现在刷俩track以后……周二竟然有500篇了???
AutoGLM: Autonomous Foundation Agents for GUIs
前两天刚出一个Android-Lab,今天唐杰老师又搞了个模型的工作AutoGLM。总体的观感有点像上半年的AutoWebBench工作,延拓了一些安卓场景。claude一出,GUI Agent方向又火起来了呀
这个把前几天那个公众号pr稿翻译成论文了吗……
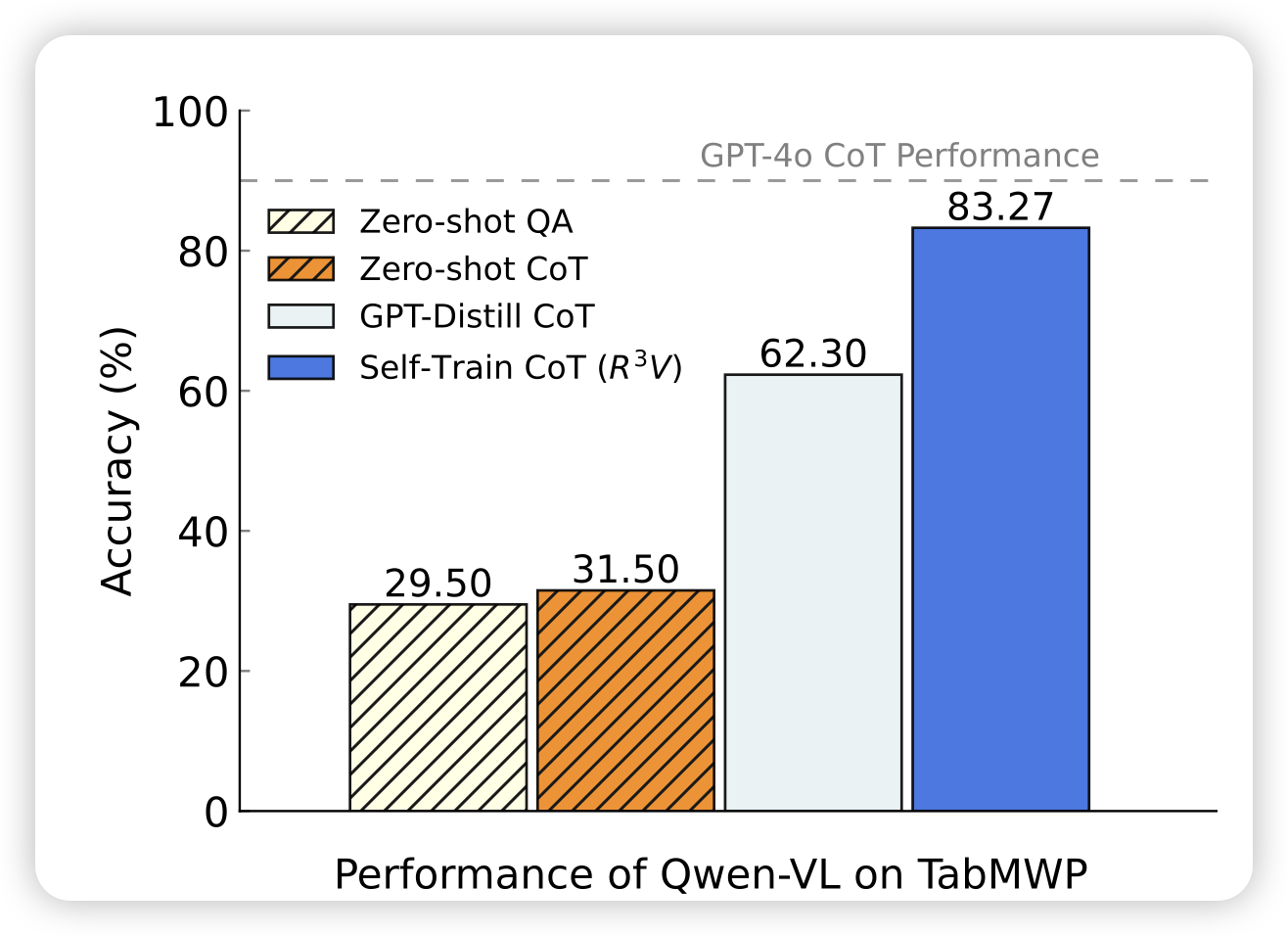
