今天足足有169篇工作,昨天是劳工节放假,所以今天是 放假 + 周二的联合
Pre-Training Multimodal Hallucination Detectors with Corrupted Grounding Data
Scale AI的工作,有趣的思路:作者认为,已有的幻觉检测方法大多是paragraph-level,说出来一整段有没有幻觉,作者想要在span-level做检测。所以作者反向构造数据:先找到一个对的数据,在所有grounding位置让LLM给出流畅的paraphrase,然后替换变成负样本。
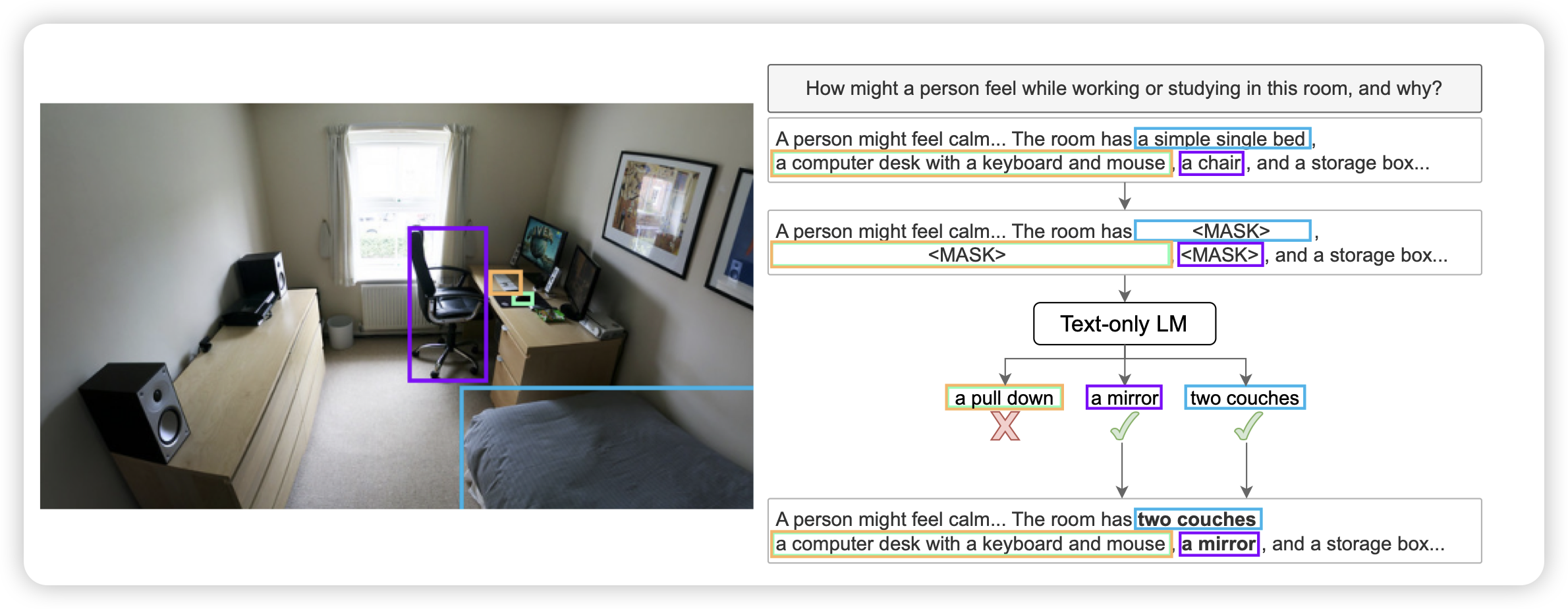
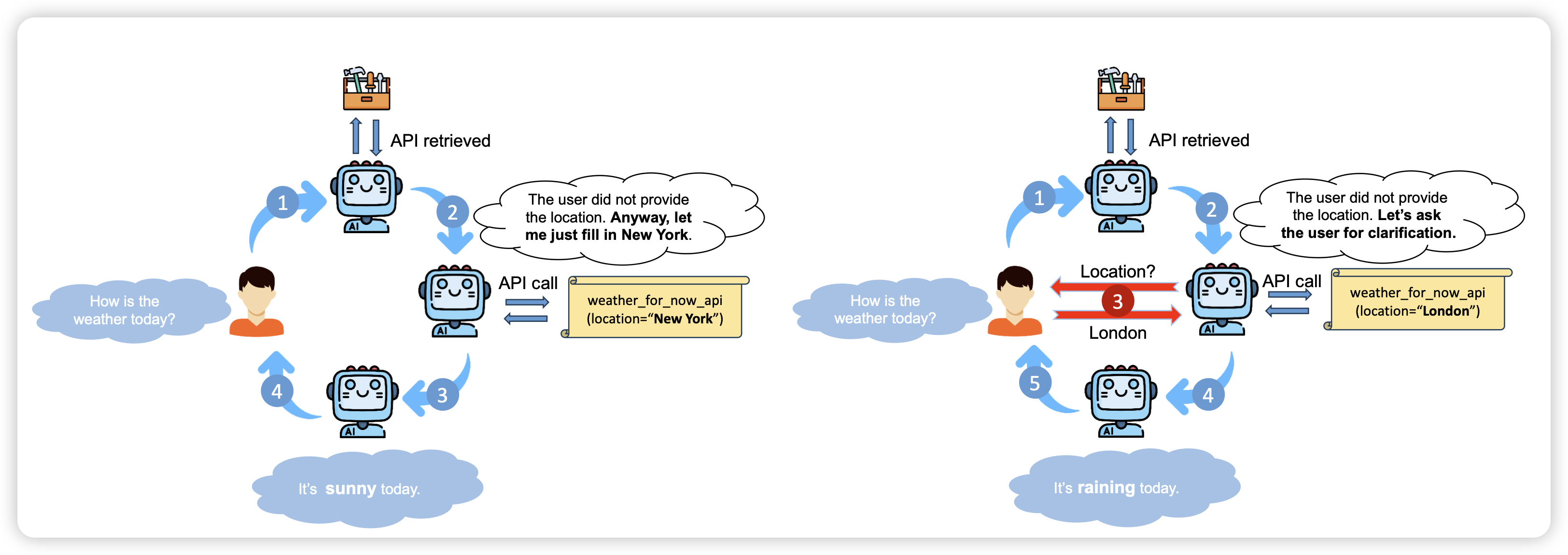
Learning to Ask: When LLMs Meet Unclear Instruction
