这周论文好像总体都不多,大家是不是开ACL去了兴致缺缺
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs
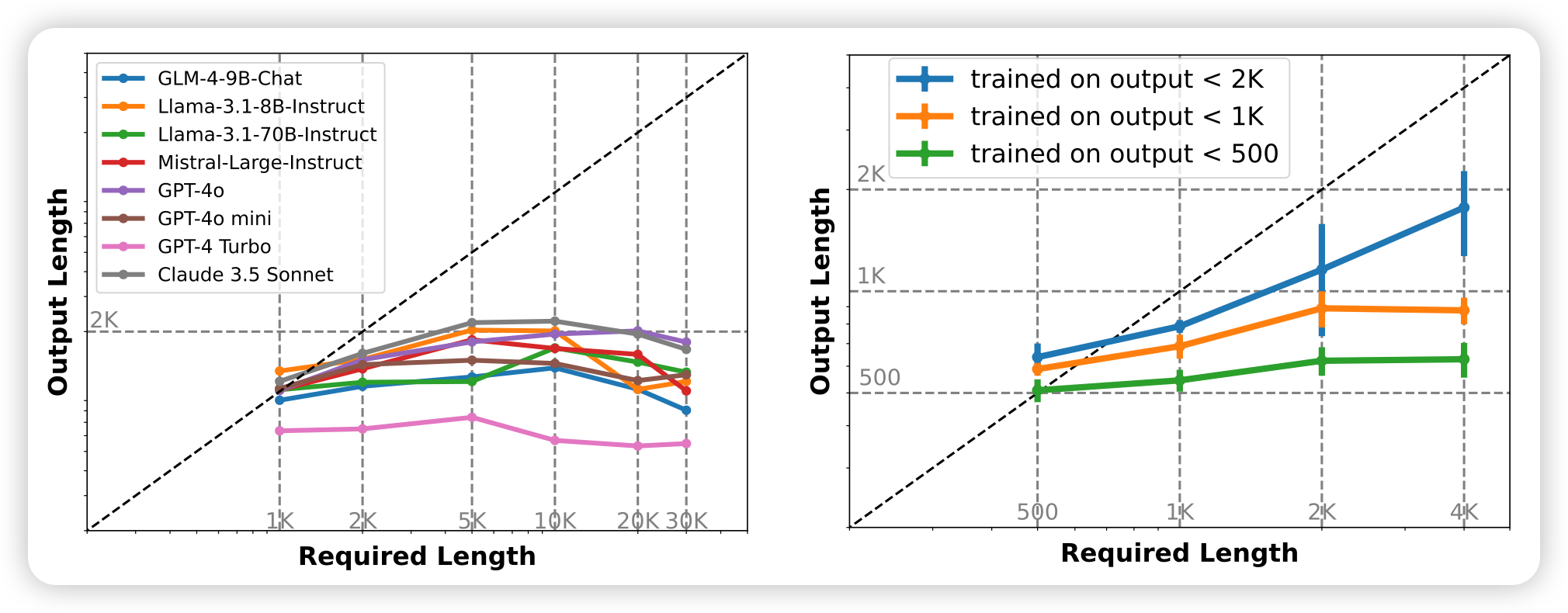
唐杰老师的文章,立足点很好:作者发现目前的模型虽然input length达到了100k,但是输出长度几乎都是最大2k。作者设计了一套agent pipeline,可以把要求长输出的input变成多个subtask,然后合成出来很长的输出数据。作者用这个方法构造了6000条输出的SFT数据,让模型学会了输出10000 token的能力
这个问题,似乎几年前叫做explosure bias。现在好像没人提了……