DanceGRPO: Unleashing GRPO on Visual Generation
字节做的公式文章,讲的是图片/视频生成场景如何跑起来。作者这里把这个过程建模成多轮,不是生成多个图一步步迭代,而是在去噪/回流的过程中的多轮
Seed1.5-VL Technical Report
我参与的工作,虽然是100作。字节出的多模态o1模型,把tars里面的gui能力都合版进去了。总体写得还是比较开放的。
这下全世界都能看到我在作者列表里压yonghui一头了

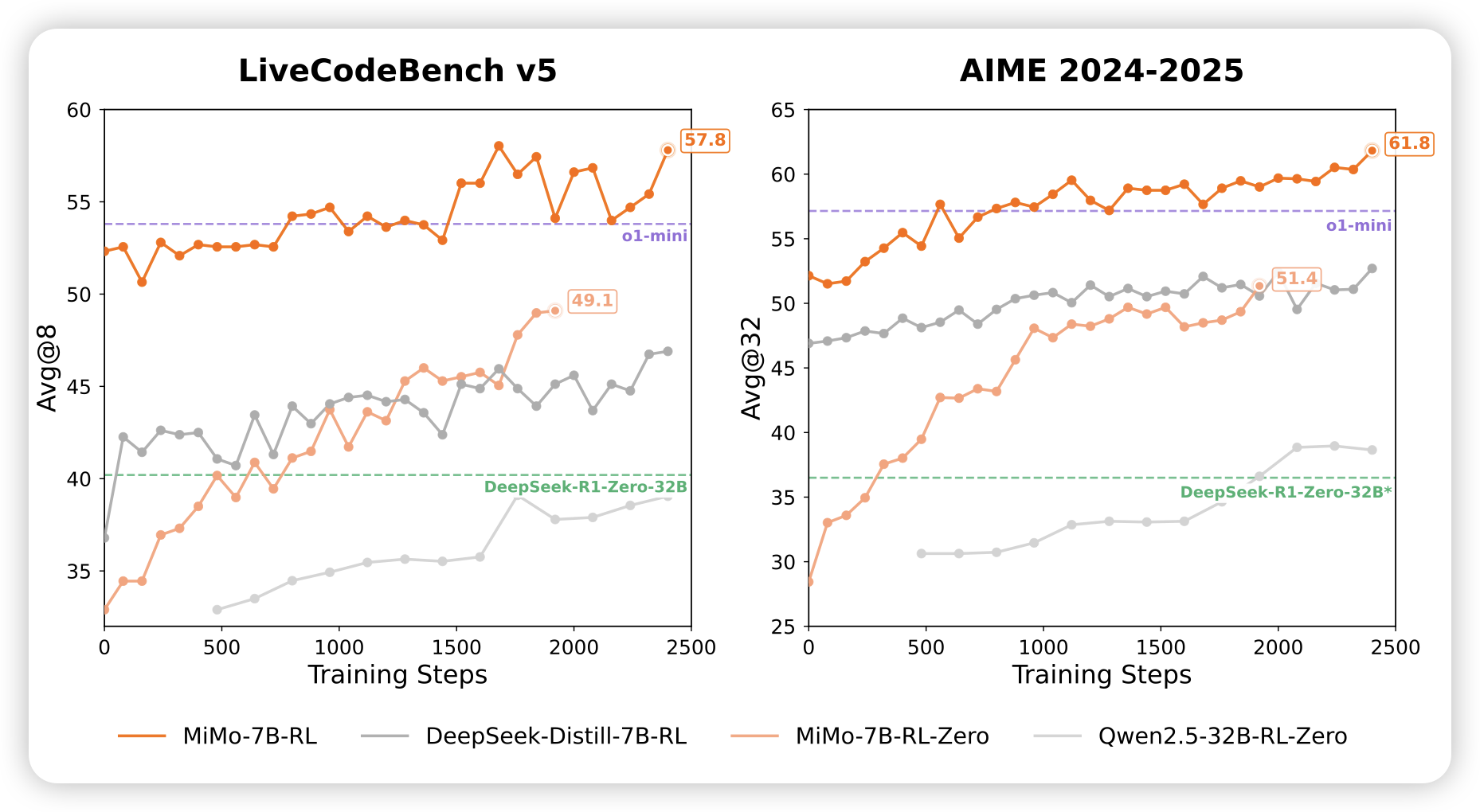
MiMo: Unlocking the Reasoning Potential of Language Model – From Pretraining to Posttraining
小米的工作,竟然是o1 model。通过25TB的预训练,和130k个带答案的code/math rl题库,作者训出来了7B的o1-level reasoning model
千万年薪挖的天才少女发力了?