挺有趣的工作,作者认为:在真实场景中,用户的instruction往往有歧义、或者不明确,模型应该正确地发现歧义,或者主动在任务进程中问用户相关的信息。作者探索了在tool场景中模型能否获得这个能力
有点像组里师弟做的"tell me more",今年的ACL工作
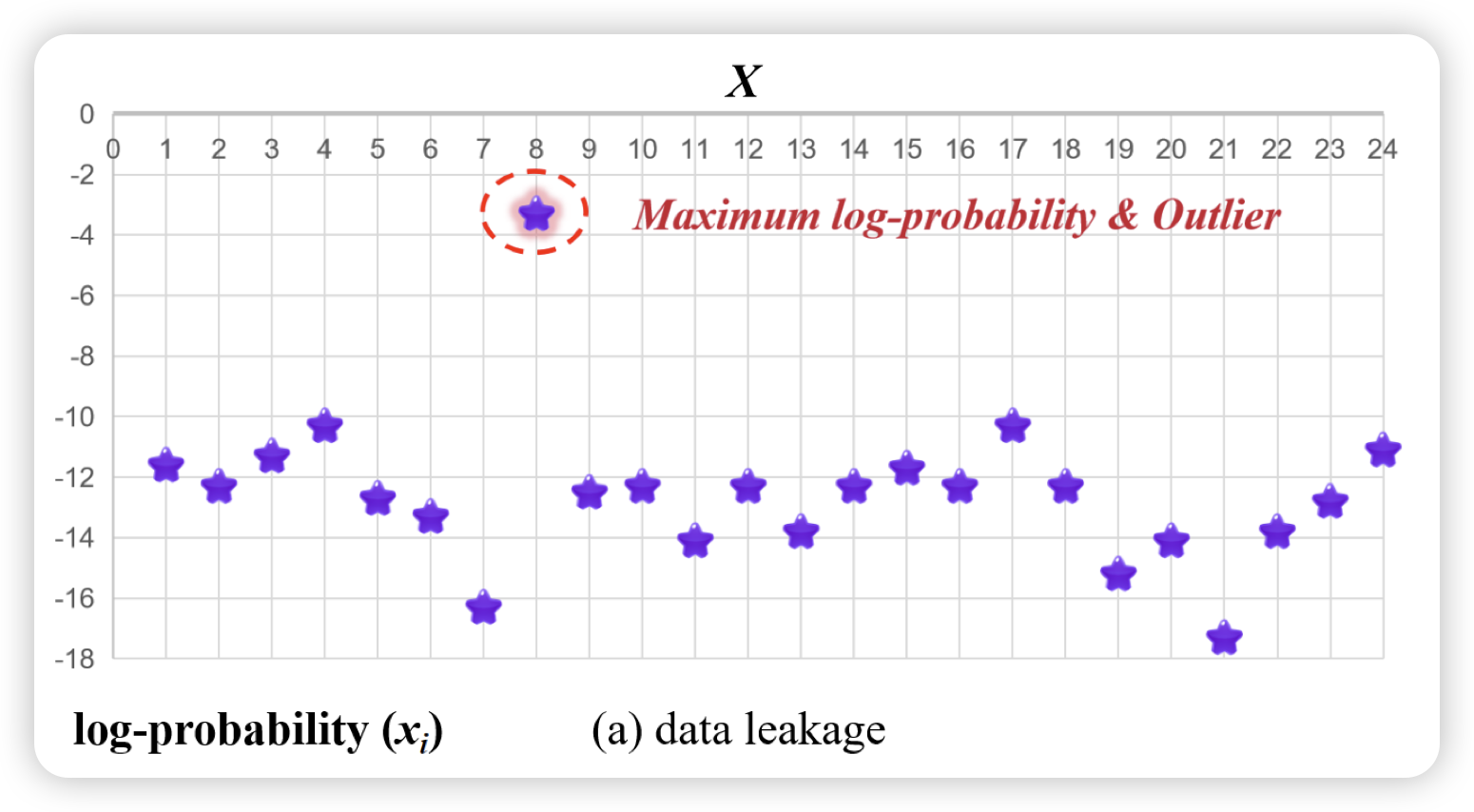
Training on the Benchmark Is Not All You Need
一篇检测各大公司是否把benchmark数据偷偷训进去的工作,作者的思路挺简单:瞄准多选题场景。作者觉得,如果没训进去,那选项不管怎么排布都应该概率一样。所以作者把n个选项生成了n!个变体,所有选项顺序打乱,观察模型的ppl,如果原始题目顺序的ppl是所有变体里最低的,那么就会危险。作者用这个方法观察了32个LLM,发现qwen系列的表现最为反常
只能说……难说
