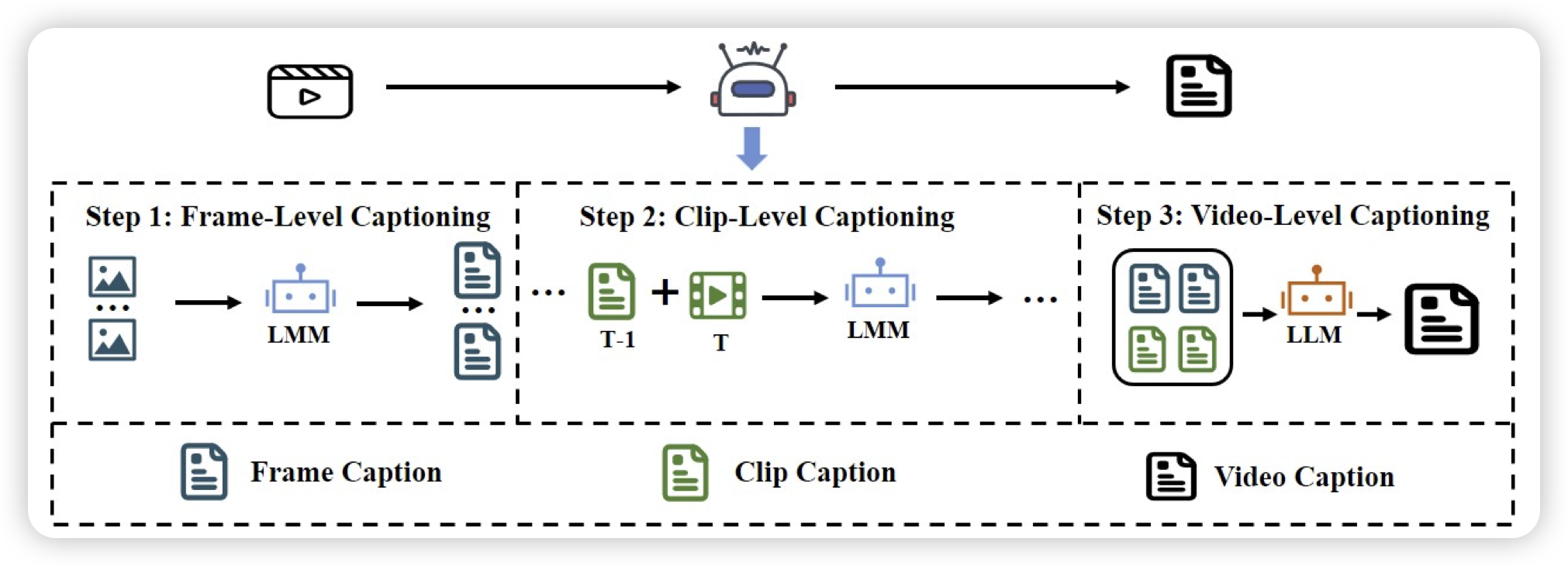
LongCaptioning: Unlocking the Power of Long Caption Generation in Large Multimodal Models
也是一篇做数据的文章,作者瞄准了合成long caption的任务。之前很多VLM的工作已经发现了long caption对于vlm能力提升的重要性,但是好像一直没听说有谁真的开源一个高质量的long caption数据集。作者合成了一波1000token级别的long caption数据,还开源了
我一直挺喜欢long caption这个领域的,很干净。总觉得可以类似于openAI 2018那个summarize领域做rlhf那样,在caption领域做一些学术上的探索,验证一些认知。
GneissWeb: Preparing High Quality Data for LLMs at Scale
IBM出的一篇做数据集的文章,是一个10T token的LLM数据集,作者发现同比例下,训练效果超越fineweb。
开源训练数据👍🏻