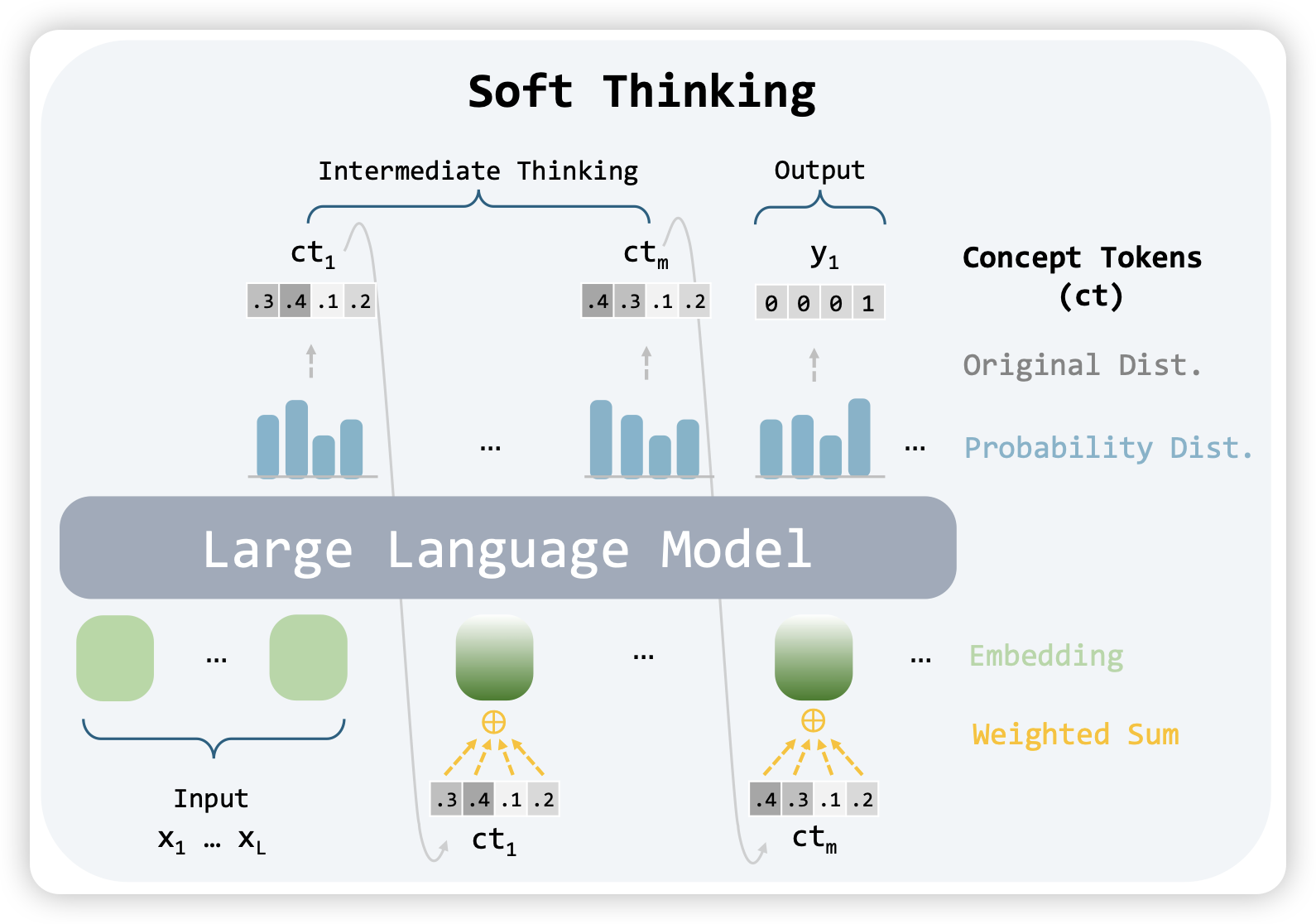
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
一篇soft thinking领域的文章。就是说,在o1-model里,如果输出的不是一个token,而是直接拼一个embedding到下一层的输入(而不是logits最大的token的word embedding),效果会更好吗?直觉上肯定更好,因为没人证明在词表空间里想问题是好事,人大概率思考过程也不是文本,但这个领域就是不work。
这篇工作里,作者想了个怪招:先不一步子迈到直接拼embedding,先试试把概率最大的一些token,根据概率加权后的word embedding拼回去(有点像是在word embedding空间对hidden state做了个奇异值逼进,假设正交的话)。