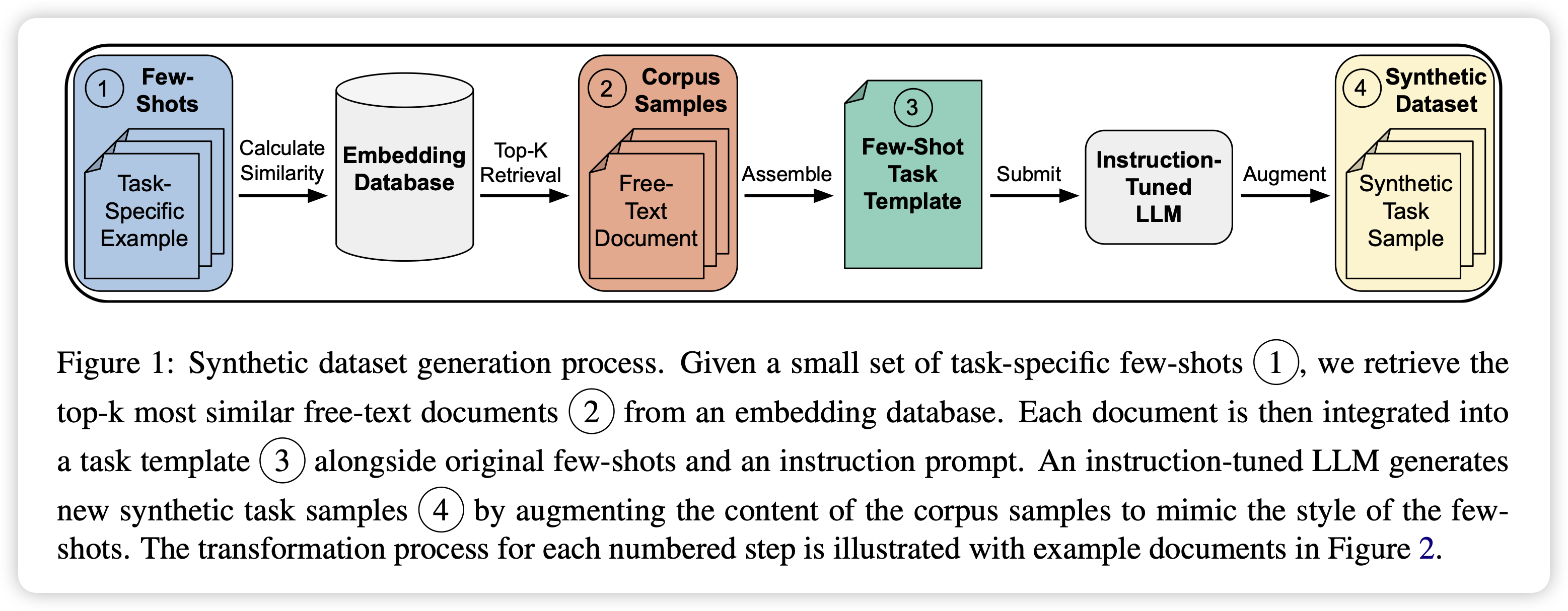
CRAFT Your Dataset: Task-Specific Synthetic Dataset Generation Through Corpus Retrieval and Augmentation
这篇工作有点像是mammoth2从预训练数据集中自底向上合成数据,但又不完全是:他是先找一个task,根据这个task找到最接近的free-text,然后让一个模型过来refine。所以没有最前面的fastext环节
如果一定要找的话,我觉得最像的是neubig在扩展instruction tuning数据方面的一个工作Better Synthetic Data by Retrieving and Transforming Existing Datasets……如果大家还记得我四月份推过这篇的话