Vision-Language Models Can Self-Improve Reasoning via Reflection
刘洋老师的工作,目标是VLM中的self-reflection。这个领域火了一年了,但是好像一直没人能真搞出来的。作者这次提的方案是让模型生成一大堆cot,然后互相比较,去写一个更好的,再把这一大堆测试时计算塌缩成一个dual-cot-trace. 发现效果还挺好的
之前kumar有一篇training models to self-correct,感觉和这篇是两个方法论,不知道谁的更合理一些……
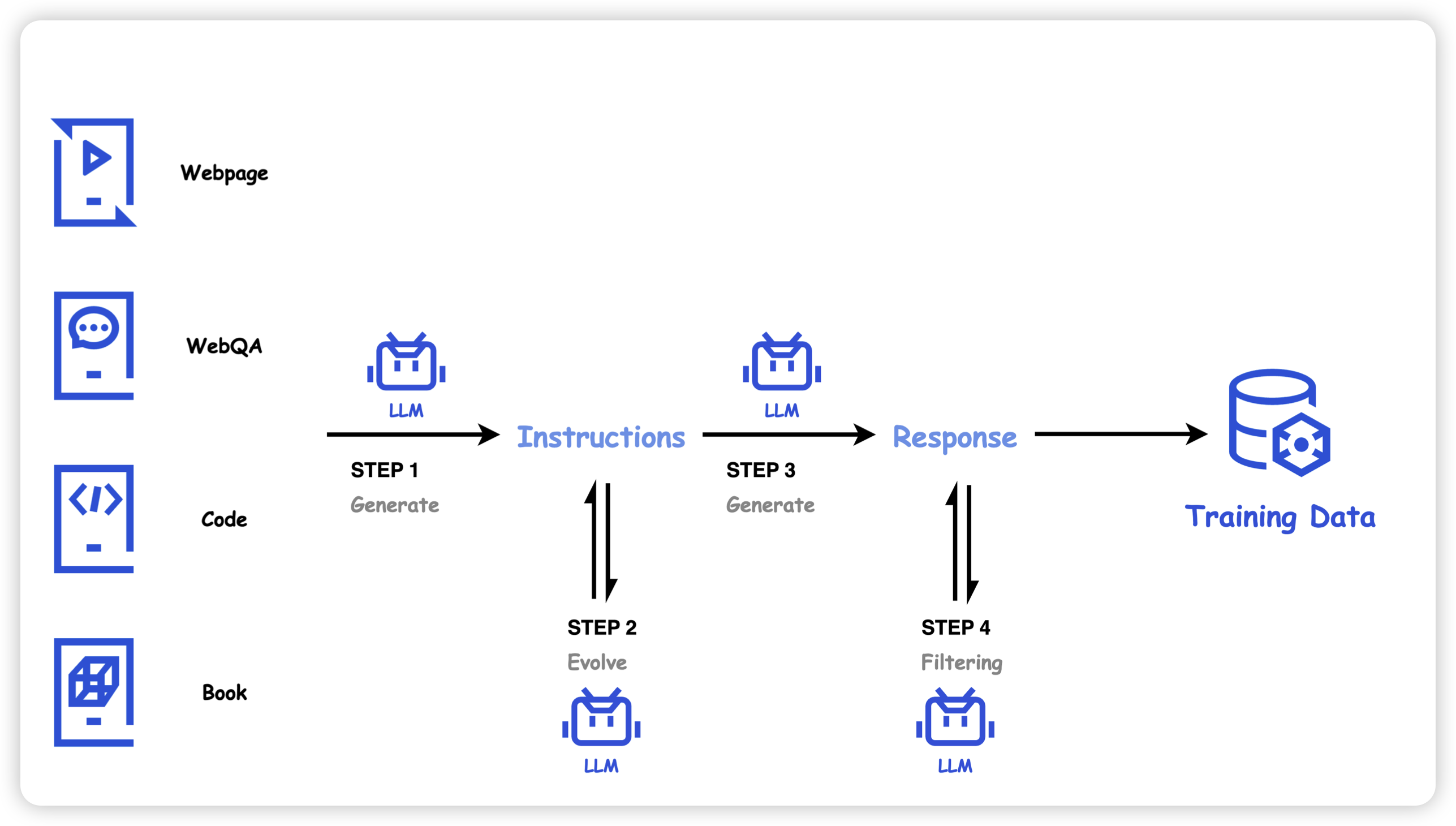
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation
混元MoE的技术报告,激活参数就有52B。讲真的,这真挺大的。作者讲到,这个模型和之前的主要区别是,合成数据的占比更大,大一个数量级。
另外,除了LLM,还在cv track偷跑了一个text-to-3D模型,他是真关心游戏场景的公司。
