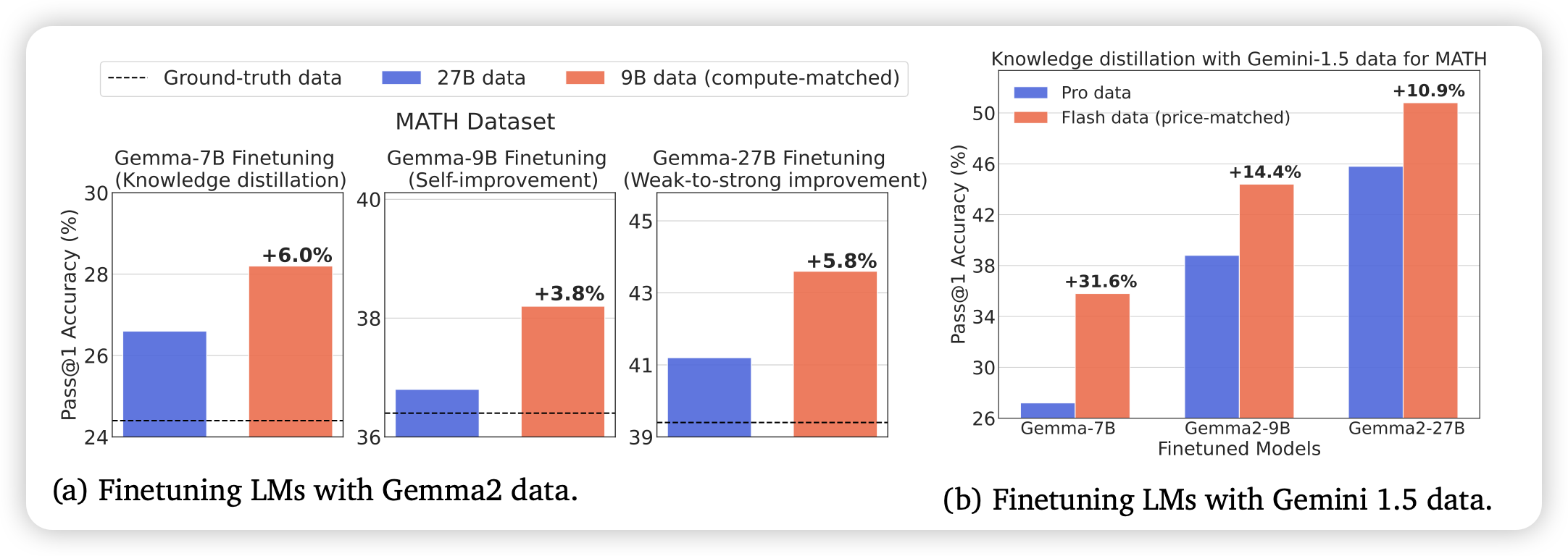
Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
Deepmind的工作:作者探索了一个问题,现在大家都是搞合成数据。但是用什么模型合成呢?大模型的数据质量高但是贵,小模型的数据质量低但是便宜。如果,按照flops公平对比,标注相同flops的合成数据,改用大模型合成还是小模型合成?
作者做了实验,发现无论选取多少flops budget,都是用小模型合成效果更好。