Training a Generally Curious Agent
这篇工作名字很大,但其实是一个类似于Incontext RL的方向,作者视图合成让模型直接in context里做得更好的数据,并且按照直接的方式训回去。
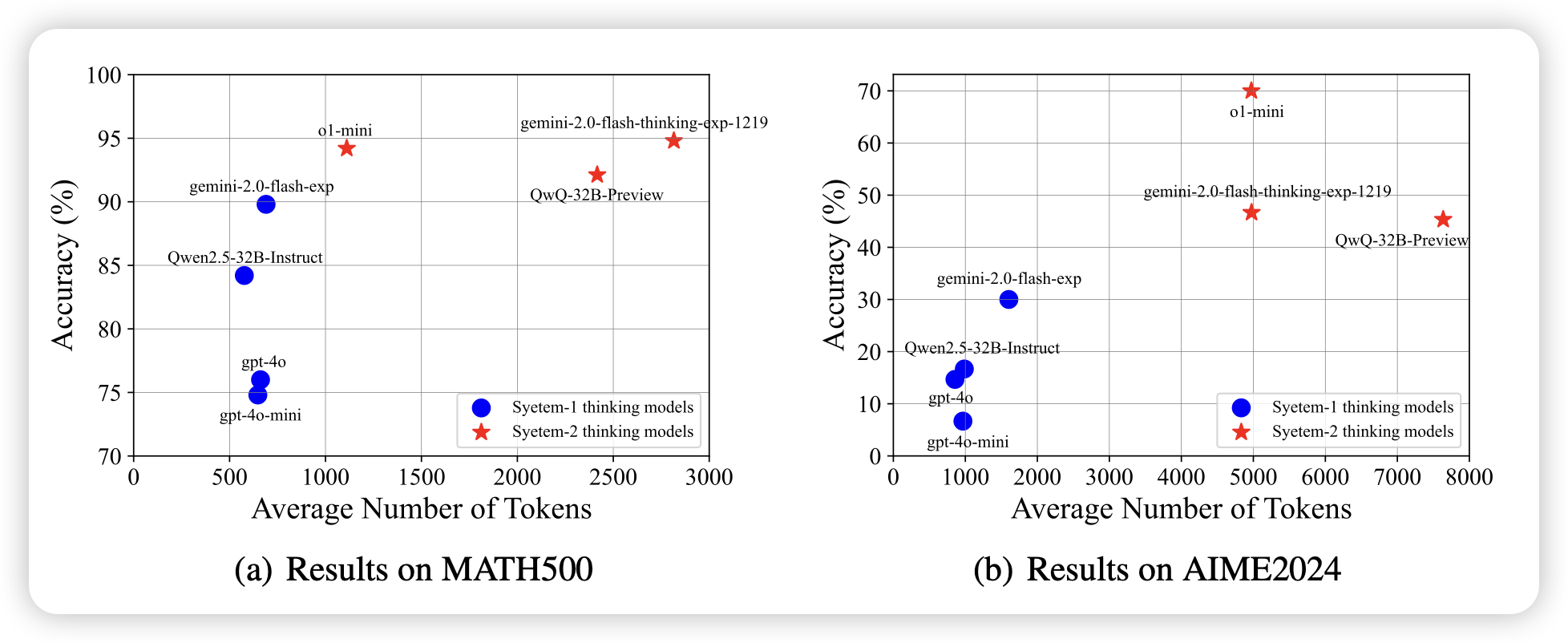
Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
作者发现,在不同的数据集上,其实都有对应的比较好的thought长度区间,在thought超过某个区间后,效果也不会增长了、甚至会下降。所以,如果让模型给每个数据集学着匹配对应的optimal thought length是有价值的。所以,作者用了不同长度的种子数据激发模型在不同数据集上用不同长度的thought去infer,然后把答案正确的数据里面,长度最短的训回去,达到了接近qwq-32B的效果
如果在rl里面对thought加长度惩罚会怎么样呢?
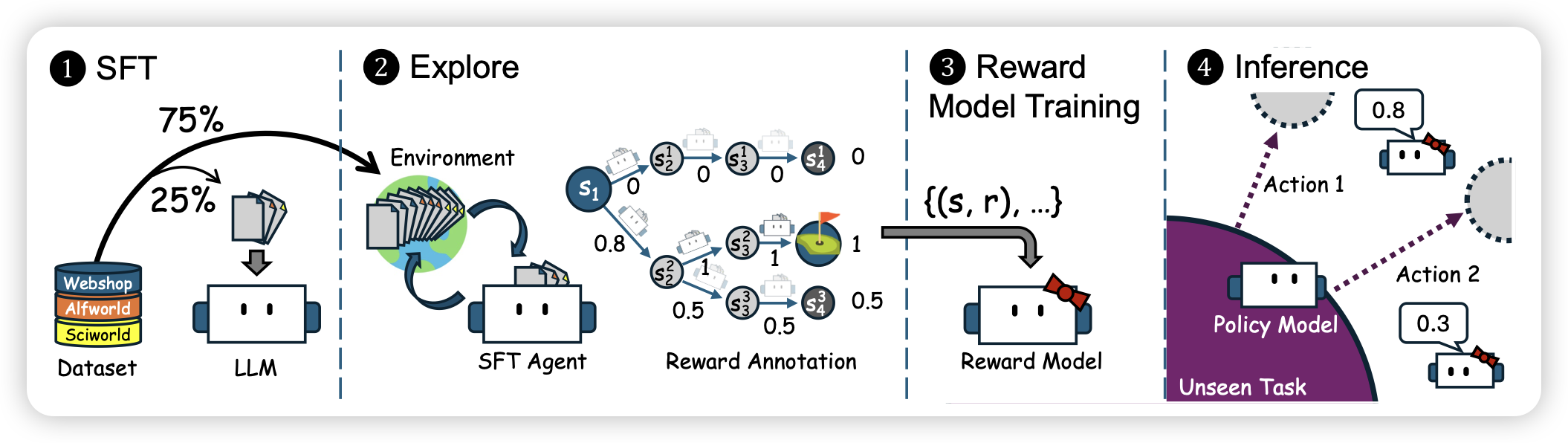
AgentRM: Enhancing Agent Generalization with Reward Modeling
推荐实验室的工作。作者探索了在不同agent任务上,是否可以用同一个reward model对agent trace进行打分,并且探索agent reward model的泛化能力。发现在训练数据scaling到10个场景以后,rm表现出来了跨任务的泛化能力
这个领域是一个非常重要的领域,现在大家都在探索policy model和reward model,谁具有更好的泛化性质。如果reward model泛化更好的话,理论上我们就可以定义generalization语境下的generate-verify gap了