想起来之前tencent搞过一个personal-hub,绝对的合成数据大队。

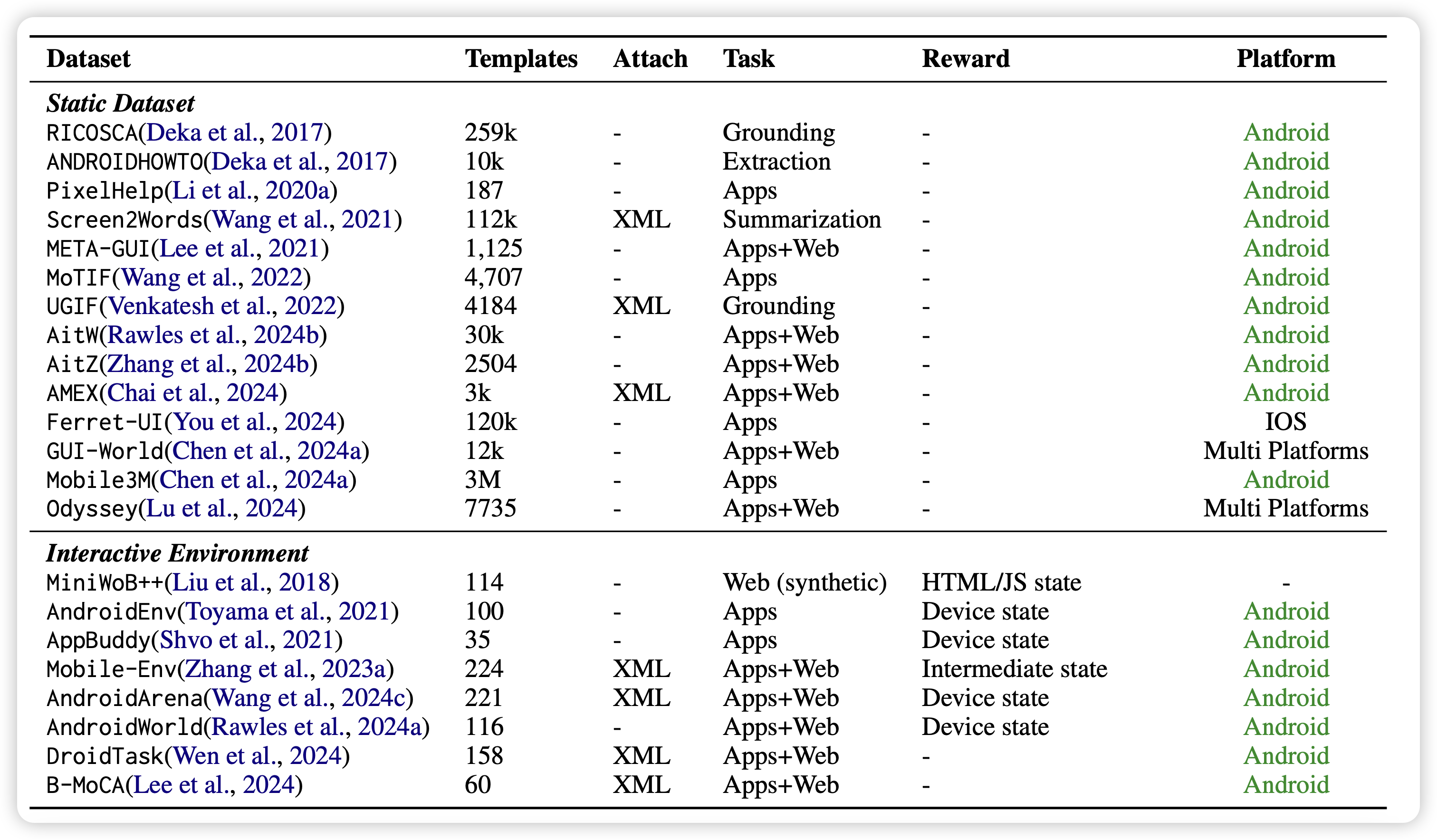
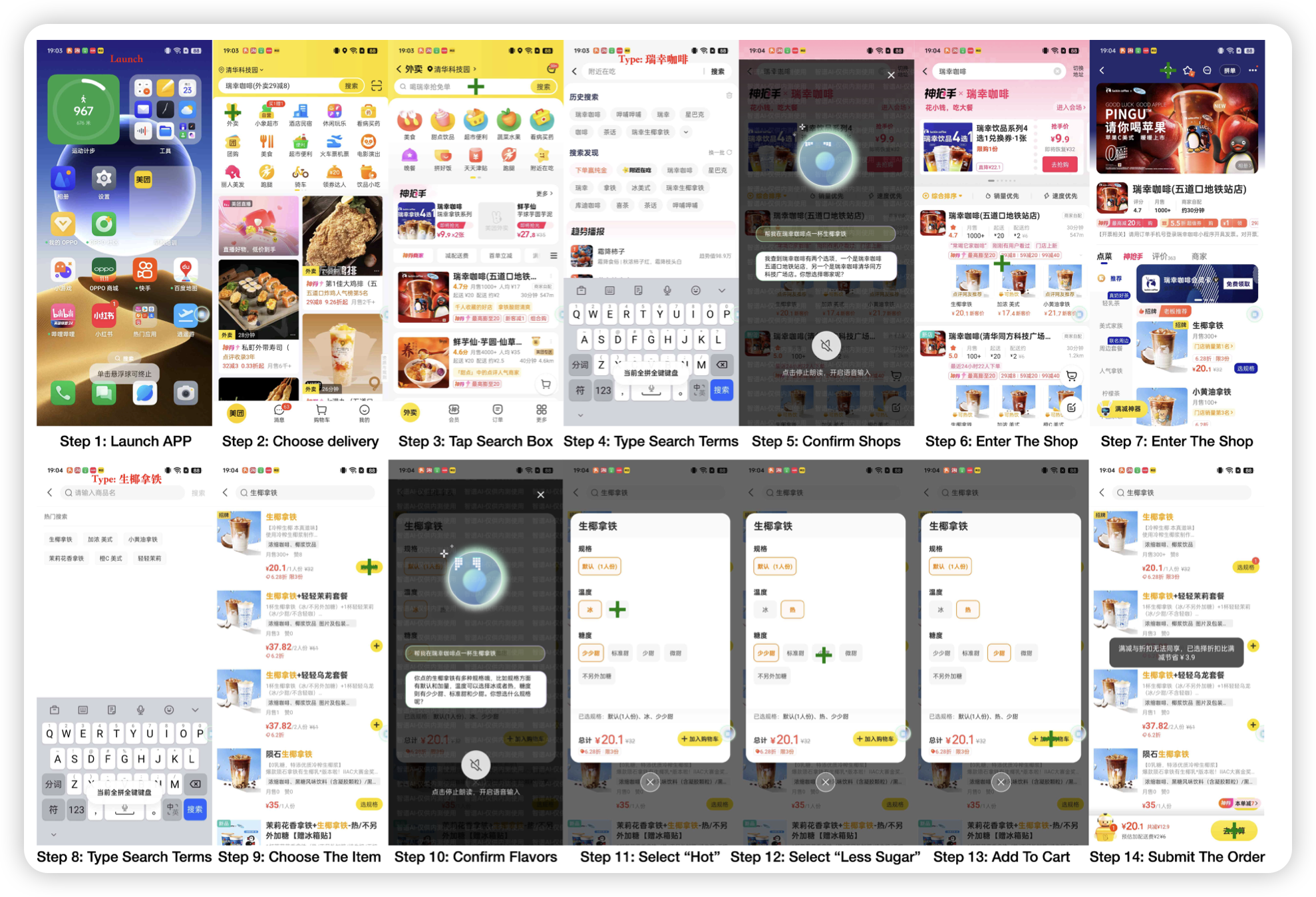
Foundations and Recent Trends in Multimodal Mobile Agents: A Survey
如标题,一篇survey,整理最近对于model agent领域的各种工作,对比了训练数据等问题。想了解GUI Agent的话,这篇工作还挺好的