这是我见过的类似文章里名字起得最好听的,所以我决定以后都叫这个方向soft thinking了。我怀疑这个是AI领域下一个重大突破,下一个怀疑是openAI / SSI 先搞出来……
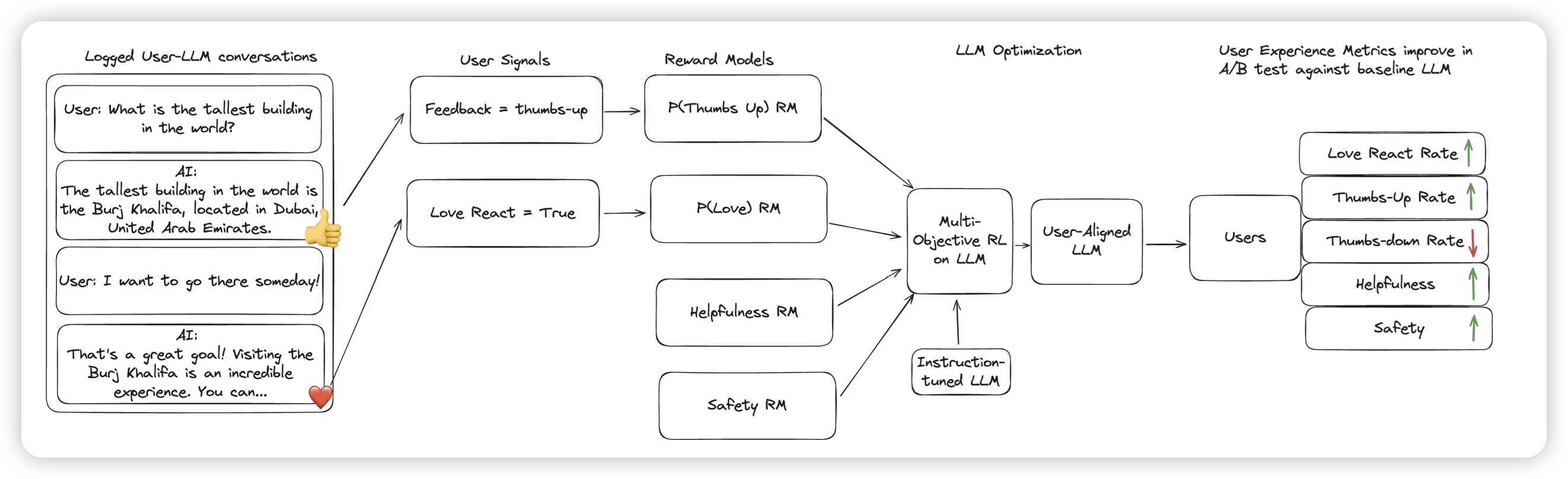
Reinforcement Learning from User Feedback
meta的工作,作者还是研究了那个老问题:能不能从真实世界的多轮对话的user-response里,提取到对模型回复水平的reward?但区别是,作者不在toy setting,而是直接在realworld setting上做。训了一个二元分类器,对用户回复进行分类(作者把好回复叫做love response)。在做了rl以后,在A/B test上,提升了28%的love-response比例。同时,作者发现了一部分的reward hacking现象
字节看了最熟悉的一集……所以,用户是真的可以被hack的吗(如果高兴你就拍拍手?)